
Table of Contents
預測未來是大家投資者們想追求的,不論是對於未來的市場,或是對於公司及產業的未來,然而預測未來總存在著不確定及隨機性,因此我們只能利用過去的歷史資料及現有的公司指標,將其投入統計中進行驗證,本文與先前文章【量化分析】預測市場?! 內容類似,但差別在於本文是預測公司未來,並且做出三種統計方式的比較。
使用不同指標,ROA、CR、DR、ATTNVR、CFAT、RSize、Sigma、ExRET,檢定驗證發現某些指標具有解釋能力,並納入回歸模型,利用結果來解釋危機發生機率。
此篇文章之回歸變數參考兩位作者相關論文
本文使用 Spyder作為編輯器
###量化三寶、套件工具 import pandas as pd import numpy as np import tejapi import statsmodels.formula.api as smf import datetime as dt from dateutil.relativedelta import *
tejapi.ApiConfig.api_key = "YOUR_KEY" tejapi.ApiConfig.ignoretz = True ###時間欄位忽略時區
公司基本資料詳細欄位說明:
標的:上市、上櫃、興櫃、公開發行
資料庫代碼為(TWN/AIND),撈取其欄位「危機發生日、危機事件類別」
df1 = tejapi.get('TWN/AIND', #從TEJ api撈取所需要的資料
chinese_column_name = True,
paginate = True,
opts={'columns':['coid','mdate', 'dflt_d','fail_fg']})
首先將撈取的資料做分類,剔除上市前之公司,由於我們是衡量「危機事件發生機率」,因此我們定義危機事件狀況設為1,並開始處理資料,事件發生日要重設,方便之後與財報資料作合併。
df2 = df1[df1['危機事件類別'] != ''] #把有發生違約事件的篩選出來
df2['年/月'] = df2[['危機發生日']].applymap(lambda x: x.strftime('%Y-%m')).astype('datetime64') #把日期都換成月初
df2['月'] = df2['年/月'].dt.month #取月份出來
df2.reset_index(inplace = True)for i in range(len(df2.index)):
if df2['月'][i] == 1 or df2['月'][i] == 4 or df2['月'][i] == 7 or df2['月'][i] == 10:
df2['年/月'][i] = df2['年/月'][i]+ relativedelta(months = +2)
if df2['月'][i] == 2 or df2['月'][i] == 5 or df2['月'][i] == 8 or df2['月'][i] == 11:
df2['年/月'][i] = df2['年/月'][i]+ relativedelta(months = +1)
#為了之後對上財報資料,先將日期處理好
df2['Y'] = 1 #把所有危機事件類別設成1
df2.rename(columns= {'公司簡稱':'公司'}, inplace=True)
接著將全市場會計科目不限期數之資料撈下,並挑選所需要的變數(會計科目)即可,包含:
X1 = working capital(R678)/total asset (0010)
X2 = retained earnings (2341)/ total asset
X3 = EBIT (2402)/total asset
X4 = market value (MV)/ total debt (1000)
X5 = revenue/ total asset (R607)
X6 = ROA (R11V)
X7 = debt ratio (R505)
由於一次撈取的資料比數有限(paginate = True,最多每次撈取100萬筆),因此,我們需要分段撈取再將其合併成同一個Dataframe。
###每一Dataframe大概有30萬筆資料以此類推
a1 = tejapi.get('TWN/AIFIN', #從TEJ api撈取所需要的資料
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2008-01-01', 'lt':'2011-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])
a2 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2011-01-01', 'lt':'2014-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])
a3 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2014-01-01', 'lt':'2017-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])
a4 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2017-01-01', 'lt':'2020-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])
a5 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2020-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])
###合併資料 acc = pd.concat([a1,a2,a3,a4,a5])
轉換會計科目數值將其放到columns,有利於將會計科目計算成所需的變數,計算邏輯來自參考文獻,並將合併後沒有危機發生之公司設為0,資料尚有一個特殊值須刪除。
acc1 = acc.pivot_table(values='數值', index=['公司','年/月'], columns='會計科目')
acc1['X1'] = (acc1['R678']/acc1['0010'])*100
acc1['X2'] = (acc1['2341']/acc1['0010'])*100
acc1['X3'] = (acc1['2402']/acc1['0010'])*100
acc1['X4'] = (acc1['MV']/acc1['1000'])*100
acc1 = acc1.rename(columns = {'R607':'X5', 'R11V':'X6', 'R505':'X7'})
acc2 = acc1[['X1','X2','X3','X4','X5','X6','X7']]
acc2.reset_index(inplace=True)
df3 = pd.merge(acc2, df2[['公司','年/月','Y']], how='outer')
df3['Y'] = df3['Y'].replace(np.nan, 0) #把沒有發生危機的設為0
df3 = df3.dropna()
df3['X4'] = df3['X4'].drop([59690,59688]) #把無限大的值去掉
df3 = df3.rename(columns = {'狀況':'Y'})
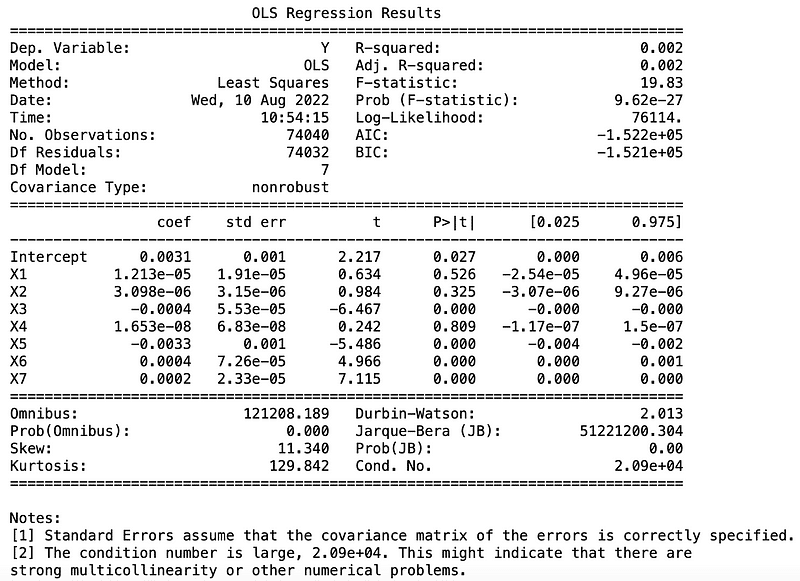
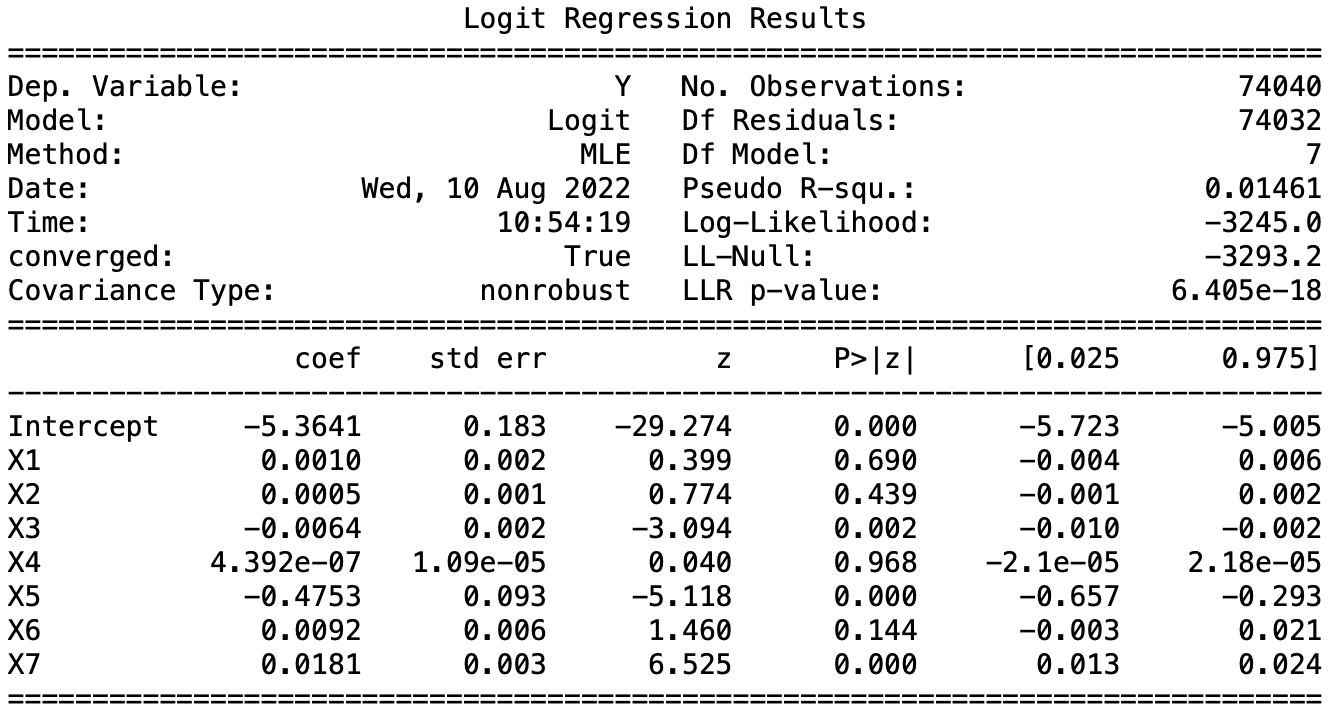
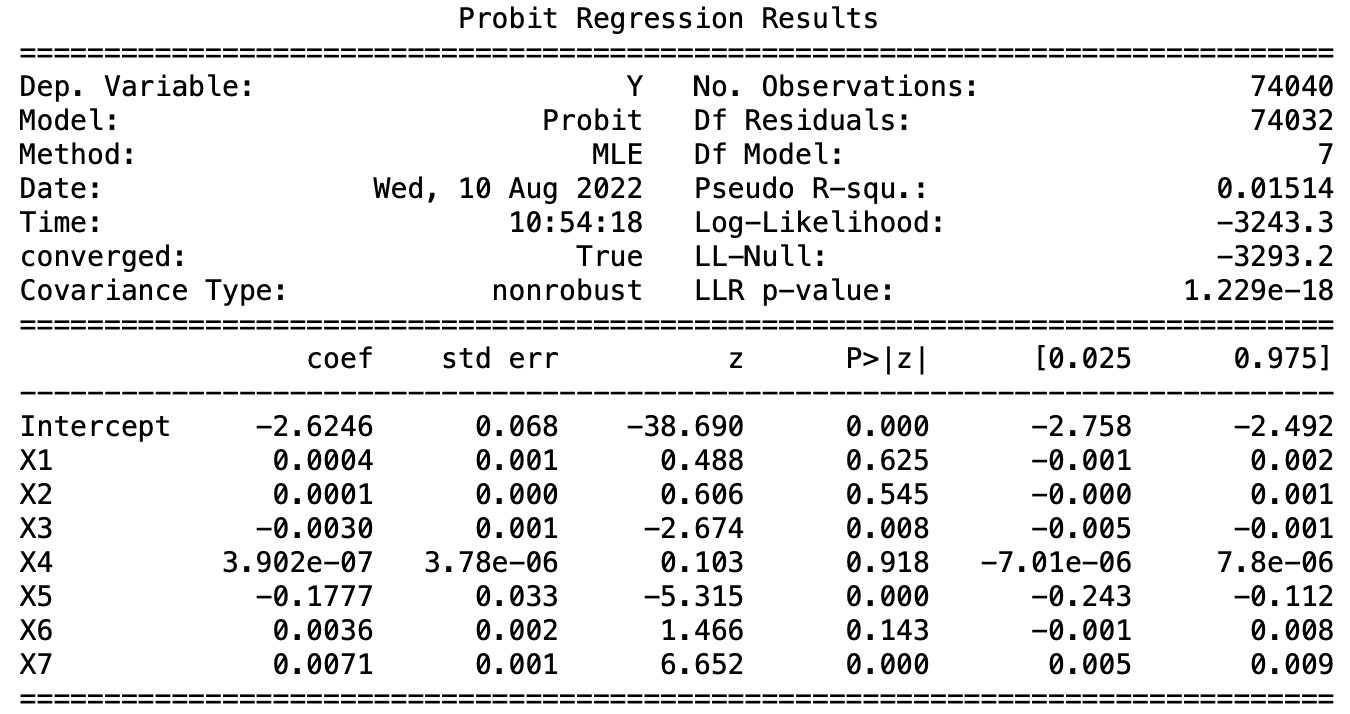
接著帶入變數於三種模型檢定其解釋力,我們可以發現:
變數X1在Logit模型中是不顯著的,而X2、5、6在三種模型中皆具有顯著性,其預測的結果也與我們直觀來說是符合的。以ROA舉例,當ROA越高公司利用資產獲利的能力越佳,倒閉的可能性越低,係數為負,符合預期。
接著將個別公司的會計資料帶入回歸模型中,來取得公司危機發生的機率,我們以上市櫃2330台積電、2454聯發科,下市1592英瑞KY、2475華映。

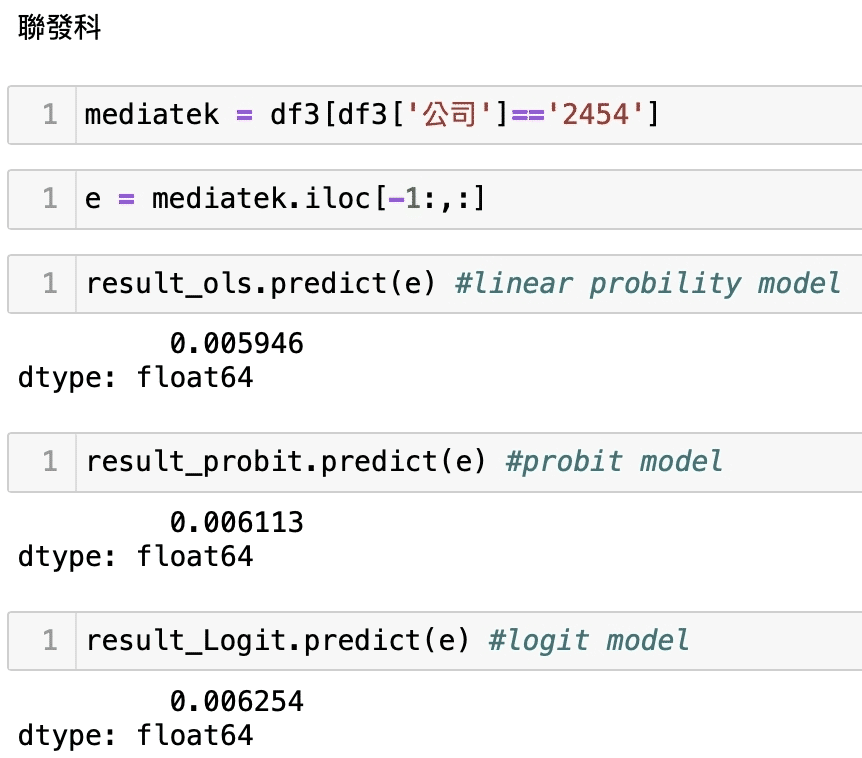
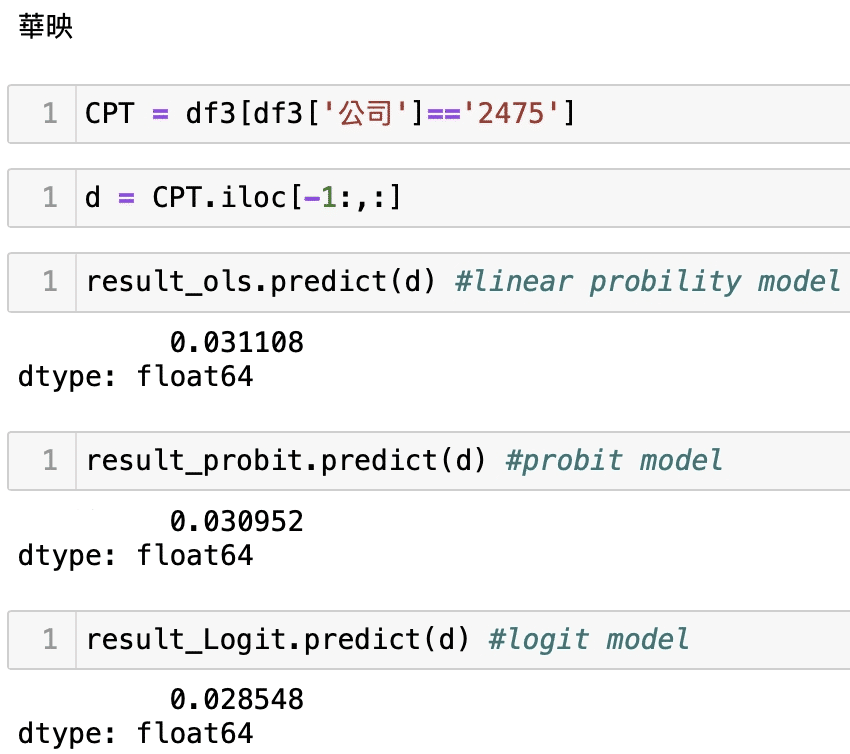
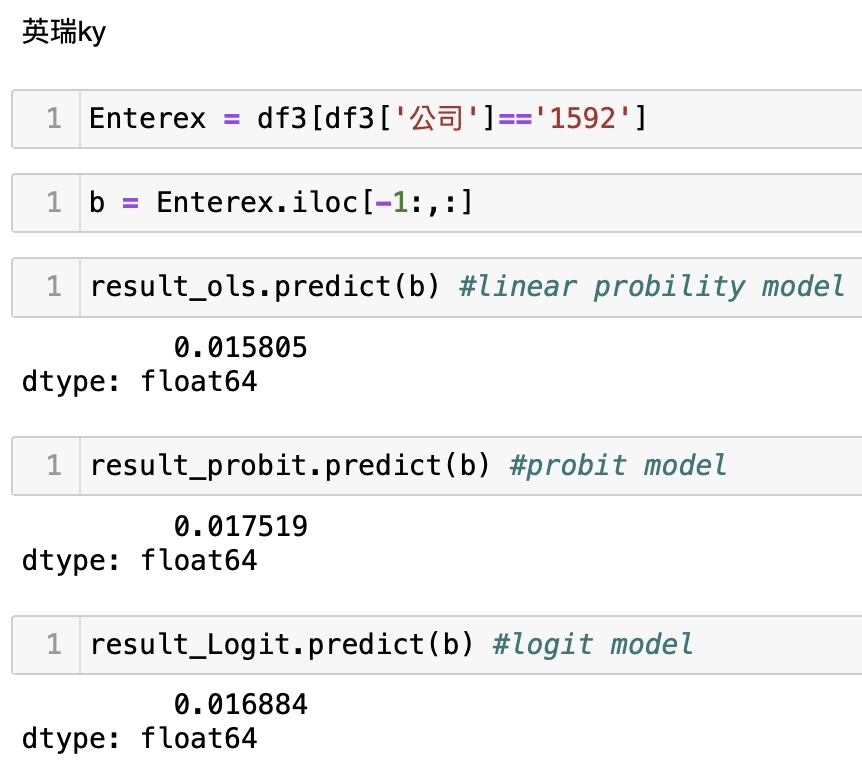
可以發現我們的護國神山及發哥的危機事件發生極為低,假設以他為基準來比較可以看到LPM模型(OLS),下市的1592英瑞KY、2475華映的危機發生機率比2330台積電、2454聯發科來得多出至少3倍以上,直觀而言,權值股之所以是權值股,他的公司體質一定比其他公司來的好,此預測不代表絕對,我們僅使用了相關會計資料所顯示的狀態去作出回歸驗證,但還是具有一定參考性及解釋力,這也意味著股市本來就存在不確定性,若有看似危機的訊號出現應當時刻關注,並留意自身風險的評估;因此,歡迎持續關注本平台,我們後續將會有更多文章向大家分享,此外,也歡迎讀者及投資者們選購 TEJ E Shop中的方案來套用試試看自身手中的持股,危機發生的可能與比較,相信讀者擁有完整的資料庫後,就能對股市的不確定性有所掌握。
