
Table of Contents
風險值的意思基本上就是根據給定的信賴水準以及某特定期間,投資組合可能產生的最大損失。本文計算過程如下:
在計算風險值的方面,需要注意各項參數的使用,以及資產報酬率的分佈情形,才能夠將真實的市場波動反映在計算數值上,後續本文將詳細說明完整的執行過程,以及本文所用的「變異數-共變異數法」在應用上的優缺點。
本文所用之風險值名詞如下:
1.每日盈餘風險(Daily Earning at Risk, DEAR):投資標的之單日風險值。
2.相對風險值(Relative VaR):投資標的相對於投資報酬率均值的風險值。
(|-α| * σ) * portfolio value
3.絕對風險值(Absolute VaR):投資標的相對於0的風險值。
(|-α| * σ – mean) * portfolio value
上述α皆為常態分配的臨界值,下文計算會使用99%信心水準的z值,2.33。
本文使用 MacOS 並以 Jupyter Notebook 作為編輯器
#基本套件import numpy as npimport pandas as pd#繪圖套件import matplotlib.pyplot as plt%matplotlib inlineimport seaborn as snssns.set()#TEJAPIimport tejapitejapi.ApiConfig.api_key = 'Your Key'tejapi.ApiConfig.ignoretz = True
本文投資組合以傳產、電子、金融及航運各一支標的組成;內文會搭配講解風險值計算的方法和各類型標的報酬率分佈情形,讓讀者更加了解風險值計算上的優缺點。
ticker = ['1476', '2330', '2882', '2603']# 儒鴻, 台積電, 國泰金, 長榮df = tejapi.get('TWN/EWPRCD', # 公司交易資料-已調整股價(收盤價)coid = ticker,mdate = {'gte':'20200101', 'lte':'20220225'},opts = {'columns': ['coid', 'mdate', 'close_adj']},chinese_column_name = True,paginate = True)df = df.set_index('日期')
data = {}for i in ticker:p = df[df['證券代碼'] == i]p = p['收盤價(元)']data.setdefault(i, p)data = pd.concat(data, axis = 1)
本文此處取用報酬率資訊表,確保資料來源的正確性,而資料處理過程與上述價格資料相同。
ret = tejapi.get('TWN/EWPRCD2',coid = ticker,mdate = {'gte':'20200101', 'lte':'20220225'},opts = {'columns': ['coid', 'mdate', 'roia']},chinese_column_name = True,paginate = True)ret = ret.set_index('日期')data2 = {}for i in ticker:r = ret[ret['證券碼'] == i]r = r['日報酬率(%)']data2.setdefault(i, r)data2 = pd.concat(data2, axis = 1)data2 = data2 * 0.01 #還原報酬率為百分之一單位基準
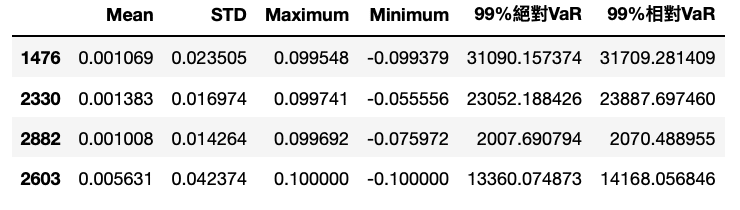
value = data.iloc[-1] * 1000Mean = []STD = []MAX = []Min = []abs_var = []re_var = []
首先,根據股價資料最後一日計算各項標的價值,本文是以至少持有一張股票為單位;接著,定義各項空list。
for i in ticker:v = data2[i].std() # Standard Errormean = data2[i].mean() # Meanmaximum = data2[i].max() # Maximumminimum = data2[i].min() # Minimum# Calculate 99% Absolute VaRvar_99_ab = (abs(-2.33)*v - mean) * value[i]# Calculate 99% Relative VaRvar_99_re = (abs(-2.33)*v) * value[i]# Append those values in listsMean.append(mean)STD.append(v)MAX.append(maximum)Min.append(minimum)abs_var.append(var_99_ab)re_var.append(var_99_re)
在迴圈中,先計算各項標的之標準差、平均數及最大最小值;再計算絕對風險值與相對風險值;最後將上述計算各數值回傳至相對應的list。
在風險值的計算中,首先看到本文取用abs(-2.33)為99%信心水準的臨界值,會使用abs()而非直接取用2.33是想提醒讀者:風險值考量的是投資組合下跌風險的價值,所以用-2.33,而風險值表達通常為「正數」,因此加上絕對值。
dear = pd.DataFrame({'Mean': Mean, 'STD': STD, 'Maximum': MAX, 'Minimum': Min, '99%絕對VaR': abs_var, '99%相對VaR': re_var},index = ticker)# 直接將DEAR命名為絕對、相對VaR,供後續計算使用
rho = data2.corr() # Apply ret to avoid spurious regression result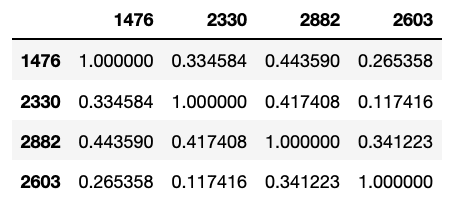
要運用報酬率資料取得標的間相關係數,而非價格資料,才能夠避免假性迴歸導致的錯誤相關係數。
# 將不需用到的資料剔除。dear = dear.drop(columns = ['Mean', 'STD', 'Maximum', 'Minimum'])# 合併 dear 與 rhoportfolio = pd.concat([dear, rho,], axis = 1)portfolio[['99%絕對VaR', '99%相對VaR']] = portfolio[['99%絕對VaR', '99%相對VaR']]
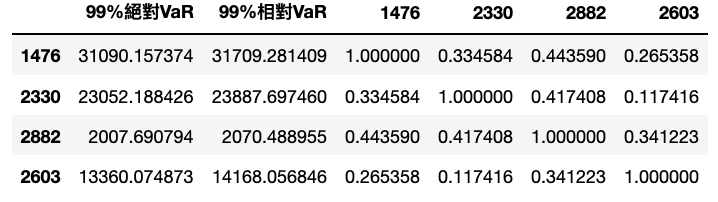
part1的部分是個別標的本身之風險值;part2則是標的間經相關係數調整的風險值。
part1 = sum(portfolio['99%絕對VaR']**2)part2 =2*portfolio.iat[0,3] * portfolio.iat[0,0] * portfolio.iat[1,0]+ 2*portfolio.iat[0,4] * portfolio.iat[0,0] * portfolio.iat[2,0]+ 2*portfolio.iat[0,5] * portfolio.iat[0,0] * portfolio.iat[3,0]+ 2*portfolio.iat[1,4] * portfolio.iat[1,0] * portfolio.iat[2,0]+ 2*portfolio.iat[1,5] * portfolio.iat[1,0] * portfolio.iat[3,0]+ 2*portfolio.iat[2,5] * portfolio.iat[2,0] * portfolio.iat[3,0]
99%信心水準之絕對風險值為50647.78。
part1 = sum(portfolio['99%相對VaR']**2)part2 =2*portfolio.iat[0,3] * portfolio.iat[0,1] * portfolio.iat[1,1]+ 2*portfolio.iat[0,4] * portfolio.iat[0,1] * portfolio.iat[2,1]+ 2*portfolio.iat[0,5] * portfolio.iat[0,1] * portfolio.iat[3,1]+ 2*portfolio.iat[1,4] * portfolio.iat[1,1] * portfolio.iat[2,1]+ 2*portfolio.iat[1,5] * portfolio.iat[1,1] * portfolio.iat[3,1]+ 2*portfolio.iat[2,5] * portfolio.iat[2,1] * portfolio.iat[3,1]
99%信心水準之相對風險值為52205.86。
根據上述的計算結果,可以推論此投資組合於單一交易日之最大損失金額有99%的機率不會超過5萬2千元;然而,再經過一段時間,市場也會有所變化,因此需要再次計算風險值,才能更準確的評估部位風險。
以下將呈現投資標的之報酬率分配圖,查驗各標的厚尾現象的嚴重程度。
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']fig, ax =plt.subplots(figsize = (18, 12), nrows = 2, ncols = 2)data2['1476'].plot.hist(ax=ax[0][0], bins = 100,range=(data2['1476'].min(), data2['1476'].max()), label = '儒鴻')ax[0][0].legend(loc = 2, fontsize = 30)data2['2330'].plot.hist(ax=ax[0][1], bins = 100,range=(data2['2330'].min(), data2['2330'].max()), label = '台積電')ax[0][1].legend(loc = 2, fontsize = 30)data2['2882'].plot.hist(ax=ax[1][0], bins = 100,range=(data2['2882'].min(), data2['2882'].max()), label = '國泰金')ax[1][0].legend(loc = 2, fontsize = 30)data2['2603'].plot.hist(ax=ax[1][1], bins = 100,range=(data2['2603'].min(), data2['2603'].max()), label = '長榮')ax[1][1].legend(loc = 2, fontsize = 30)plt.tight_layout()
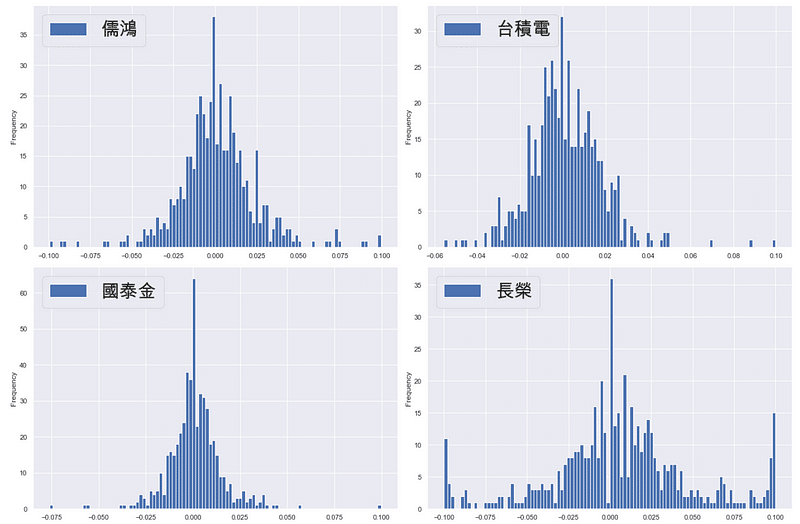
由上圖可以了解,長榮的厚尾現象最為嚴重,而台積電與儒鴻也有厚尾的現象,國泰金則比較不明顯。
根據本文前述的計算以及分析,相信讀者可以明白風險值(變異數-共變異數法)的計算流程:首先,計算個別標的之每日盈餘風險;接著,計算標的間相關係數;最後,計算整體投資組合的風險值。當然,在文末,本文也說明此方法的局限性,首先是針對線性證券資產;其次為「厚尾」問題,而通過圖表的呈現,讀者也可以了解文中四項標的資產確實具有厚尾現象,至於此問題要如何解決,請持續關注本平台,後續會有其他文章說明。最後,歡迎讀者選購 TEJ E Shop中的方案,就能夠輕鬆地對自己的投資組合進行風險值計算。
