
Table of Contents
大部分的人在決定自己的投資組合該怎麼分配權重時,常常沒有一個依據,而諾貝爾經濟學得獎者 Harry Markowitz 提出一個理論,依據股票的波動度和彼此的相關性,根據不同的權重設定,找到一條「總風險相同時,相對上可獲得最高之預期報酬率」,如此一來就可以根據自己的風險承受度去選擇投資組合的權重分配了!
本文使用 Mac OS 並以 Jupyter Notebook 作為編輯器
# 基礎 import numpy as np import pandas as pd # 繪圖 import matplotlib.pyplot as plt import matplotlib import plotly.express as px import plotly.graph_objects as go # API import tejapi tejapi.ApiConfig.api_key = 'Your Key' tejapi.ApiConfig.ignoretz = True
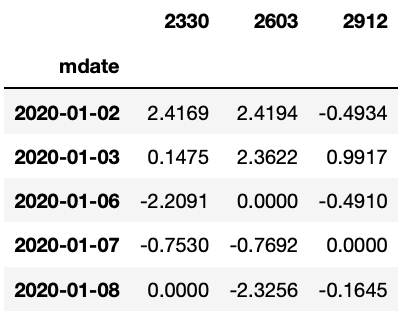
Step 1. 撈我們以台積電(2330)、 長榮(2603)、統一超商(2912) 作為投資組合的範例,日期選定 2020 年度,欄位選擇報酬率 roi。
data = tejapi.get('TRAIL/TAPRCD',
coid=['2330', '2603', '2912'],
mdate={'gte': '2020-01-01', 'lte': '2020-12-
31'},
opts={"sort": "mdate.desc", 'columns': [
'coid', 'mdate', 'roi']},
paginate=True)
Step 2. 重設索引值、資料轉置、欄位以股票代號命名
data = data.set_index('mdate')
returns = data.pivot(columns='coid')
returns.columns = [columns[1] for columns in returns.columns]
Step 3. 計算平均報酬、共變異數矩陣
mean_returns = returns.mean() cov_matrix = returns.cov()

接下來我們要隨機產生投資組合權重,利用大量模擬進而找出效率前緣,我們要針對每一個投組紀錄他的報酬率、標準差、權重,我們定義兩組函數。
def portfolio_performance(weights, mean_returns, cov_matrix):
returns = np.sum(mean_returns*weights )
std = np.sqrt(np.dot(weights.T, np.dot(cov_matrix, weights)))
return std, returns
我們要模擬的投資組合數量
num_portfolios = 5000
將函數在放入隨機投組計算函數裡,計算每一個投資組合的數據
def random_portfolios(num_portfolios, mean_returns, cov_matrix):
results = np.zeros((3,num_portfolios))
weights_record = []
for i in range(num_portfolios):
weights = np.random.random(len(coid))
weights /= np.sum(weights)
weights_record.append(weights)
portfolio_std_dev, portfolio_return =
portfolio_performance(weights, mean_returns, cov_matrix)
results[0,i] = portfolio_std_dev
results[1,i] = portfolio_return
results[2,i] = (portfolio_return) / portfolio_std_dev
return results, weights_record
開始模擬,並將結果存入 results 和 weights_record
results = np.zeros((3,num_portfolios))
weights_record = []
for i in range(num_portfolios):
weights = np.random.random(len(coid))
weights /= np.sum(weights)
weights_record.append(weights)
portfolio_std_dev, portfolio_return =
portfolio_performance(weights, mean_returns, cov_matrix)
results[0,i] = portfolio_std_dev
results[1,i] = portfolio_return
results[2,i] = (portfolio_return) / portfolio_std_dev

視覺化,鼠標跳出的文字框,第一個數字代表風險,第二個數字代表報酬,第二行數組代表投資的權重。
def protfolios_allocation(mean_returns, cov_matrix,
num_portfolios):
results, weights = random_portfolios(
num_portfolios, mean_returns, cov_matrix)
fig = go.Figure(data=go.Scatter(x=results[0, :],
y=results[1, :],
mode='markers',
text = weights_record,
))
fig.update_layout(title='投資組合表現分佈',
xaxis_title="投資組合總風險",
yaxis_title="預期平均報酬率",)
fig.update_xaxes(showspikes=True,spikecolor="grey",
spikethickness=1, spikedash='solid')
fig.update_yaxes(showspikes=True,spikecolor="grey",
spikethickness=1, spikedash='solid')
fig.show()
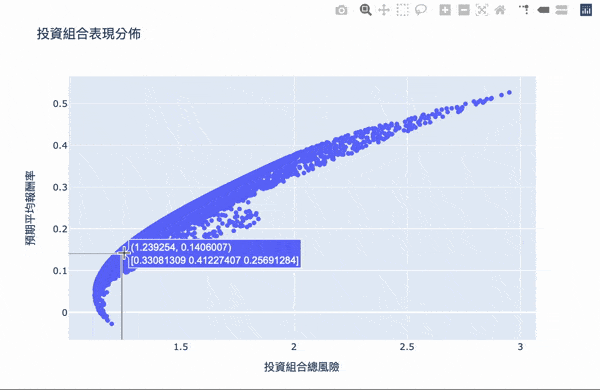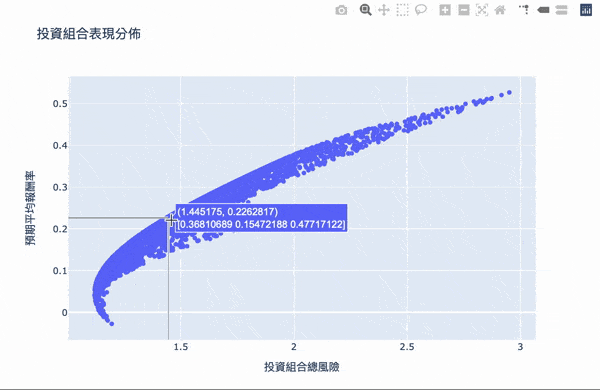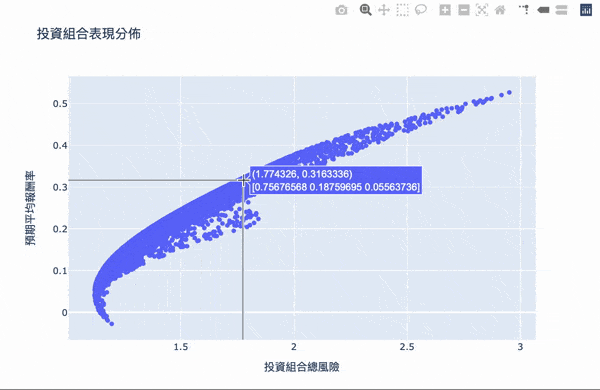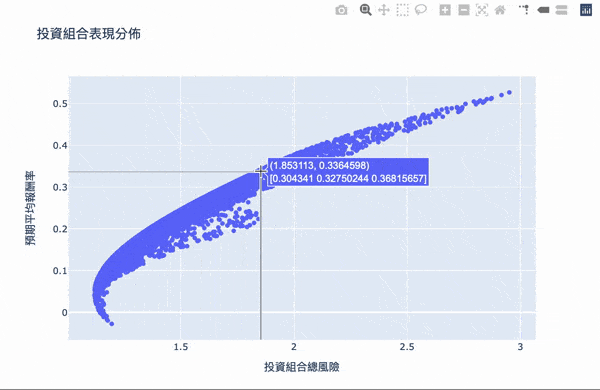
我們要找兩個條件:
這類的條件相當於尋找極值,我們可以利用 scipy 模組下的 optimize 來計算最小值
import scipy.optimize as sco
這裡定義四個計算的函數
1.風險函數
代入權重計算出報酬和標準差
def portfolio_volatility(weights, mean_returns, cov_matrix): return portfolio_performance(weights,mean_returns, cov_matrix)[0]
2. 風險最小投資組合
我們使用 scipy 模組下的 optimize 計算在權重 0 ~ 1 限制下,取風險函數下的極值,演算法選擇 SLSQP( Sequential Least Squares Programming) 非線性規劃
fun:優化的目標函數
args:目標函數可設定的參數
method:選用的優化算法
bounds:每一個x的取值範圍
constraints:優化的約束條件,輸入為字典組成的元組,字典主要由 ‘type‘ 和 ‘fun‘ 組成,type可選 ‘eq‘ 和 ‘ineq‘,分別是等式約束和不等式約束,fun是對應的約束條件,可為lambda函數。
def min_variance(mean_returns, cov_matrix):
num_assets = len(mean_returns)
args = (mean_returns, cov_matrix)
constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x) - 1})
bound = (0,1)
bounds = tuple(bound for asset in range(num_assets))
result = sco.minimize(portfolio_volatility, num_assets*
[1/num_assets,], args=args,
method='SLSQP', bounds=bounds,
constraints=constraints)
return result
3. 同報酬率下風險最小投組
主要為約束條件上的差異,報酬要限制在固定數字,求風險極小值
def efficient_return(mean_returns, cov_matrix, target):
num_assets = len(mean_returns)
args = (mean_returns, cov_matrix)
def portfolio_return(weights):
return portfolio_performance(weights, mean_returns,
cov_matrix)[1]
constraints = ({'type': 'eq', 'fun': lambda x:
portfolio_return(x) - target},
{'type': 'eq', 'fun': lambda x: np.sum(x) - 1})
bounds = tuple((0,1) for asset in range(num_assets))
result = sco.minimize(portfolio_volatility, num_assets*
[1/num_assets,], args=args,
method='SLSQP', bounds=bounds,
constraints=constraints)
return result
4. 組合效率前緣的樣本
def efficient_profolios(mean_returns, cov_matrix, returns_range):
efficients = []
for ret in returns_range:
efficients.append(efficient_return(mean_returns,
cov_matrix, ret))
return efficients
視覺化,方法同投組視覺化,再另外加上最小風險投組和效率前緣
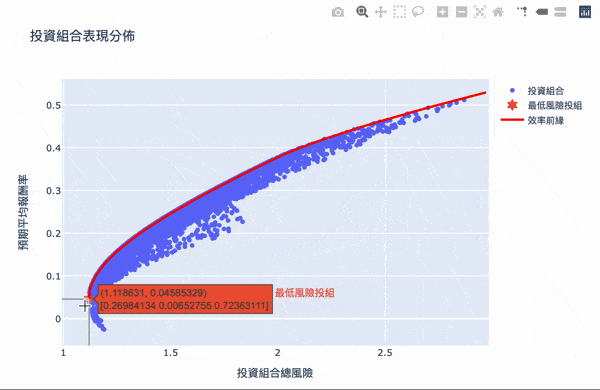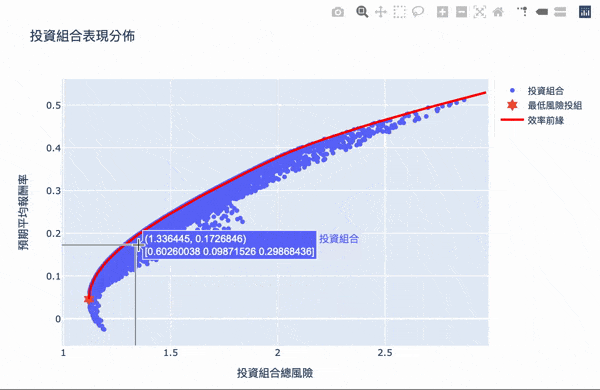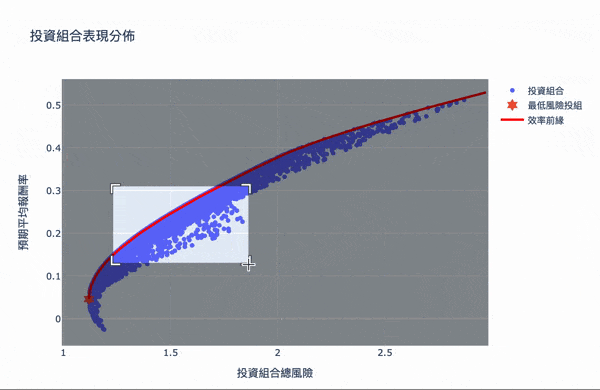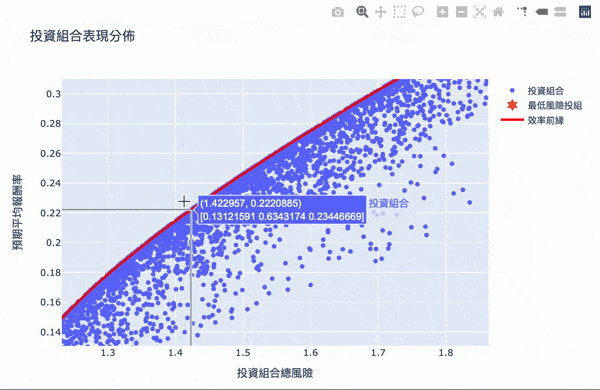
效率前緣整體架構其實不難理解,利用大量的模擬計算,求得效率的權重投資,可以設定自己想要的預期報酬,選擇風險最小的投資組合,Plotly 互動式圖表讓我們可將鼠標移至圖點上,就會顯示當下投資組合的權重分配,當然萬年不變的道理:「高報酬高風險」,想要更高的投資報酬率,需要承擔更大的風險波動,如果對演算法有興趣的讀者,可以詳閱官方文件,而此權重的結果,是根據選擇資料庫的時間,當時股票的波動度,所以獲得的效率前緣是會隨著時間不斷變化,故一段時間需要調整權重分配。
