Table of Contents
員工流動率是指企業在一定時期內因員工的離職和新進而發生的人力資源變動情況。這個指標是衡量企業組織和員工隊伍穩定性的重要概念。較低的員工流動率表示公司的人事變動相對較少,反映出企業內部的穩定性和持續性。相反,較高的員工流動率可能暗示著組織問題、工作不滿意度或其他因素,可能對企業運營和工作氛圍產生負面影響。監控員工流動率能夠幫助企業了解和評估其人力資源管理策略的有效性,並採取相應的措施來提高員工保留和滿意度,確保組織的長期穩定和發展,而預測員工流動率使企業能夠更好地規劃和管理人力資源,降低成本,提高人才保留率,並促進組織效能的提升。
本文使用 MacOS 作業系統以及 Jupyter Notebook 作為編輯器
# 載入所需套件
import pandas as pd
import numpy as np
import tejapi
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import statsmodels.regression.linear_model as sm
import matplotlib.pyplot as plt
# 登入TEJ API
api_key = 'YOUR_KEY'
tejapi.ApiConfig.api_key = api_key
tejapi.ApiConfig.ignoretz = True本次實作使用的欄位如下,請注意 violate_times 並不是原本資料表中的欄位,是經過前處理後產生的欄位。
gte, lte = '2021-01-01', '2021-12-31'
TR = tejapi.get('TWN/ACSR01A',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)
gte, lte = '2020-01-01', '2021-01-01'
ED = tejapi.get('TWN/AXEMPA',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)
gte, lte = '2020-01-01', '2021-01-01'
LAW = tejapi.get('TWN/ACSR20A',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)
gte, lte = '2021-01-01', '2021-12-31'
TWSE = tejapi.get('TWN/ACSR19A',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)我們篩選教育程度、TWSE 公司治理評鑑資料表中所需要的欄位,並計算違反勞動基準法次數。接著,由於TWSE 公司治理評鑑資料表中的公司代碼為數字會導致合併錯誤,因此要先轉換成字串型態。
ED = ED[["coid", "apct", "bpct" ,"cpct", "dpct", "epct", "fpct" , "emp_sum"]]
LAW = pd.DataFrame(data = [Counter(LAW["coid"]).keys(), Counter(LAW["coid"]).values()]).T.rename(columns = {0:"coid", 1:"violate_times"})
TWSE = TWSE[["coid", "rating"]]
TWSE["coid"] = TWSE["coid"].astype(str)df_main = TR
for i in [ED, TWSE, LAW]:
df_main = pd.merge(df_main, i, on = "coid")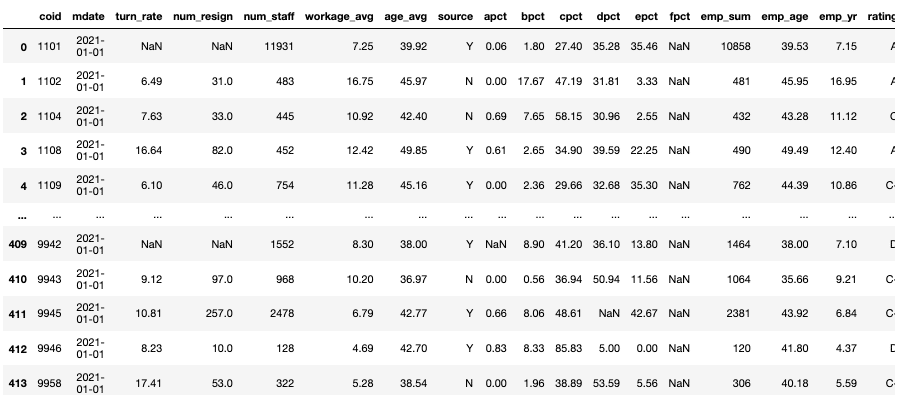
由於資料表中有空值,會導致無法訓練回歸模型,但請注意,將空值補 0 並不一定是最好的方法,空值應該要如何填補根據數據資料、預期結果的不同有許多處理方法,由於此次實作著重的點是模型建立,因此我們將空值補 0 以利計算。
接著,我們將治理評鑑等級由字串型態轉換為數值型態以符合回歸分析模型的輸入。
dataset_regression = df_main[df_main["turn_rate"].notna()].drop(columns = ["source", "fpct"])
dataset_regression["rating"].unique()
trans = {
"A+":"7",
"A":"6",
"B":"5",
"C":"4",
"C-":"3",
"D":"2",
"D-":"1",
"NA":"0",
}
dataset_regression["rating"] = dataset_regression["rating"].apply(lambda x : trans.get(x))
dataset_regression = dataset_regression.fillna(0)X = dataset_regression.iloc[:, 3:].values
y = dataset_regression.iloc[:, 2].values我們將資料以 8 : 2 的比例切分成訓練集與測試集,並且設定 random_state 以保證每次模型執行結果不變。
將測試集放入模型後,我們把實際值與模型預測值拿出來比較。
x_train, x_test, y_train, y_test= train_test_split(X, y, test_size=0.8, random_state=42)
regressor = LinearRegression()#創建一個名為regressor的物件
regressor.fit(x_train, y_train)#訓練線性歸模型
y_pred = regressor.predict(x_test)
print(y_pred.shape)#y_pred 為一維向量
np.set_printoptions(precision = 2)#顯示兩位小數
P_vs_T = np.concatenate((y_pred.reshape(len(y_pred),1),y_test.reshape(len(y_test),1)),1)
print(P_vs_T)
#將y_pred與y_test分別轉為len(y_pred),1)的2維陣列後合併
透過觀察數值,可以發現有部分預測數值誤差不小,甚至有負數的情況,為了清楚了解數值預測結果到底準不準確,我們使用長條圖方便理解,並定義當預測值與實際值相差超過 2% 時,判定為預測失準。
classification = [1 if abs(x-y)>1 else 0 for x,y in P_vs_T ]
print(Counter(classification))
plt.bar(x = [0,1], height = Counter(classification).values(),tick_label=["False", "True"] )
plt.show()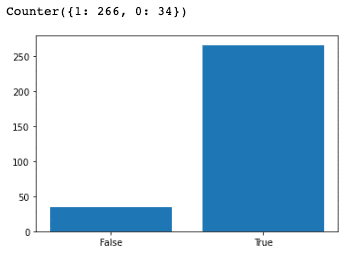
然而透過圖表我們可以發現模型的結果整體上還是不錯的,擁有 88% 的準確率。
#輸出模型截距與係數
print(regressor.fit(x_train,y_train).intercept_)
print(regressor.fit(x_train,y_train).coef_)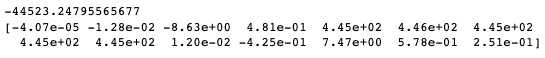
反向淘汰法是一種特徵選擇的方法,用於從模型中排除對目標變量沒有顯著影響的特徵。它通過逐步剔除變量,從最初的全模型開始,每次移除對模型效能影響最小的特徵,直到剩下的特徵達到一定的標準(例如顯著性水平,一般來說是當 p-value 小於 0.05 時)。這種方法可防止過度擬合和降低模型複雜度,同時提高模型的解釋性和預測能力。反向淘汰在多元線性回歸中被廣泛應用,以篩選出對目標變量最具影響力的特徵。
而為何標準會是 p-value < 0.05 ,這就要講到統計學中的假設檢定。
假設檢定(Hypothesis testing)是統計學中的一種方法,用於對關於母體參數的假設進行統計推論。在假設檢定中,我們提出兩個對立的假設,分別是「虛無假設」(null hypothesis)和「對立假設」(alternative hypothesis)。通常,虛無假設表示無效、沒有差異或沒有關聯,而對立假設則表示有效、有差異或有關聯。
透過收集樣本數據並進行統計分析,我們使用檢定統計量來評估這些數據對於虛無假設的支持或反駁。通過計算檢定統計量的值並將其與預先設定的顯著性水平進行比較,我們可以進行結果的統計判斷。如果檢定統計量的值極端地偏離了虛無假設,我們可能拒絕虛無假設,並提出對立假設。否則,我們則無法拒絕虛無假設。
而 p-value 表示獲得觀察結果或更極端結果的概率,假設虛無假設為真。當p-value小於預先設定的顯著性水平(通常為0.05)時,我們可以拒絕虛無假設。這是因為小於0.05的 p-value 表示觀察到的結果非常罕見,根據虛無假設的假設條件,我們無法輕易獲得這樣極端的結果。因此,拒絕虛無假設意味著我們有足夠的證據支持對立假設的成立。
然而,值得注意的是,0.05 只是一個通常使用的顯著性水平。在某些情況下,根據研究的特性或問題的嚴重性,可以選擇更嚴格的顯著性水平(例如0.01)。此外,應該綜合考慮其他因素,如樣本大小、研究設計和效應大小等,來做出適當的統計判斷和解釋結果。拒絕虛無假設只是統計推論的一部分,需要謹慎地解釋和報告結果,避免過度解讀或誤導性的結論。
我們透過 for 迴圈來逐步剔除參數,並且保留準確率最高的模型資訊。
# 加上常數1以符合回歸模型 y = b0+b1*X+b2*X^2+b3*X^3...
x_train = np.append(arr = np.ones((len(x_train[:,1]),1)).astype(int), values = x_train, axis = 1)
# back elimination
col = [0,1,2,3,4,5,6,7,8,9,10,11,12,13]
R_square = []
for i in range(len(col)):
x_opt=np.array(x_train[:,col], dtype=float)
regressor_OLS=sm.OLS(endog=y_train, exog= x_opt).fit()
R_square.append(regressor_OLS.rsquared)
if regressor_OLS.rsquared == max(R_square):
summary = regressor_OLS.summary()
attribute = col.copy()
P = regressor_OLS.pvalues.tolist()
print(col)
col.pop(P.index(max(P)))

我們將每次淘汰參數後的 r-squared 值以折線圖呈現,r-squared 是一個統計量,用於評估回歸模型對因變量變異性的解釋程度。它表示因變量的變異百分比可以由獨立變量(自變量)在模型中解釋。r-squared 值的範圍從 0 到 1 ,越接近 1 表示模型能夠更好地解釋因變量的變異性,而越接近0則表示模型的解釋能力較弱。具體來說,r-squared 為 0 意味著模型無法解釋因變量的變異性,而 r-squared 為 1 則表示模型完全解釋了因變量的變異性。
plt.plot(R_square,'ro--', linewidth=2, markersize=6)
plt.xticks(ticks = [i for i in range(0,14)], labels= [i for i in range(1,15)][::-1])
plt.title("change in R_square")
plt.xlabel('number of attribute')
plt.ylabel('R_square')
plt.show()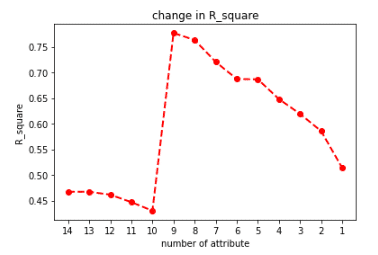
我們擷取 r-squared 最高時的參數並將對應的欄位名稱打印出來。
col_map = dict(zip([0,1,2,3,4,5,6,7,8,9,10,11,], dataset_regression.iloc[:, 3:].columns))
print(attribute)
print(list(map(lambda x:col_map.get(x), attribute)))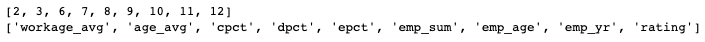
查看 r-squared 最高時的統計訊息。
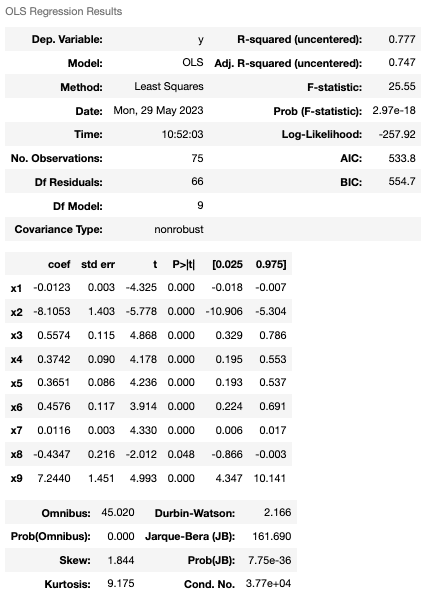
透果反向淘汰,我們成功地將模型準確由一開始的 46% 提升至 77%,並且通過分析參數組成,可以發現公司員工流動率主要是受到公司員工的年資、薪水及大學以下教育程度人數比例影響。然而,這些結論都只是基於統計原理的解釋,r-squared 的解釋應該與具體情況和模型的特點相結合。它可以幫助評估模型的適合度和預測能力,以及比較不同模型之間的優劣。因此,需要謹慎使用 r-squared,並結合其他評估指標和專業判斷進行綜合分析,以充分理解模型的解釋能力和限制。
