
Table of Contents
華倫.巴菲特 Warren E. Buffett 是全世界有史以來,靠股票賺最多錢的人,1956年回到奧瑪哈以100美元起家,至1999年8月為止,個人資產總額已達360億美元以上,成為全美第二富有的人。巴菲特的投資法則非常簡單,首先不理會股價每日的漲跌,其次,不去擔心總體經濟情勢的變化;再者,以買下一家公司的心態投資而非投資股票,而其方法中有四大原則:
本文章使用 Mac OS 並以 Jupyter Notebook 作為編輯器
import tejapi import pandas as pd import numpy as np
Note: tejapi 安裝以命令提示字元 (Windows)/終端機 (Mac),輸入 pip install tejapi
tejapi.ApiConfig.api_key = 'Your Key' tejapi.ApiConfig.ignoretz = True
loc 」、「分群 groupby 」、「樞紐 pivot_table 」由於巴菲特的原則中,部份是無法量化的,因此只選取可數量化的原則,其原則背後的原理皆為,公司能幫股東賺錢的能力高,方法如下:
set_1set_2set_3set_4set_5set_6我們選擇 2019/12/31 符合條件的股票,在 2020/1/1 買入並持有至 2020/12/31。每個一條件都會做一個 set ,最後取交集得到符合條件的標的。
比較每一元保留盈餘是否創造超過一元的市場價值時,由於牽涉到公司上市年限是否夠久,故篩選2020還活著的公司,且上市時間大於7年公司,並去除銀行證券業,因為依據 ROE 公式,可以靠舉債來提升,所以在負債比例高的產業(如: 銀行業28、金控業30)則不適合用 ROE 來判斷。
Step 1. 搜尋上市日的資料庫
tejapi.search_table("上市日")
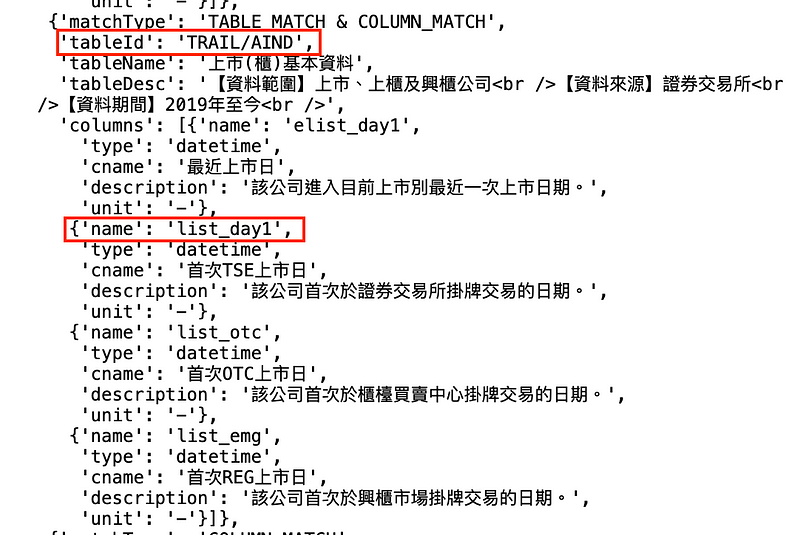
Step 2. 依據搜尋結果,我們使用 TWN/AIND 資料庫,並選擇上市日早於 2013 ,且去除產業 28、29。
comp_data = tejapi.get('TWN/AIND',
elist_day1 ={'lt':'2013-01-01'},
ind = {'ne':('28', '30')},
mkt = 'TSE',
opts = {'columns':['coid', 'elist_day1',
'ind']},
chinese_column_name=True,
paginate=True
)
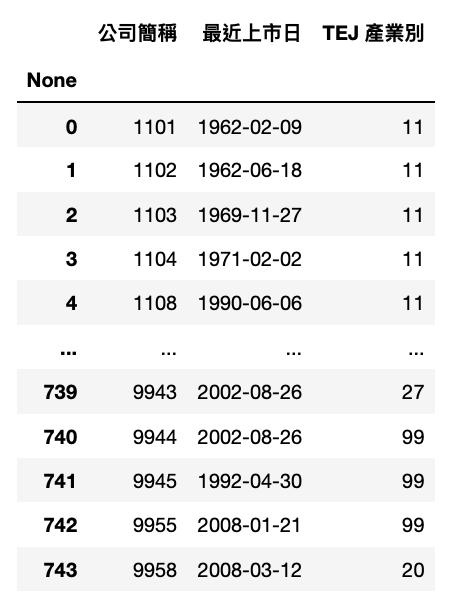
取得符合條件的公司列表,用於之後製作產業平均的數據
comp_list = list(comp_data['公司簡稱'])
Step 3. 製作產業群組字典
將股票池有的產業全部列出並轉成為 list
industry_list = comp_data["TEJ 產業別"].unique().tolist()
將產業內所有公司,製作產業 ROE 字典 dict
industry_data = tejapi.get('TWN/AIND',
ind = industry_list,
mkt = 'TSE',
opts = {'columns':['coid', 'ind']},
chinese_column_name=True,
paginate=True
).reset_index(drop=True)
將資料庫轉換成 key 產業別,value 為公司列表
industry_dict = {}
for i in industry_list:
industry_dict[i] = industry_data[industry_data['TEJ 產業別'] ==
i]['公司簡稱'].tolist()
例如要查詢產業 13 的所有公司
industry_dict["13"]

後續的選股方法都與此類似,故在這段會加以著墨,內容會較為複雜,讀者遇到不理解的部分可以先查看完整程式碼。
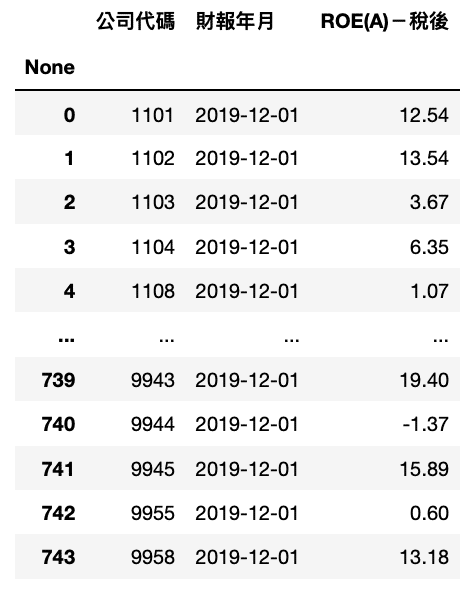
Step 1. 個股 ROE(A)-稅後
ROE_data = tejapi.get('TWN/AIM1A',
coid = comp_list,
mdate= '2019-12-01',
opts={'pivot':True,
'columns':['coid', 'mdate', 'R103']},
chinese_column_name=True,
paginate=True)
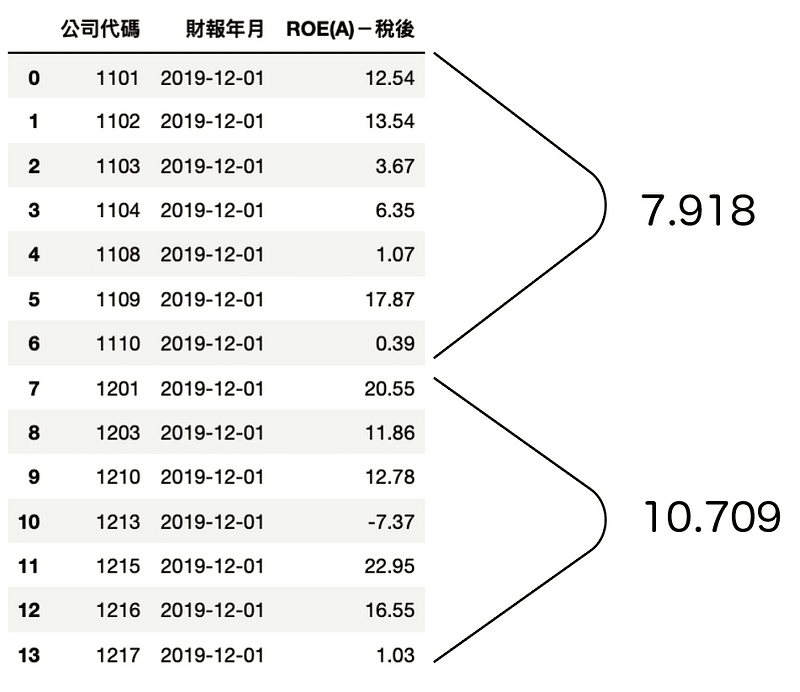
Step 2. 迭代產業別轉換成字典,製作產業 2019 平均 ROE 字典
industry_roe = {}
for i in industry_list:
data = tejapi.get('TWN/AIM1A',
coid = industry_dict[i],
mdate='2019-12-01',
opts={'pivot':True,
'columns':['coid', 'mdate', 'R103']},
chinese_column_name=True,
paginate=True).reset_index(drop=True)
industry_roe[i] = data.groupby('公司代碼').mean().mean()[0]

Step 3. 將產業別對應上述的字典,替換成產業平均 ROE
ROE_data['產業淨值報酬%'] = ROE_data['TEJ 產業別'].apply(lambda x: industry_roe[x])
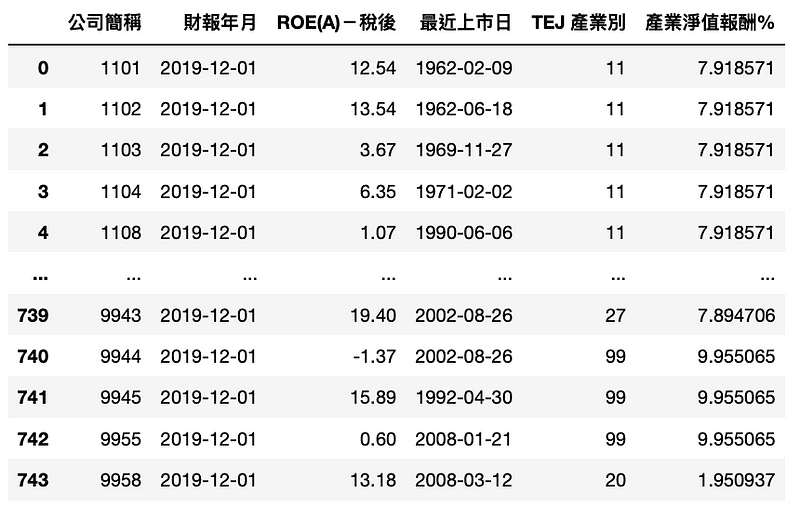
Step 5. 符合條件的公司儲存到 set_1
set_1 = set(ROE_data[ROE_data['ROE(A)-稅後'] > ROE_data['產業淨值報酬%']]['公司簡稱'])
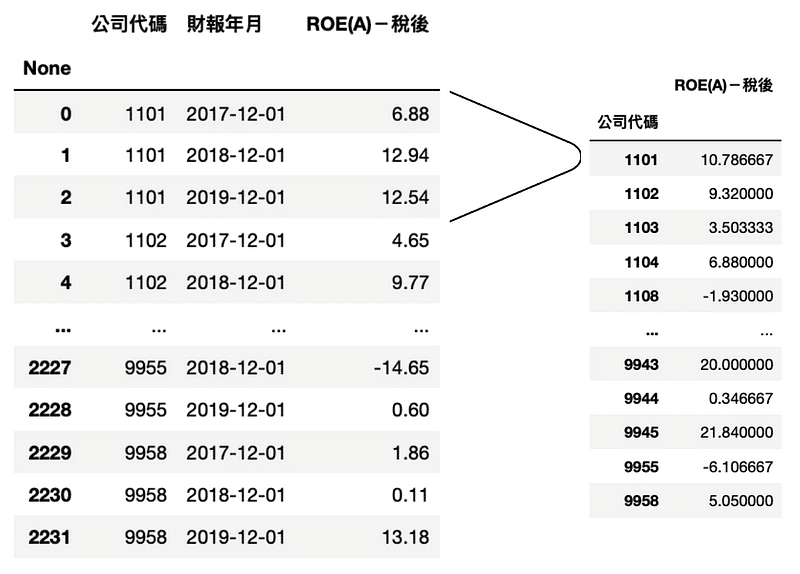
選取三個年度的資料,操作方法如同第一點的公司分組 groupby,數值做平均 mean 並將資料存進 set_2
ROE_data_3Y = tejapi.get('TWN/AIM1A',
coid=comp_list,
mdate=['2017-12-01','2018-12-01','2019-12-
01'],
opts={'pivot':True,
'columns':['coid', 'mdate', 'R103']},
paginate=True,
chinese_column_name=True,
)
操作方法同第一點,完整程式碼請詳見此連結,並將資料存進 set_3
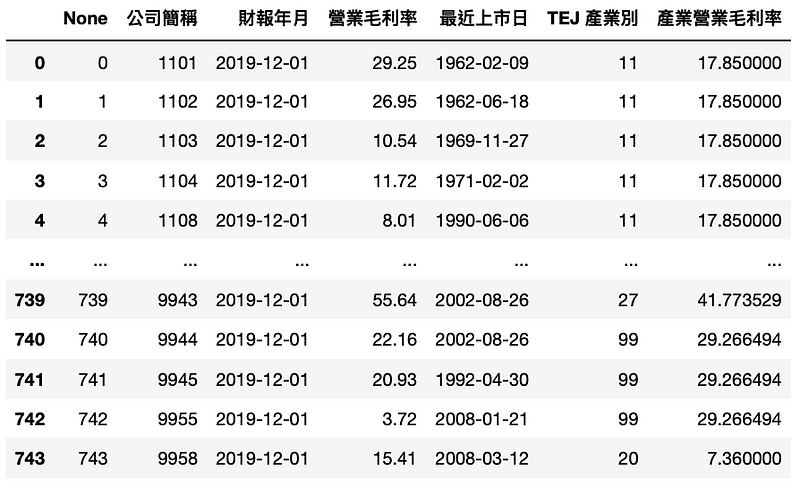
Step 1. 獲得市值、保留盈餘資料
MV_RE_data = tejapi.get('TWN/AIM1A',
coid = comp_list,
mdate= ['2019/12/01','2013/03/01'],
opts={'pivot':True,
'columns':['coid', 'mdate','MV','2341']},
chinese_column_name=True,
paginate=True
).reset_index(drop=True)
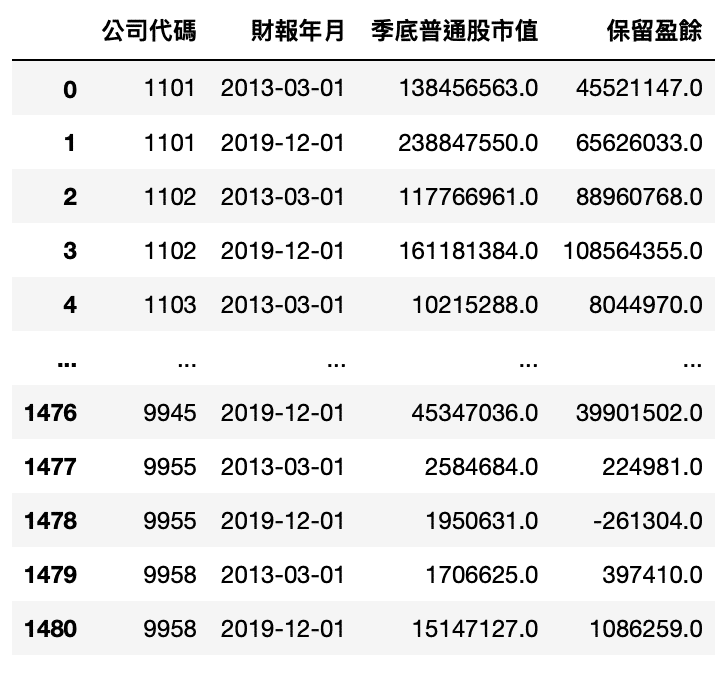
Step 2. 將資料轉置 pivot_table
MV_RE_data.pivot_table(index='公司代碼', columns='財報年月').reset_index()
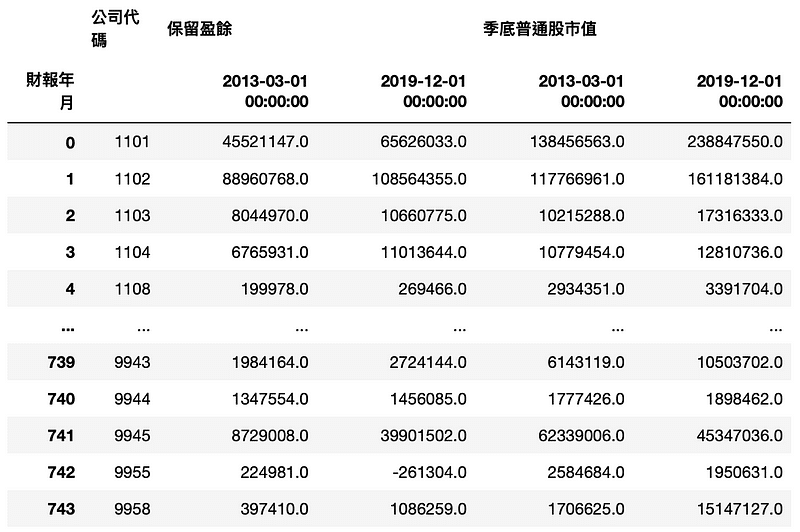
Step 3. 再將兩個欄位相減即可得到增加值
MV_RE_data['保留盈餘增加值'] = MV_RE_data.iloc[:,2] - MV_RE_data.iloc[:,1]
MV_RE_data['市值增加值'] = MV_RE_data.iloc[:,4] - MV_RE_data.iloc[:,3]
Step 4.計算指標
MV_RE_data['指標'] = MV_RE_data['市值增加值'] / MV_RE_data['保留盈餘增加值']
Step 5. 將符合條件的股票存到 set_4
set_4 = set(MV_RE_data[MV_RE_data['指標']>1]['公司代碼'])
Step 1. 獲得自由現金流量資料
cash_data = tejapi.get('TWN/AIM1A',
coid= comp_list,
mdate=['2013-12-01', '2019-12-01'],
opts={'pivot':True,
'columns':['coid', 'mdate', 'R69B']},
paginate=True,
chinese_column_name=True,
)
Step 2. 操作方法如第四點資料樞紐轉置,欄位相減獲得指標
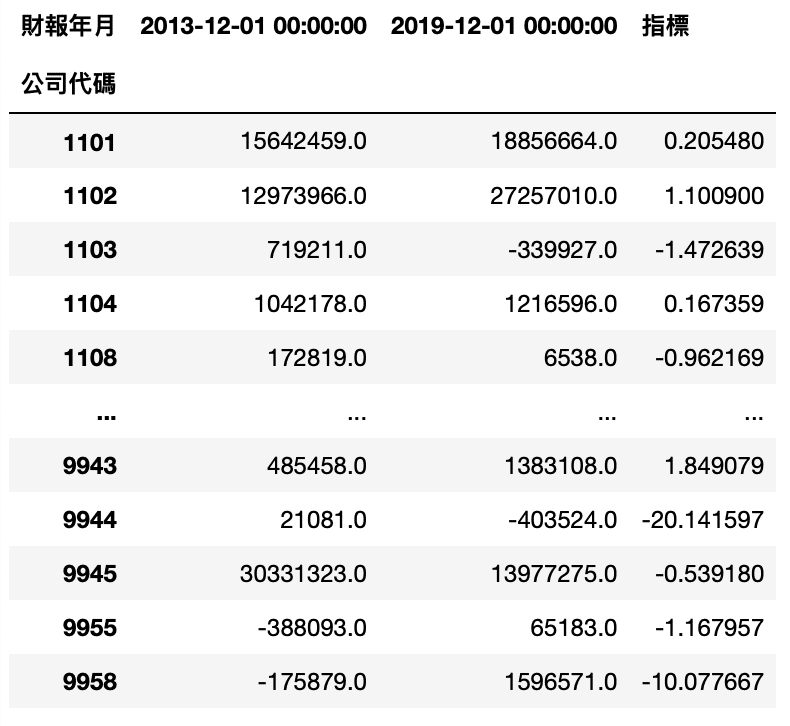
Step 3. 儲存到 set_5
set_5 = set(cash_data[cash_data['指標'] > 1].index)
numpy_financial其模組說明文件點此連結,在終端機輸入 pip install numpy_financialimport numpy_financial as npf
這裡舉一個例子,某公司的四年現金流量為 100 / -150 / -200 / 400,我們要計算他的淨現值可以利用 NPV 法,使用貼現率 10% 和未來各期支出(負值) 和收入(正值) 來計算投資的淨現值
cash_flows = np.array([100, -150, -200, 400]) npf.npv(0.1, cash_flows)
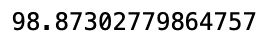
def Cashflows(y0):
y1 = y0 * 1.15
y2 = y1 * 1.15
y3 = y2 * 1.15
y4 = y3 * 1.05
y5 = y4 * 1.05
y6 = y5 * 1.05
y7 = y6 * 1.05
y8 = y7 * 1.05
y9 = y8 * 1.05
y10 = y9 * 1.05
cashflows = np.array([y1,y2,y3,y4,y5,y6,y7,y8,y9,y10])
return cashflows
Step 1. 獲取 2019 年度自由現金流量資料和市值
MV_cash_data = tejapi.get('TWN/AIM1A',
coid= comp_list,
mdate='2019-12-01',
opts={'pivot':True,
'columns':['coid', 'mdate', 'R69B',
'MV']},
paginate=True,
chinese_column_name=True,
).reset_index(drop=True)
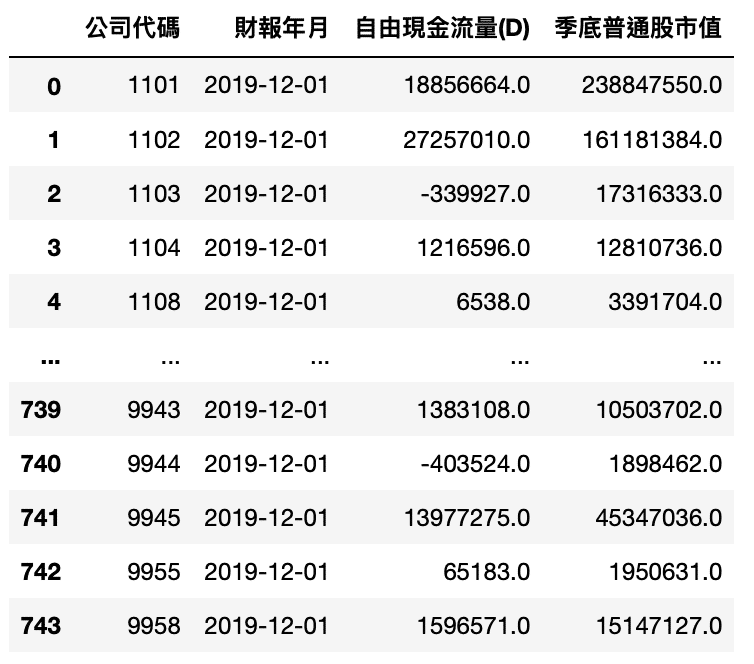
Step 2. 現金流轉換成現值
MV_cash_data['自由現金流量(D)'].apply(lambda x: npf.npv(0.09, Cashflows(x)))
Step 3. 計算指標
MV_cash_data['指標'] = MV_cash_data['季底普通股市值'] / MV_cash_data['自由現金流量(D)'].apply(lambda x: npf.npv(0.09, Cashflows(x)))
Step 3. 符合條件的股票儲存為 set_6
set_6 = set(MV_cash_data[(MV_cash_data['指標']<1) & (MV_cash_data['指標']>0)]['公司代碼'])
來到我們最期待的最後階段,將各個 set 取交集獲得我們的投資組合
set_1 & set_2 & set_3 & set_4 & set_5 & set_6
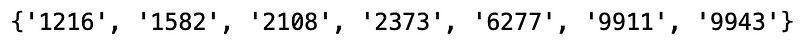
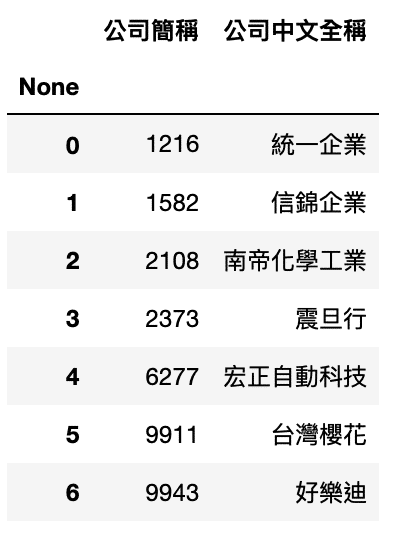
參考 模組化回測系統 ,我們將此投組代入系統,由於投資組合的價格落差過大,我們採用等權重買入持有,2020 獲得的報酬率%為
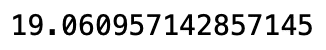
如果能熟練的操作資料庫,股票的篩選設計可以非常客製化,也可以去實測坊間各式各樣的選股策略,而此篇的內容較為複雜,需多花點心力研讀,若讀者有興趣製作更多選股策略,可以前往我們的官方網站,裡面有提供更多財務、交易等財金資料,來幫助您製作更好的選股策略!
本文僅供參考之用,並不構成要約、招攬或邀請、誘使、任何不論種類或形式之申述或訂立任何建議及推薦,讀者務請運用個人獨立思考能力,自行作出投資決定,如因相關建議招致損失,概與作者無涉。
