
Table of Contents
Support Vector Machine(簡稱SVM)模型中文全稱為支援向量機,是一種基於統計原理的機器學習演算法,應運用於資料分類(Classifier)以及迴歸(Regressor),本文會以資料分類為主進行。
SVM進行分類的過程,簡單來說便是以直線或不規則的線切分不同屬性的資料。至於要如何畫出最佳解的線,需要考慮兩個問題,首先便是資料屬性的差異程度,簡單來說即如果一條線越寬,則代表他能夠辨識資料差異的程度越好;其次則是分類誤差,因為在實務操作上不太可能全然地將不同屬性的資料分割,所以也要考量到誤差的大小,運作方式為設定誤差懲罰項係數。而上述兩項標準孰輕孰重,則需要模型操作人員設定參數,文中會再說明。
本文使用 MacOS 並以 Jupyter Notebook作為編輯器
# 基本功能 import numpy as np import pandas as pd
# 繪圖 import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.set()
# TEJ API import tejapi tejapi.ApiConfig.api_key = 'Your Key' tejapi.ApiConfig.ignoretz = True
證券屬性資料表:台灣全市場證券標的屬性資料,資料代碼為(TWN/ANPRCSTD)。
財務資料表(季):提供基礎財務資料,單季資料,非累積資料。資料代碼為(TWN/EWIFINQ)。
上市(櫃)未調整股價(日):上市證券及指數(TSE及OTC)的交易面資料。資料代碼為(TWN/APRCD)。
Step 1. 處理證券屬性資料
sec_code = tejapi.get('TWN/ANPRCSTD', chinese_column_name = True)
condition = (sec_code['上市別'] == 'TSE') & (sec_code['證券種類名稱'] == '普通股')
pub_common_stk = sec_code.loc[condition, '證券碼'].to_list()
篩選證券標的為台灣股票市場並且設定範圍僅考慮普通股。
Step 2. 導入財務資料
fin_data = tejapi.get('TWN/EWIFINQ',
coid = pub_common_stk,
mdate= {'gte': '2017-01-01', 'lte': '2021-12-31'},
opts={'columns': ['coid', 'mdate', 'ac_r103', 'ac_r403']},
paginate = True,
chinese_column_name = True)
fin_data = fin_data.dropna()
本文這次將應用的財務資料為稅後ROE以及營業利益成長率,並假設要這兩項指標皆越大越好,其意涵如下:
稅後ROE:中文全稱為股東權益報酬率,也就是公司利用股東自有資本營利的能力。
營業利益成長率:首先營業利益率是公司營業利益佔營業收入的比率,也就是衡量公司本業營業效率的指標,而其成長率則是檢驗公司是否具有穩定成長的現象。
本文選擇這兩項指標是希望能夠在短中期的投資區間取得一個平衡,會這樣假設是因為考量到ROE雖然是衡量公司盈利能力的有力指標,但通常會受到產業淡旺季、公司資本結構變化的影響,所以將營業利益成長率作為公司營業本質的標準,減少ROE單一指標的不足。
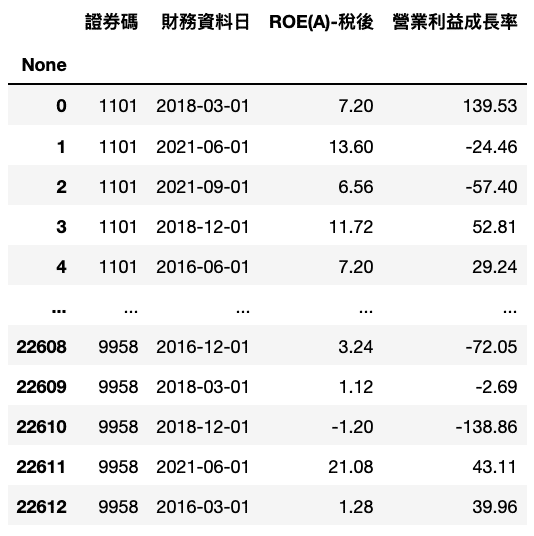
Step 3. 導入股價資料&資料合併
price_df = pd.DataFrame()
for i in pub_common_stk:
price_data = tejapi.get('TWN/APRCD',
coid = i,
mdate= {'gte': '2016-01-01', 'lte': '2021-12-31'},
opts={'columns': ['coid', 'mdate', 'close_d']},
paginate = True,
chinese_column_name = True
)
price_df = pd.concat([price_df, price_data], axis = 0)
導入符合標的之每日收盤價格。
def compare(df1, df2):
df2 = df2.rename(columns = {'證券碼':'證券代碼', '財務資料日':'年月日'})
compare = pd.merge(df1, df2, how='inner', on=['證券代碼', '年月日'])
result1 = pd.concat([compare['年月日'], compare['證券代碼']], axis = 1)
result2 = pd.merge(df1, result1, how='inner', on =['證券代碼', '年月日'])
return result2
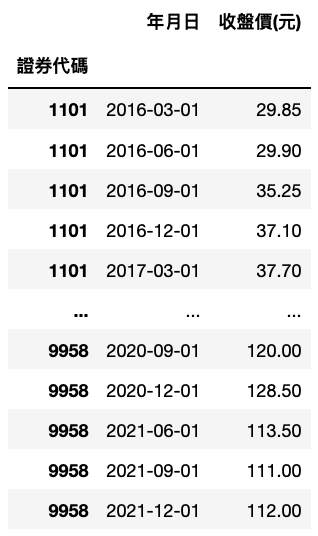
ret_df2 = compare(price_df, fin_data) ret_df2 = ret_df2.set_index(['證券代碼'])
合併財務資料表與股價資料,並只留下財務資料日期(轉換名稱為年月日)與價格資料,後續將計算每次財務資料揭示間的買入持有報酬。
Step 4. 計算報酬資料&資料最後整理
ret_df2['報酬%'] = pd.Series()
for i in ret_df2.index.values:
ret_df2.loc[i]['報酬%'] = pd.Series(ret_df2.loc[i]['收盤價(元)']).pct_change(1)*100
ret_df2 = ret_df2.dropna().reset_index()
這邊要注意,需要透過迴圈導入不同標的資料,分別計算報酬。不能直接對資料表取變動值,因為不同標的是直接疊在一起的,若是直接取變動值,則從第二項標的開始之首個報酬會跟前一項標的資料混在一起計算。
def compare2(df1, df2):
df2 = df2.rename(columns = {'證券碼':'證券代碼', '財務資料日':'年月日'})
compare = pd.merge(df1, df2, how='inner', on=['證券代碼', '年月日'])
return compare
data = compare2(ret_df2, fin_data).set_index(['證券代碼','年月日'])
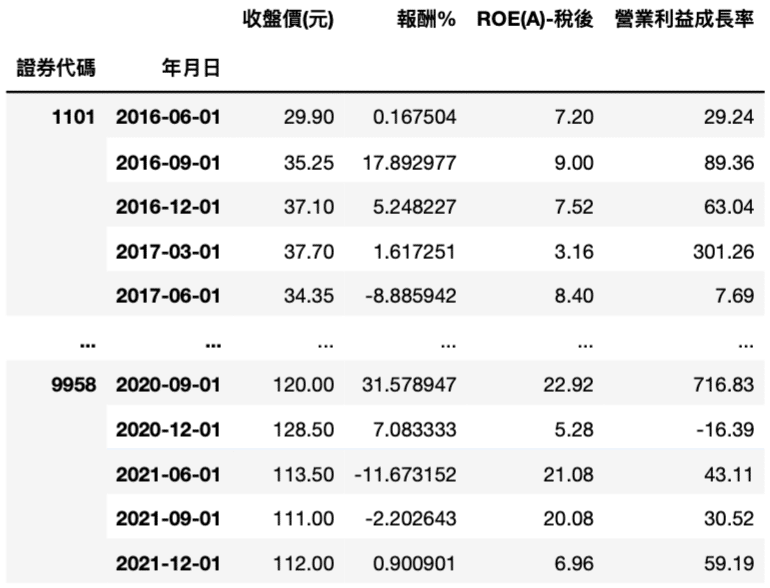
Step 5. 離群值處理
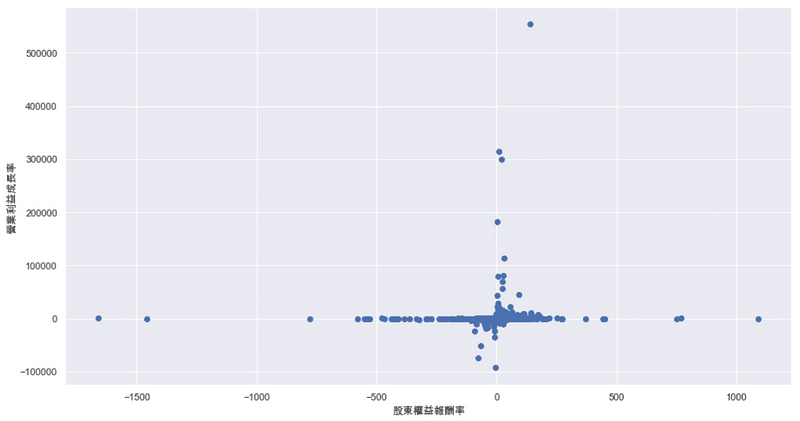
透過上圖可以發現,不論在ROE或是營業利益率兩方面的資料,皆有很嚴重的離群值現象,因此本文後續將以超出標準差為依據,將離群值從樣本中移除。(因應篇幅考量,此處理過程請詳見完整程式碼)
Step 6. 資料分配標準化
import sklearn.preprocessing as preprocessing
data_rmout = data_no.replace([np.inf, -np.inf], np.nan) data_rmout = data_no.dropna() data_std = pd.DataFrame(preprocessing.scale(data_no), index = data_no.index, columns = data_no.columns)
plt.figure(figsize=(15,8)) plt.hist(data_std['ROE(A)-稅後'], bins = 50) plt.hist(data_std['營業利益成長率'], bins = 50, alpha =0.7)
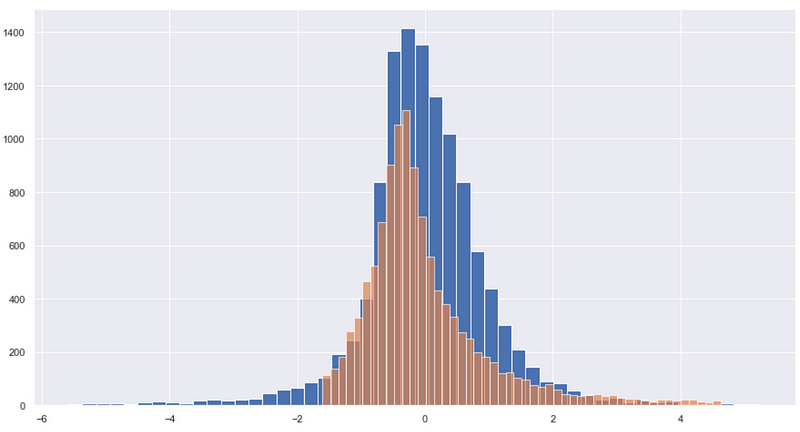
透過上圖可以清楚觀察到,兩項數據的分配已經通過標準化的程序,分佈情形相似。
Step 1. 資料分割
from sklearn.model_selection import train_test_split
data_train, data_test = train_test_split(data_std, test_size = 0.2, random_state = 0)
Step 2. 模型擬合
from sklearn.svm import SVC
cf = SVC( C=10.0, break_ties=False, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape='ovr', degree=3, gamma='scale', kernel='linear',max_iter=-1, probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False )
index = ['ROE(A)-稅後', '營業利益成長率']
cf.fit(data_train[index], data_train['報酬%'] > data_train['報酬%'].quantile(0.5))
在上方程式碼中可以看到本文使用的方法是線性結構,而也考量到線性結構可能會使模型太過簡單,所以設定分類錯誤的懲罰項係數為10,提高模型的複雜度;在模型擬合的指令中,本文則是設定標準為各樣本報酬率要大於中位數。
Step 3. 資料分類視覺化
from mlxtend.plotting import plot_decision_regions
index_plot = data_test[index].values labels_plot = (data_test['報酬%'] > data_test['報酬%'].quantile(0.5)).astype(int).values
plot_decision_regions(index_plot, labels_plot, cf)
plt.xlabel('股東權益報酬率')
plt.ylabel('營業利益成長率')
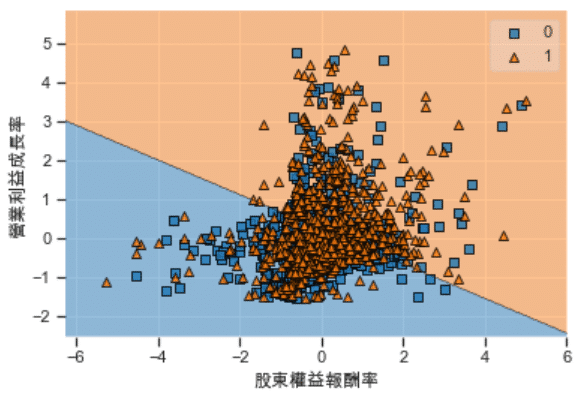
從圖中可以知道模型判斷ROE越高且營業利益成長率越高的樣本是具有增長潛力的,這與我們先前的假設相同。
Step 4. 檢驗結果
# TRAIN cf.score(data_train[index], data_train['報酬%'] > data_train['報酬%'].quantile(0.5))
# TEST cf.score(data_test[index], data_test['報酬%'] > data_test['報酬%'].quantile(0.5))
訓練資料集分數:0.5857
驗證資料集分數:0.5965
從上述結果瞭解兩項資料集的分數皆大於0.5,代表模型的有效性有一定基礎,並且驗證資料集分數略高訓練資料集也讓說明應該沒有過度擬合的情形。
上述的內文首先示範資料篩選以及前處理;接著進行模型的擬合、視覺化與檢驗。在資料處理階段,本文說明所選擇的財務資料及其背後意涵,若讀者有更偏好的資料,歡迎至TEJ資料庫中蒐集;隨後,在模型階段,本文挑選較簡單的線性結構,讓讀者了解基本的模型參數設定,並且通過視覺化模型所分析的結果,驗證「兩項指標皆越大越好的假設」,最後再計算訓練集與驗證集的分數,確定模型的效力。
本文至此為止,歡迎對於機器學習模型有興趣的讀者,持續關注本平台,後續會有更多文章說明其他應用;此外,也歡迎讀者選購 TEJ E Shop中的方案,相信讀者具有完整的資料庫後,讀者就能輕易練習建立自己模型。
