
Table of Contents
隨機森林簡單來說,就是由多顆決策樹所組成,其為使用 Bagging 加上隨機特徵採樣所產生的一種演算法。因為是基於 CART演算法,所以可以處理類別資料與連續資料,其他的優點像是其能夠接收高維度的資料、對雜訊容忍度高、擬和結果準確率高等等,故亦時常用於Kaggle等商業競賽。
本文將利用財務數據作為特徵,來預測下一季的股價是上漲還是下跌,因此為一種二元分類問題。接著再觀察是否能從模型結果得出有用的資訊來進一步優化我們的選股策略!
本文使用 Windows OS 並以 Jupyter Notebook 作為編輯器
#功能模組import pandas as pdimport numpy as npimport matplotlib.pyplot as plt#機器學習from sklearn.ensemble import RandomForestClassifier#TEJ APIimport tejapitejapi.ApiConfig.api_key = 'Your Key'tejapi.ApiConfig.ignoretz = True
Step 1. 撈取產業代碼、財務、報酬率資料
security = tejapi.get('TWN/ANPRCSTD',mkt = 'TSE',stypenm = '普通股',paginate = True,chinese_column_name = True)#儲存公司代碼security_list = security['證券碼'].tolist()#儲存產業代碼industry_code = security[['證券碼', 'TSE業別']]industry_code = industry_code.set_index('證券碼').to_dict()['TSE業別']
首先撈取的是上市普通股的資料,這邊我們需要的是公司代碼,以及其所對應的產業代碼,因此將其轉為字典儲存。
groups = []while True:if len(security_list) >= 50:groups.append(security_list[:50])security_list = security_list[50:]elif 0 <= len(security_list) < 50:groups.append(security_list)break
將公司以50家為一組,以便下一步進行迴圈撈取資料。這麼做的目的是避免到時撈資料時一次撈取過多,而導致撈取失敗的情況。
fin_data = pd.DataFrame() #財務資料ret_data = pd.DataFrame() #報酬率資料date_data = pd.DataFrame() #日期資料for group in groups:fin_data = fin_data.append(tejapi.get('TWN/EWIFINQ',coid = group,chinese_column_name = True,paginate = True)).reset_index(drop=True)ret_data = ret_data.append(tejapi.get('TWN/APRCD2',coid = group,opts = {'columns': ['coid', 'mdate', 'roi_q']},paginate = True,chinese_column_name = True)).reset_index(drop=True)date_data = date_data.append(tejapi.get('TWN/EWFINDATE2',coid = group,opts = {'columns': ['coid', 'mdate', 'fin_date']},paginate = True,chinese_column_name = True)).reset_index(drop=True)
透過迴圈的方式一次取得每組公司所有年度的財務資料、季報酬率資料。值得注意的是,這邊的季報酬率為日頻率資料,因為其代表的是當日的前一季累積的報酬率,為滾動式季報酬的概念,因此每日都會有一筆資料。date_data則為TEJ提供的交易日、財報公布日對應的表格,非常適合用於合併股價與財務資料。
Step 2. 資料合併
date_data = date_data.groupby(['證券碼', '財務公告日']).last().reset_index()date_data = date_data.rename(columns = {'交易日期':'年月日', '財務公告日':'財報發布日'})
取得下一次財報公布前的最後一筆交易日期,接著會利用此日期與季報酬率資料的日期進行合併,則此季報酬代表的即是財報公布日後的整季報酬率。最後再改變欄名以利後續合併
merge = date_data.merge(fin_data, on = ['證券碼', '財報發布日'])merge = merge.rename(columns = {'證券碼':'證券代碼'})merge = merge.merge(ret_data, on = ['證券代碼', '年月日'])merge = merge.set_index(['證券代碼', '財務資料日']).select_dtypes(include=np.number)
合併所有的資料,將證券代碼、財務資料日作為新的索引,且只選擇數值資料的欄位
Step 1. 切割訓練集與測試集,並進行模型訓練
condition = merge.index.get_level_values('財務資料日') < '2020'train_data = merge[condition].fillna(0)test_data = merge[~condition].fillna(0)rf = RandomForestClassifier(n_estimators=100, criterion= 'entropy')rf.fit(train_data.drop(columns = '季報酬率 %'), train_data['季報酬率 %'] > 0)
這邊我們以2020年以前的資料作為訓練集,以後的資料為測試集,並將缺失值都補上零,最後將測試集的特徵、標籤資料(布林值)丟到模型開始訓練。
Step 2. 模型表現
print("訓練集分數: " , rf.score(train_data.drop(columns = '季報酬率 %'), train_data['季報酬率 %'] > 0))print("訓練集分數: " , rf.score(test_data.drop(columns = '季報酬率 %'), test_data['季報酬率 %'] > 0))
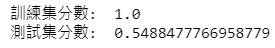
selected = rf.predict(test_data.drop(columns = '季報酬率 %'))test_data[selected]
以模型預測出的布林值作為篩選條件,挑選並觀察 2020年以後被模型預測下季報酬率為正的資料
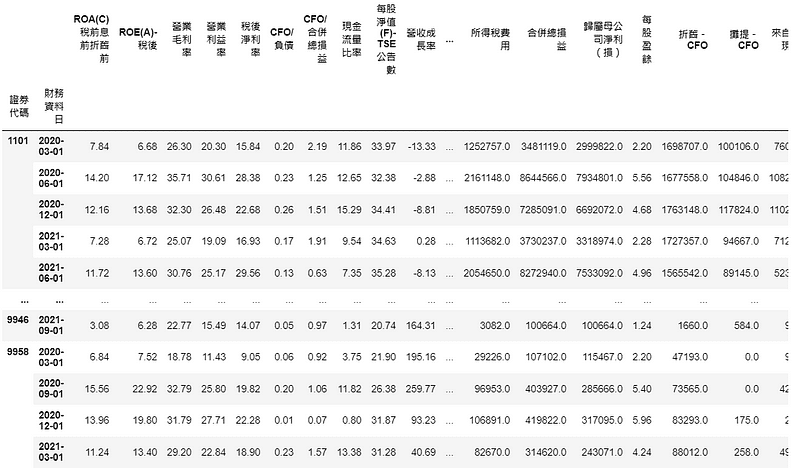
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei'] #顯示中文(test_data[selected].groupby('財務資料日').mean()['季報酬率 %']*0.01 + 1).cumprod().plot(color = 'blue') #randomforest(test_data[~selected].groupby('財務資料日').mean()['季報酬率 %']*0.01 + 1).cumprod().plot(color = 'orange') #benchmark1(test_data.groupby('財務資料日').mean()['季報酬率 %']*0.01 + 1).cumprod().plot(color = 'red') #benchmark2
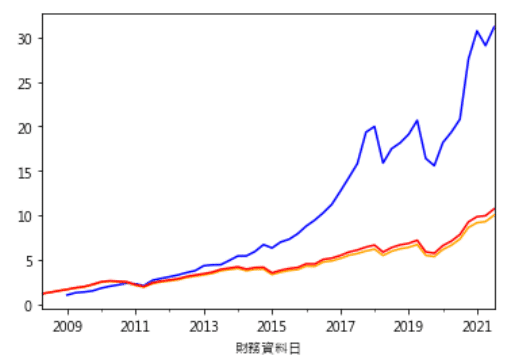
這邊劃出三條線,藍線為每季模型預測上漲的股票,形成的投組累積報酬率;橘線為反向篩選出的報酬率;紅線為不進行篩選的報酬率。可以看到模型預測的選股表現相較之下較佳。
Step 1. 挑選重要特徵
feature_name = train_data.columns[:-1]important = pd.Series(rf.feature_importances_, index = feature_name).sort_values(ascending=False)important.head(20)
觀察前20重要的特徵,當作我們選股的依據

positive_features = ['營業利益成長率', '營收成長率', '投資活動之現金流量', '營業毛利成長率', 'ROE(A)-稅後', '營業外收入及支出', 'ROA(C) 稅前息前折舊前', 'CFO/合併總損益', '稅後淨利率', '每股淨值(F)-TSE公告數', '營業利益率', '營業毛利率', '來自營運之現金流量']接著從這20個重要特徵中,主觀選出值越大、理應越為正面的幾個數據或指標,因為之後要將這些值轉成百分位數,並計算一個總分作為篩選標準,所以高分必須意味著表現越良好。
Step 2. 同產業相比設定
merge['產業'] = merge.index.get_level_values('證券代碼').map(industry_code)merge = merge.reset_index().set_index(['證券代碼', '產業', '財務資料日'])
這邊將資料處理當時儲存的 industry_code字典的值,也就是產業代碼映射到 merge 裡並形成新欄位,再將此欄位與證券碼、財務資料日一起當作索引
Step 3. 計算重要特徵總分,以此作為選股依據
score = merge[positive_features].groupby(['財務資料日', '產業']).rank(pct=True).sum(axis = 1)rank = score.rank(pct = True) #總分再rankfilters = rank > 0.97(merge[filters].groupby('財務資料日').mean()['季報酬率 %']*0.01+1).cumprod().plot(color = 'blue')(merge[~filters].groupby('財務資料日').mean()['季報酬率 %']*0.01+1).cumprod().plot(color = 'orange')(merge.groupby('財務資料日').mean()['季報酬率 %']*0.01 + 1).cumprod().plot(color = 'red')
將資料以同期同產業分組,再以rank(pct=True) 在組內進行每個特徵的百分位數排名,接著橫向加總後再排名一次。最後篩選出分數高於 97 百分位的所有資料,並進行全年度的回測。以下可以看到這種選股策略(藍線),顯著優於其他 benchmark 表現。
this_season = fin_data[fin_data['財務資料日'] == '2021-09-01']this_season['產業'] = this_season['證券碼'].map(industry_code)this_season = this_season.set_index(['證券碼', '財務資料日', '產業']).loc[:,positive_features]score = this_season.groupby(['產業']).rank(pct=True).sum(axis = 1)rank = score.rank(pct = True)firm_list = [i[0] for i in rank[rank > 0.97].index]firms = tejapi.get('TWN/AIND',coid = firm_list,opts = {'columns':['coid','fnamec']},paginate = True,chinese_column_name = True)
這邊直接選擇 2021 Q3,選股邏輯一樣是挑選該期間同產業最好的前3%,再利用 TWN/AIND 資料庫觀察公司名稱
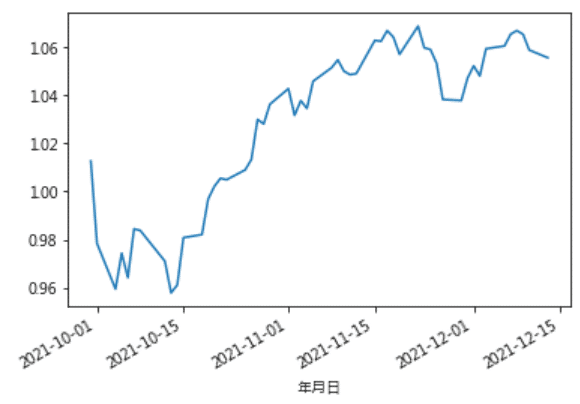
ret_sofar = tejapi.get('TWN/APRCD2',coid = firm_list,mdate = {'gte':'2021-09-30'},opts = {'columns': ['coid', 'mdate', 'roia']},paginate = True,chinese_column_name = True)ret_sofar.groupby('年月日')['日報酬率 %'].mean().apply(lambda x: 0.01*x + 1).cumprod().plot()
各產業優質公司投組從2021 Q3結束以來的累積報酬率
因為 TEJ API 資料庫資料較為齊全,所以在資料處理上較為輕鬆,只要將資料合併、分割訓練集後即可開始建立模型。雖然模型預測成功率僅 54.88 %,但我們仍然可以從這個模型去觀察哪些特徵是判斷報酬率漲跌的重要因素。讀者們可以試著調整模型參數、選擇不同特徵、利用 TEJ API 各種資料庫,篩選出個股後再參考各產業未來趨勢進行二次篩選等等,最後再去建構一個報酬率表現最佳的投組,並觀察未來是否能夠持續這種表現。
本文僅供參考之用,並不構成要約、招攬或邀請、誘使、任何不論種類或形式之申述或訂立任何建議及推薦,讀者務請運用個人獨立思考能力,自行作出投資決定,如因相關建議招致損失,概與作者無涉。
