
Table of Contents
Along with industrialization thriving, the severe impact on the natural environment, society, and international economy resulting from global-scale extreme climate changes gradually became the focus of national attention, such as ENSO(El Niño Southern Oscillation), rising sea-level, air pollution, etc. These impacts led nations to ponder how to co-exist with mother nature, and therefore, in 2005, the UN proposed “environment,” “social,” and “governance,” which are so-called “ESG,” should be included in cooperation’s evaluation. The UN expected that doing so would positively affect society, the market, and individuals. Simultaneously, cooperations had to consider how to maintain revenue growth and achieve sustainable development under the unpredictable commercial environment.
However, countless pieces of information appear in the market every day; it is difficult for an individual to know and understand all of them.
Today we will use the “TESG Event Radar” data to fulfill topic modeling, which can help us easily and quickly understand the ESG trends or topics of open data of the government, shareholders meeting report, and ESG report.
Generally, a text consists of multiple topics, the portion of each topic is different, and the frequency of occurrence of each keyword is also different. Topic modeling can analyze the words in the text, counting the distribution of possibility of which topic the text belongs to.
LDA (Latent Dirichlet Allocation) is an unsupervised topic model which is a normalized PLSI (Probabilistic latent semantic analysis) used for collecting, classifying, and dimension reduction in text.
This article uses Mac OS as a system and Jupyter as an editor.
import tejapi
# 前處理套件
import pandas as pd
import re
import numpy as np
from datetime import datetime
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
# 模型套件
from numba import jit, cuda
import gensim
from gensim import corpora, models
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
# 視覺化套件
import matplotlib
import matplotlib.pyplot as plt
import pyLDAvis.gensim_models
from wordcloud import WordCloud
# 輔助套件
import warnings
warnings.filterwarnings("ignore")
tejapi.ApiConfig.api_key = "Your Key"
tejapi.ApiConfig.ignoretz = True
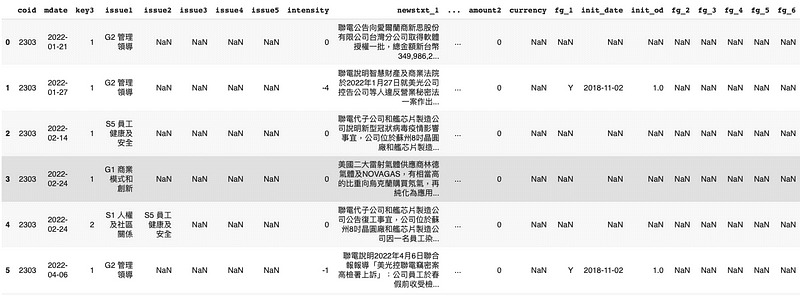
TESG Event Radar (TWN/AEWATCHA)
For the period from 2022–01–01 to 2023–04–01, we take TSMC(2330) as an example.
stock_id = '2330', '2303', '2881', '3045'
gte, lte = '2022-01-01', '2023-04-01'
TESG = tejapi.get('TWN/AEWATCHA',
paginate = True,
coid = stock_id,
mdate = {'gte':gte, 'lte':lte},
)
df = TESG
df["mdate"] = pd.to_datetime(df["mdate"])
We will use “ckip_transformers, ” the NLP package which Academia Sinica develops for Mandarin tokenization, POS tagging, and NER, the reason is unlike “jieba” or “snowNLP,” the packages designed by China, the tokenization result of “ckip_transformers” is much more fit Taiwanese pattern.
# Initialize drivers
print("Initializing drivers ... WS")
# device=0 為使用gpu進行運算,如電腦無gpu者可改為 device=-1 用cpu運算
ws_driver = CkipWordSegmenter(model="albert-base", device=0)
print("Initializing drivers ... POS")
pos_driver = CkipPosTagger(model="bert-base", device=0)
print("Initializing drivers ... NER")
The next step will be word segmentation and part-of-speech tagging. We use the “lambda” function to process each piece of data. Its advantage is high efficiency and simple code. Compared with the “for” loop, it can complete much data processing faster.
df["seg"] = list(map(lambda x: ws_driver([x]), list(df["newstxt_1"])))
df["seg"] = df["seg"].apply(lambda x : x[0])
df["pos"] = df["seg"].apply(lambda x : pos_driver(x))

From the above figure, we can see that a single word may have multiple parts of speech after part-of-speech tagging. For most languages, the meaning of sentences mainly concentrates on nouns and verbs. Therefore, in the next step, we need to filter out noun or verb words and put the result into a new column “N_or_V.”
# 詞性過濾
def fltr_nv(word_lst, pos_lst):
lst = []
for word, pos in zip(word_lst, pos_lst):
for i in pos:
if i.startswith(("N", "V")):
lst.append(word)
break
return lst
df["N_or_V"] = df.apply(lambda x : fltr_nv(x["seg"], x["pos"]), axis = 1)
Let’s check the time distribution of data by month.
# 計算每月文章數
gb_corp = df_corp[["mdate", "N_or_V"]].groupby([df.mdate.dt.year, df.mdate.dt.month])
a = 0
lst = []
for group_key, group_value in gb_corp:
group = gb_corp.get_group(group_key)
dct = {
"month" : datetime.strptime(str(group['mdate'].iloc[0])[:7], "%Y-%m"),
"key_word" : [i for i in group['N_or_V']]
}
lst.append(dct)
print(f"{group_key} : {len(group)}")
a+=len(group)
print(a)

We can see through the word cloud that although we did not use TF-IDF, Rext Rank, and other keyword extraction methods, the results obtained by only part-of-speech screening seem okay.
!wget https://raw.githubusercontent.com/victorgau/wordcloud/master/SourceHanSansTW-Regular.otf -o /dev/null
%matplotlib inline
# 從 Google 下載的中文字型
font = 'SourceHanSansTW-Regular.otf'
df_keyword = pd.DataFrame(lst)
df_keyword["key_word"] = df_keyword["key_word"].apply(lambda x : " ".join(x[0]))
df_keyword["pic"] = df_keyword["key_word"].apply(lambda x : WordCloud(font_path=font, max_words = 20, background_color = "white").generate(x))
plt.imshow(df_keyword["pic"].iloc[10])
plt.axis("off")
plt.show()

We use the gensim package to build the LDA model. The first step is to create a dictionary and give each word in the dictionary a corresponding number, and then calculate the number of times each number (word) appears in all articles.
# 將過濾後的單詞轉換為轉換為list of list形式
seg_lst = list(df_corp["N_or_V"])
# corpora.Dictionary() input 是文字的 list of list
dictionary = corpora.Dictionary(seg_lst)
# corpus為 (編號:出現字數) 的 list of list
corpus = [dictionary.doc2bow(i) for i in seg_lst]
The next step is to build a model but we encounter a problem. Since the LDA topic classification needs to be given the number of topics in advance, what is the most appropriate number of topics?
Here we use Log Perplexity and Topic Coherence to measure the number of topics.
Log Perplexity reflects the level of “uncertainty” in the model’s prediction results, that is, for an article, how uncertain we are that it belongs to a particular topic, so the more topics there are, the less perplexity. Still, it should be noted that when the number of topics is large, the generated model tends to overfit, so it is not possible to evaluate a model solely by perplexity.
In contrast, Topic Coherence measures the semantic similarity between high-score words in topics. These measurements help to distinguish semantically explainable topics from topics based on statistics theories. The higher the score, the lower the consistency between topics. In general, the Coherence score increases with the number of topics. As the number of topics increases, the Coherence score increases diminishingly. At this time, the elbow technique (elbow method) is often used to make a trade-off between the number of topics and the coherence score.
Why these two methods can help us determine the number of topics, we won’t go into detail here. The only concept needed at present is that the lower the Log Perplexity, the better the classification effect, and the higher the Topic Coherence, the better the classification effect.
Remind that there is no guideline for where Perplexity and Coherence should fall. The scores we get, and their values depend on the data they are calculated on. For example, a score of 0.5 might be good enough in one situation but unacceptable in another. The
The only rule is to minimize the Perplexity score and maximize the Coherence score.
# 困惑度計算
def perplexity(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes = 30)
print(ldamodel.print_topics(num_topics = num_topics, num_words = 15))
print(ldamodel.log_perplexity(corpus))
return ldamodel.log_perplexity(corpus)
# 主題一致性計算
def coherence(num_topics):
ldamodel = LdaModel(corpus, num_topics = num_topics, id2word = dictionary, passes = 30, random_state = 42)
print(ldamodel.print_topics(num_topics = num_topics, num_words = 15))
ldacm = CoherenceModel(model = ldamodel, texts = seg_lst, dictionary = dictionary, coherence="c_v")
print(ldacm.get_coherence())
return ldacm.get_coherence()
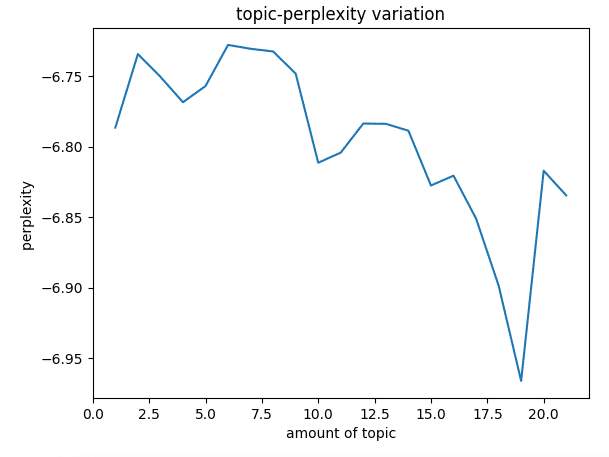
From the above figure, we can find that Log Perplexity will drop sharply after nine topics, which implies that the model may be overfitting at ten, so the number of topics we choose should be less than 10, so the scale of the number of topics we input into Topic Coherence will be 1 ~ 9.
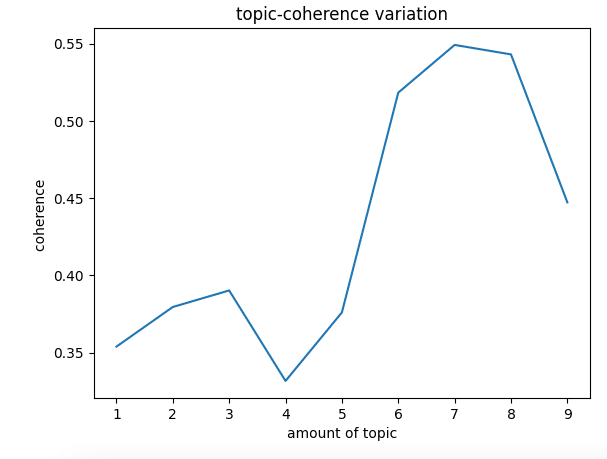
The results show that the classification model has the highest score when the number of topics is 7. We have determined that the articles should be classified into seven topics and then input the number of topics into the model.
num_topics = 7
lda = LdaModel(corpus, num_topics = num_topics, id2word = dictionary, passes = 30, random_state = 42)
# 印出每個主題中的前15個關鍵字詞
topics_lst = lda.print_topics()
print(topics_lst)
In this way, the model is completed. We use the visualization package “pyLDAvis” to present the classification results of the model. The detailed visualization code will be provided at the end of the article.
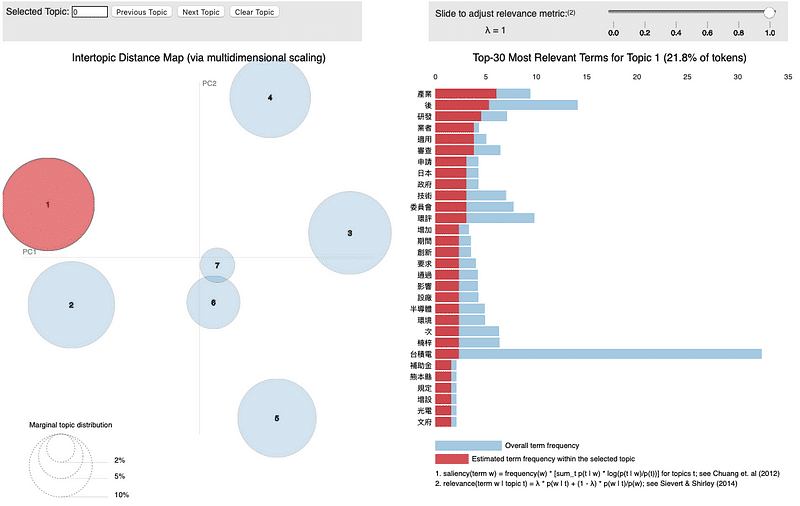
The visualization of pyLDAvis contains two charts.
On the left side is the result of the classification of topics. Each circle represents one topic; the larger the area, the more articles be classified in this topic. The axes result from PCA (Principal Component Analysis ), x-axis is PC1, and y-axis is PC2; the distance between circles reflects the similarity of the two topics.
The other side is the keyword statistics; the blue bar chart is the times of occurrence of keywords in all articles, and the red bar chart is the times of occurrence of keywords in your chosen topic. Adjusting the λ value above can display the unique keywords in this topic; the lower λ value, the more unique keywords.
The classification of topics is not bad, except there is a slight overlapping at the sixth and the seventh topic; others are pretty well.
However, the LDA method used to classify depends on the math. Maybe the result can be clearly and straightly explained by math, but it usually doesn’t match the human’s judgment and sometimes even appear anticorrelation. From a human’s perspective, these results sometimes have a vague concept or logic.
And whether the data has been properly pre-processed will also significantly affect the final classification results. There is an old saying in the IT industry, “garbage in, garbage out.” You can get ideal results by doing an excellent job in data pre-processing. However, pre-processing has many complicated and tedious procedures. Different task requirements often require a certain degree of professional knowledge and relevant experience, which one’s strength cannot quickly achieve.
TESG Event Radar, through massive data sources, analysis by professional researchers, and natural language processing models, lets users no longer need to have the complex mentioned above and high-threshold technologies and knowledge to grasp the latest news of ESG in various companies quickly.
TESG Event Radar has four significant advantages:
Multiple sources of events:
Include more than 20 public sources of information, pay attention to the occurrence of various ESG events of enterprises, follow up the dynamics of enterprises.
Sustainable event classification:
Based on TESG, events are divided into three categories and 16 subcategories so as to understand event attributes and impact levels quickly.
Intensity marker:
Quickly identify the magnitude of an event’s impact.
Keypoint marker:
Identify the nature of the event/the amount of the penalty.
