
Table of Contents
Profit-chasing and risk-averse are the innate naturals of all investors. One way to achieve these goals is to predict the future stock movement. In the past, time series models such as ARIMA and GARCH are widely used to characterize the trajectory of future stock prices. Nowadays, As the boom of artificial intelligence, more and more time-series-related deep learning models have emerged and seem to be new solutions for stock price prediction. In this article, we apply GRU and LSTM model for stock price prediction, using open price, high price, low price and close price in the past five days to predict next day’s close price.
There are many articles describing LSTM model, so no more introduction for LSTM in today’s article. GRU model will be our focal point today. Similar to LSTM, GRU is also a RNN-based model. However, unlike LSTM which has three different gates, forget gate, input gate and output gate, GRU only contains update gate and reset gate. The former gate is identical to forget and input gate of LSTM, it decides which hidden information would be reserved or abandoned during each iteration. The latter gate decides which information accumulated from past iteration would be abandoned. Since the reduction of the numbers of gates, GRU theoretically would achieve more rapid computation speed with little or none depletion of performance.
Google Colab is used as editor
# Load require module
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
import plotly.graph_objects as go
import os
import time
import tejapi
import math
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader, TensorDataset
# log in TEJ API
api_key = 'YOUR_KEY'
tejapi.ApiConfig.api_key = api_key
tejapi.ApiConfig.ignoretz = True
# gpu setting
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Stock trading database: Unadjusted daily stock price, database code is (TWN/APRCD).
In here, we take unadjusted open, high, low, close price from TSMC(2330.TW) as input features. The sampling period is from 2019–01–01 to 2023–01–01. First, the standardization for all four features is processed. Then, a training set and a validation set are separated from the standardized dataset by the ratio of 8:2. Standardization could solve feature scaling problem and boost up the speed of training process.
# import data from tej database
gte, lte = '2019-01-01', '2023-01-01'
data = tejapi.get('TWN/APRCD',
paginate = True,
coid = '2330',
mdate = {'gte':gte, 'lte':lte},
opts = {
'columns':[ 'mdate', 'open_d', 'high_d', 'low_d', 'close_d', 'volume']
}
)
# standardization
scaler = StandardScaler()
data = scaler.fit_transform(data)
# train validation split
train, test = data[:int(0.8 * len(data)), :4], data[int(0.8 * len(data)):, :4]
Next, we create the Pytorch Dataset and DataLoader, these two functions automatically create batch data and allow us input the data into model conveniently.
def create_dataset(dataset, lookback):
X, y = [], []
for i in range(len(dataset)-lookback):
feature = dataset[i:i+lookback, :]
target = dataset[i+1:i+lookback+1][-1][-1]
X.append(feature)
y.append(target)
return torch.FloatTensor(X).to(device), torch.FloatTensor(y).view(-1, 1).to(device)
lookback = 5 # set the window to 5 days
X_train, y_train = create_dataset(train, lookback = lookback)
X_val, y_val = create_dataset(test, lookback = lookback)
loader = DataLoader(TensorDataset(X_train, y_train), shuffle = False, batch_size = 32)
The structure of single layer LSTM contains one LSTM layer, then a Dropout layer, eventually a fully-connected layer is concatenated. The dropout layer is for over-fitting prevention.
● input_size: The feature size of input data. We use open, close,high and low price, so input_size = 4.
● hidden_size: The number of neuron in LSTM hidden layer。
● num_layer: The number of layer of LSTM, default value is one。
● batch_first: Set dimension of output as (batch_size, sequence_length, hidden_size). The sequence_length = 5, because we set window as 5 days.
# Create LSTM fuction
class S_LSTM(nn.Module):
def __init__(self):
super().__init__()
self.lstm1 = nn.LSTM(input_size = 4, hidden_size=64, num_layers=1, batch_first=True)
self.dropout = nn.Dropout(0.2)
self.linear = nn.Linear(64, 1)
def forward(self, x):
x, _ = self.lstm1(x)
x = self.dropout(x)
x = x[:, -1, :]
x = self.linear(x)
return x
# Create training process function
def trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer):
train_loss, test_loss = [],[]
for epoch in range(epochs):
model.train()
for batch, (x, y_true) in enumerate(loader):
y_pred = model(x)
loss = criterion(y_pred, y_true)
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.eval()
with torch.no_grad():
y_pred = model(X_train)
train_rmse = np.sqrt(criterion(y_pred, y_train).item())
train_loss.append(train_rmse)
y_pred = model(X_val)
test_rmse = np.sqrt(criterion(y_pred, y_val).item())
test_loss.append(test_rmse)
if (epoch+1) % 100 == 0:
print('epoch %d train rmse %.4f test rmse %.4f' % (epoch+1, train_rmse, test_rmse))
return train_loss, test_loss
# Set model, loss function and optimizer
model = S_LSTM().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters())
epochs = 1000
# Train start and compute time cost
start = time.time()
slstm_train_loss, slstm_test_loss = trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer)
end = time.time()
print('single lstm time cost %.4f' %(end-start))

fig = go.Figure()
fig.add_trace(go.Scatter(x=np.arange(epochs), y=slstm_train_loss,
mode='lines',
name='Train Loss'))
fig.add_trace(go.Scatter(x=np.arange(epochs) , y=slstm_test_loss,
mode='lines',
name='Validation Loss'))
fig.update_layout(
title="Loss curve for single lstm",
xaxis_title="epochs",
yaxis_title="rmse"
)
fig.show()
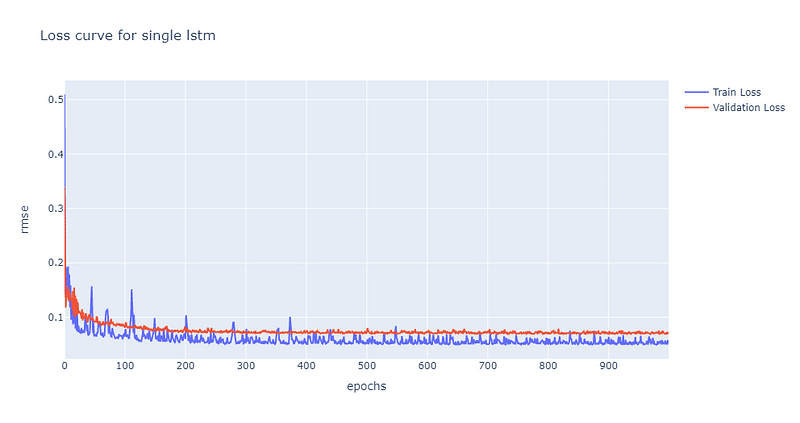
From the loss curve above, we can discover that validation loss converges to 0.07 at the 200th epoch. Furthermore, we can draw a stock price line plot to verify the predictability of single layer LSTM.
train_plot = np.ones_like(data[:, 3]) * np.nan
test_plot = np.ones_like(data[:, 3]) * np.nan
with torch.no_grad():
# predict train data
y_pred = model(X_train)
train_plot[lookback:int(0.8 * len(data))] = y_pred.view(-1).cpu()
# predict validation data
y_pred = model(X_val)
test_plot[int(0.8 * len(data))+lookback:] = y_pred.view(-1).cpu()
fig = go.Figure()
fig.add_trace(go.Scatter(x=mdate, y=train_plot,
mode='lines',
name='Train'))
fig.add_trace(go.Scatter(x=mdate , y=test_plot,
mode='lines',
name='Validation'))
fig.add_trace(go.Scatter(x=mdate , y=data[:, 3],
mode='lines',
name='True'))
fig.update_layout(
title="Stock prediction for sngle lstm",
xaxis_title="dates",
yaxis_title="standardised stock"
)
fig.show()
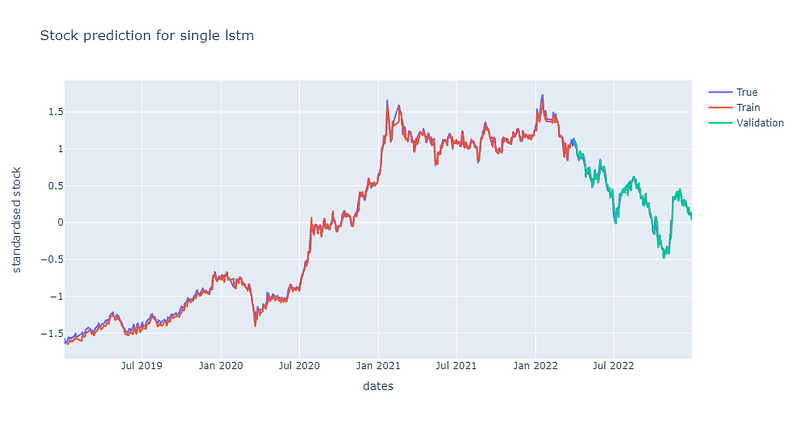
From the stock prediction and loss curve plots, it can be said that the predictability of single layer LSTM is quite nice. The result is quite intriguing, since it conflicts against out previous result from 【Data Analysis】LSTM Trading Signal Judgment. In their result, the single layer LSTM is not able to fully capture the time series information and perform prediction awfully. The main differences between the previous and this model are the previous one additionally use daily trading volume as input feature, the dimension of output from LSTM layer(the previous is 32, the new is 64) and the dropout ratio(the previous is 0.3, the new is 0.2). Currently, we believe that the most likely reason is using daily trading volume as an input feature.
Although single layer can achieve quite excellence performance, we still try out new model by stacking up more LSTM layers, in order to reach better benchmark score. The structure of stacked LSTM: one LSTM layer → one Dropout layer → one LSTM layer → one Dropout layer → one fully connected layer. The ratio of dropout in the two dropout layers are set to 0.4.
# Create double layer LSTM function
class LSTM(nn.Module):
def __init__(self):
super().__init__()
self.lstm1 = nn.LSTM(input_size = 4, hidden_size=64, num_layers=1, batch_first=True)
self.dropout1 = nn.Dropout(0.4)
self.lstm2 = nn.LSTM(input_size = 64, hidden_size=32, num_layers=1, batch_first=True)
self.dropout2 = nn.Dropout(0.4)
self.linear = nn.Linear(32, 1)
def forward(self, x):
x, _ = self.lstm1(x)
x = self.dropout1(x)
x, _ = self.lstm2(x)
x = self.dropout2(x)
x = x[:, -1, :]
x = self.linear(x)
return x
# Create training process function
def trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer):
train_loss, test_loss = [],[]
for epoch in range(epochs):
model.train()
for batch, (x, y_true) in enumerate(loader):
y_pred = model(x)
loss = criterion(y_pred, y_true)
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.eval()
with torch.no_grad():
y_pred = model(X_train)
train_rmse = np.sqrt(criterion(y_pred, y_train).item())
train_loss.append(train_rmse)
y_pred = model(X_val)
test_rmse = np.sqrt(criterion(y_pred, y_val).item())
test_loss.append(test_rmse)
if (epoch+1) % 100 == 0:
print('epoch %d train rmse %.4f test rmse %.4f' % (epoch+1, train_rmse, test_rmse))
return train_loss, test_loss
# Set model, optimizer, loss function
model = LSTM().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters())
epochs = 1000
# Train start and compute time cost
start = time.time()
lstm_train_loss, lstm_test_loss = trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer)
end = time.time()
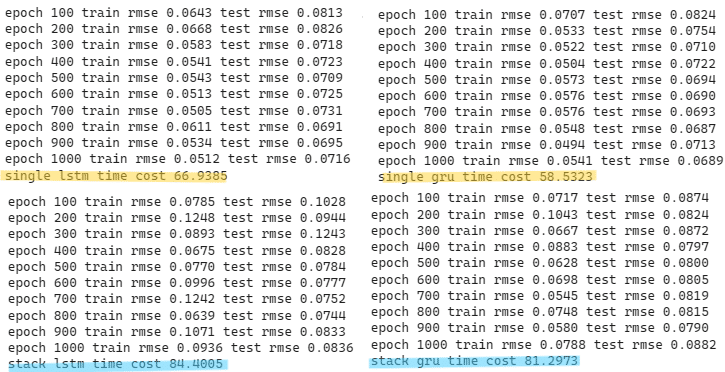
print('stack lstm time cost %.4f' %(end-start))
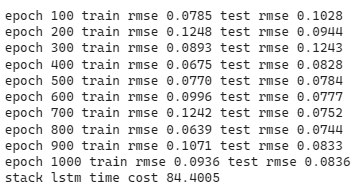
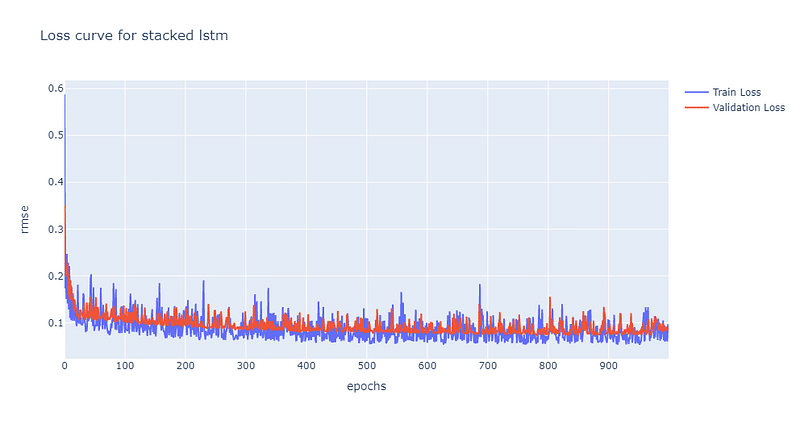
As the complexity of model increases, the convergence rate decreases. It is not until the 500th epochs for model to reach convergence at 0.1. Moreover, stacked LSTM also has more volatile loss curve than single LSTM does. In the picture down below, we can find out that the predictability of stacked LSTM is actually worse than single LSTM. However, despite of lower predictability, stacked layer still is able to capture the trend of stock price. Python code for loss curve and prediction plots are shown in the end.
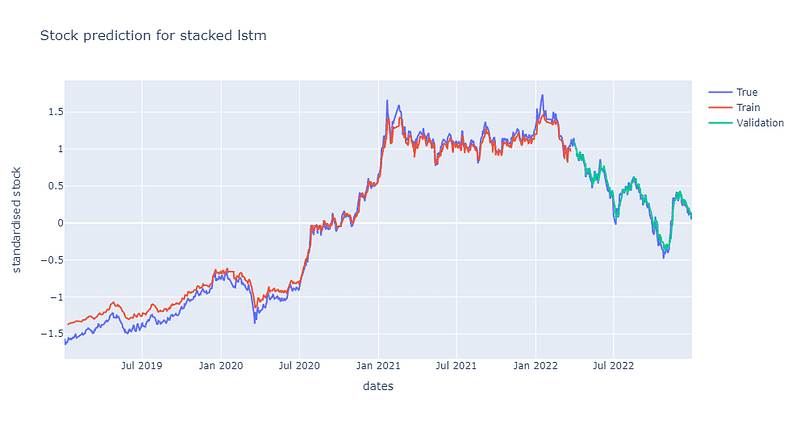
Next, we use single layer GRU for prediction. The structure is similar to single layer LSTM, we just replace LSTM layer with GRU layer.
# create single layer GRU function
class S_GRU(nn.Module):
def __init__(self):
super().__init__()
self.gru1 = nn.GRU(input_size = 4, hidden_size=64, num_layers=1, batch_first = True)
self.dropout = nn.Dropout(0.2)
self.linear = nn.Linear(64, 1)
def forward(self, x):
x, _ = self.gru1(x)
x = self.dropout(x)
x = x[:, -1, :]
x = self.linear(x)
return x
# Create training process function
def trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer):
train_loss, test_loss = [],[]
for epoch in range(epochs):
model.train()
for batch, (x, y_true) in enumerate(loader):
y_pred = model(x)
loss = criterion(y_pred, y_true)
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.eval()
with torch.no_grad():
y_pred = model(X_train)
train_rmse = np.sqrt(criterion(y_pred, y_train).item())
train_loss.append(train_rmse)
y_pred = model(X_val)
test_rmse = np.sqrt(criterion(y_pred, y_val).item())
test_loss.append(test_rmse)
if (epoch+1) % 100 == 0:
print('epoch %d train rmse %.4f test rmse %.4f' % (epoch+1, train_rmse, test_rmse))
return train_loss, test_loss
# set model, optimizer and loss function
model = S_GRU().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters())
epochs = 1000
# Train start and compute time cost
start = time.time()
sgru_train_loss, sgru_test_loss = trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer)
end = time.time()
print('single gru time cost %.4f' %(end-start))
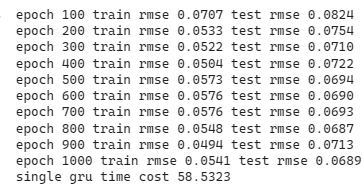
Draw loss curve
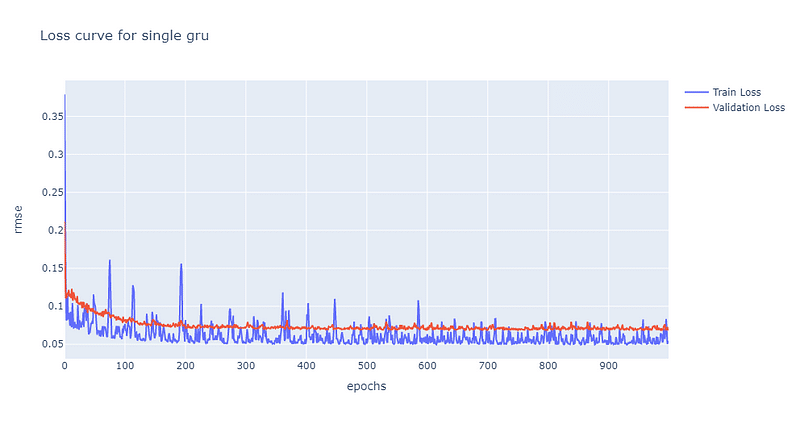
Same as the loss curve of single LSTM, it also converges to 0.7 at the 200th epoch. The training loss curve volatiles a bit more than curve from single LSTM. Also, the similar result as the predictability of the single LSTM, the single GRU model predicts price really well.
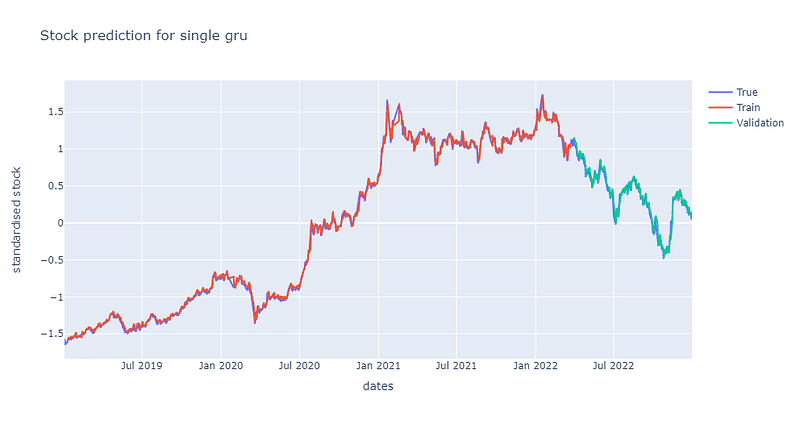
We also create a stacked GRU model to verify whether a more complex GRU model can achieve better performance. The stacked structure: one GRU layer → one Dropout layer → one GRU layer → one Dropout layer → one fully connected layer. The dropout ratio of two layers are set at 0.4.
# create double layer gru model function
class GRU(nn.Module):
def __init__(self):
super().__init__()
self.gru1 = nn.GRU(input_size = 4, hidden_size=64, num_layers=1, batch_first=True)
self.dropout1 = nn.Dropout(0.4)
self.gru2 = nn.GRU(input_size = 64, hidden_size=32, num_layers=1, batch_first=True)
self.dropout2 = nn.Dropout(0.4)
self.linear = nn.Linear(32, 1)
def forward(self, x):
x, _ = self.gru1(x)
x = self.dropout1(x)
x, _ = self.gru2(x)
x = self.dropout2(x)
x = x[:, -1, :]
x = self.linear(x)
return x
# create train process function
def trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer):
train_loss, test_loss = [],[]
for epoch in range(epochs):
model.train()
for batch, (x, y_true) in enumerate(loader):
y_pred = model(x)
loss = criterion(y_pred, y_true)
loss.backward()
optimizer.step()
optimizer.zero_grad()
model.eval()
with torch.no_grad():
y_pred = model(X_train)
train_rmse = np.sqrt(criterion(y_pred, y_train).item())
train_loss.append(train_rmse)
y_pred = model(X_val)
test_rmse = np.sqrt(criterion(y_pred, y_val).item())
test_loss.append(test_rmse)
if (epoch+1) % 100 == 0:
print('epoch %d train rmse %.4f test rmse %.4f' % (epoch+1, train_rmse, test_rmse))
return train_loss, test_loss
# set model, optimizer and loss function
model = GRU().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters())
epochs = 1000
# Train start and compute time cost
start = time.time()
gru_train_loss, gru_test_loss = trainer(epochs, loader, X_train, y_train, X_val, y_val, model, criterion, optimizer)
end = time.time()
print('stack gru time cost %.4f' %(end-start))
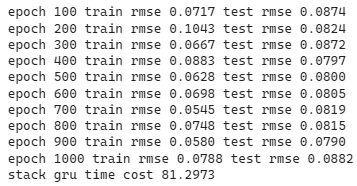
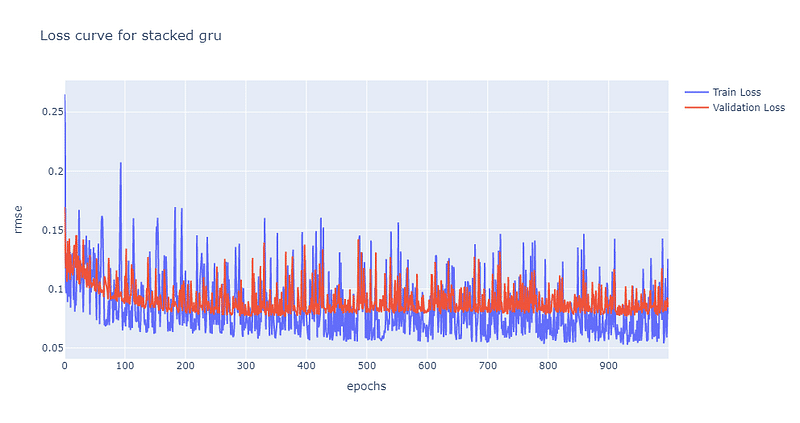
The volatility of loss curve of stacked GRU is higher than that of single GRU. It gradually converges to 0.7 at the 300th epoch. From the below picture, the predictability of stacked GRU is apparently lower than that of single GRU.
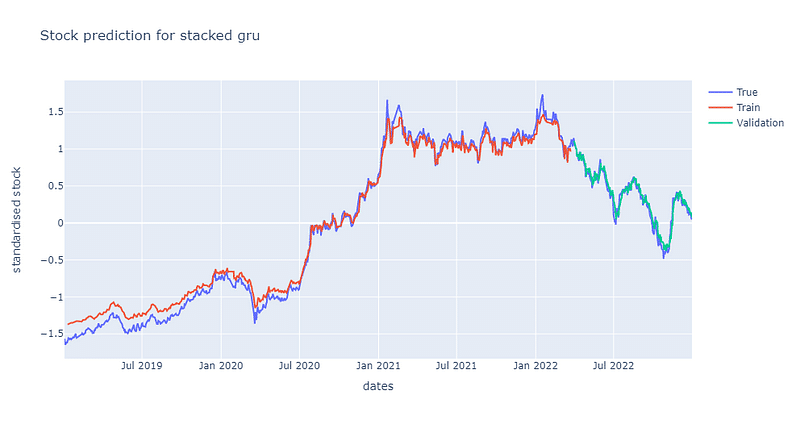
Overall, we can discover that both single layer LSTM and GRU perform finely at predicting TSMC stock price, while stacked models perform a bit worse. Furthermore, we compare both single layer models` loss curve in the next picture. Both curve reach to convergence at around 0.07. The volatility for both curves are actually identical. While loss drops more rapidly for GRU at the beginning of training session. Python code for the following graph is shown in the end.
Besides, in theory, GRU should outperform LSTM at computational speed. During the training session, this stylized fact is also proven true. From the highlight area down below, the single GRU is 8 seconds faster than single LSTM, and double GRU is 3 seconds faster than double LSTM.
Genernally, Both LSTM and GRU predict well in this case. Benefit from more simple structure, GRU has computation speed advantage. Since we only take one stock and limit the time period from 2019 to 2022, statistically, we can not confirm that LSTM or GRU is the perfect model for stock prediction. However, based on the conclusion of【Data Analysis】LSTM Trading Signal Judgment and this experiment, we believe GRU and LSTM could play a role as an auxiliary tool for stock selection strategy. By combining other technical analysis indexes, such as: 【Application】Bollinger Bands Trading Strategy and 【Quant(8)】Backtesting by MACD Indicator , we can bulid a solid trading strategy.
Last but not least, please note that “Stocks this article mentions are just for the discussion, please do not consider it to be any recommendations or suggestions for investment or products.” Hence, if you are interested in issues like Creating Trading Strategy , Performance Backtesting , Evidence-based research , welcome to purchase the plans offered in TEJ E Shop and use the well-complete database to find the potential event.
You could give us encouragement by …
We will share financial database applications every week.
If you think today’s article is good, you can click on the applause icon once.
If you think it is awesome, you can hold the applause icon until 50 times.
Any feedback is welcome, please feel free to leave a comment below.
