
Table of Contents
倖存者偏差(Survivorship bias)是指在研究或觀察中,只有成功或倖存下來的事物或個體被考慮,而那些失敗或消失的事物或個體被忽略或排除在外的一種誤差。這種偏差可能導致對整體情況的誤解,因為僅僅觀察到成功或倖存下來的事物可能並不代表整個群體的特徵或真實情況。
倖存者偏差通常出現在樣本選取、研究設計或回顧性分析等情境中。一個典型的例子是二戰期間對飛機防禦加強的研究。當時研究人員主要觀察到返回基地的飛機上的損傷情況,然後根據這些觀察結果提出防禦建議。然而,這種觀察忽略了那些被擊落且無法返回的飛機,因此得出的結論可能並不適用於整個飛機群體。
倖存者偏差在選股時也可能產生影響,在選股過程中,投資者傾向於關注那些表現出色且獲利的股票,而忽略那些表現不佳或失敗的股票。這種觀察只看到成功股票的例子,導致對整個市場或股票群體的情況產生了偏差。
倖存者偏差會使投資者誤以為那些表現出色的股票具有普遍性或代表性,並認為它們的成功是由於特定的因素或策略所導致。投資者可能傾向於追逐這些成功股票,而忽略了市場風險、行業趨勢和其他重要的選股因素。本次實作將使用簡單的交易策略來具體說明何謂倖存者偏差。
本文使用Mac OS並以jupyter作為編輯器
import pandas as pd
import numpy as np
import tejapi
api_key = 'your_api_key'
tejapi.ApiConfig.api_key = api_key
tejapi.ApiConfig.ignoretz = True資料期間從 2020–01–01 至 2022–12–31,以生技醫療類股作為實例,抓取股價資訊作為分析資料。
comp_data = tejapi.get('TWN/ANPRCSTD',
paginate = True,
opts = {"columns":["coid", "mdate", "mkt", "stype", "list_date", "delis_date", "tseind"]}
)
#取得生技醫療類股代號,類別代碼為22
coid_lst = list(comp_data.loc[(comp_data["stype"] == "STOCK") & (comp_data["tseind"] == "22")]["coid"])
gte, lte = "2020-01-01", "2022-12-31"
price_data = tejapi.get('TWN/AAPRCDA',
paginate = True,
coid = coid_lst,
mdate = {"gte":gte, "lte":lte},
opts = {"columns":["coid", "mdate", "fld014", "cls60", "close_d"]}
)證券屬性資料表中顯示了當前標的狀態是否為下市櫃,而上市(櫃)調整股價(日)-均價資料表則包含了所有曾經上市櫃公司的股價資訊,為了取得兩張資料表中共有的股票代號,我們首先將上市(櫃)調整股價(日)-均價資料表中的股票代碼型態轉換為字串,在使用set取得交集,並以此結果來過濾股價資料。
price_data["coid"] = price_data["coid"].astype(str)
inter_coid = list(set(coid_lst).intersection(set(price_data["coid"].unique())))
price_data[price_data["coid"].isin(inter_coid)]
本次實作我們取用最簡單的均線回測,將短期均線與長期均線進行比較,當短期均線向上突破長期均線時,稱為「黃金交叉」,視為買進的訊號。而當短期均線向下突破長期均線時,則稱為「死亡交叉」,視為賣出的訊號。為求計算方便,本交易策略每當觸發交易訊號時,除非該筆價格為標的價格資訊的最後一筆,也就是最後一天才會執行平倉,否則皆只會交易一單位的股票。本次實作以 10 日均線作為短期均線,60日均線作為長期均線。
首先,我們將股價資料依照股票代碼進行分組。
fltr_price_data = price_data[price_data["coid"].isin(inter_coid)]
group = fltr_price_data.groupby("coid")接著定義均線交易策略的函式,該函式最終會返回兩項資料,第一是交易歷程的資料表,其中包含交易日期、標的代號、買入/賣出標示、交易股價、交易單位、剩餘現金及持有部位,第二是交易結束後剩餘的現金量。
def MA_strategy(df, principal):
position = 0
lst = []
for i in range(len(df)):
if df["fld014"].iloc[i] > df["cls60"].iloc[i] and principal >= float(df["close_d"].iloc[i])*1*1000:
principal -= float(df["close_d"].iloc[i])*1*1000
position += 1
lst.append({
"日期": df["mdate"].iloc[i],
"標的": df["coid"].iloc[i],
"買入/賣出": "買入",
"單價": float(df["close_d"].iloc[i]),
"單位": 1,
"剩餘現金": principal,
"部位" : position
})
elif df["fld014"].iloc[i] < df["cls60"].iloc[i] and position > 0:
principal += float(df["close_d"].iloc[i])*1*1000
position -= 1
lst.append({
"日期": df["mdate"].iloc[i],
"標的": df["coid"].iloc[i],
"買入/賣出": "賣出",
"單價": float(df["close_d"].iloc[i]),
"單位": 1,
"剩餘現金": principal,
"部位" : position
})
elif i == len(df)-1 and position > 0:
principal += float(df["close_d"].iloc[i])*position*1000
position -= position
lst.append({
"日期": df["mdate"].iloc[i],
"標的": df["coid"].iloc[i],
"買入/賣出": "賣出",
"單價": float(df["close_d"].iloc[i]),
"單位": position,
"剩餘現金": principal,
"部位" : position
})
df_output = pd.DataFrame(lst)
return (df_output, principal)由於本次實作主要目的是為了顯示股市中存在倖存者偏差,因此在本次交易策略上並不執著於完全符合現實層面的操作及配置,而是將整個交易策略作為自變數、投資組合設定為控制變數、所反應的投資報酬率為應變數,在這裏我們給定每隻標的都擁有相同的本金,並設定本金為 100 萬元。
我們將在 2020–01–01 至 2022–12–31所有曾經存在的醫療生技業上市櫃公司作為投資組合
print(f'2020–01–01 至 2022–12–31狀態曾經為上市櫃的公司數量:{len(list(comp_data.loc[(comp_data["coid"].isin(inter_coid))]["coid"]))}')
principal = 1000000
total_return_1 = 0
df = pd.DataFrame(columns = ["日期", "標的", "買入/賣出", "單價", "單位", "剩餘現金", "部位"])
for g in group.groups.keys():
reuslt = MA_strategy(group.get_group(g), principal)
total_return_1 += round(reuslt[1], 2)
df = pd.concat([df, reuslt[0]], ignore_index=True)接下來進行 ROI 計算,將每檔標的的最終剩餘現金加總,除以初始金額,也就是 100 萬 * 投組標的數量。
total_return = (total_return_1/(1000000*len(group.groups.keys())) - 1) *100
print(f"ROI : {total_return}%")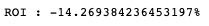
計算結果總績效為 -14 %,接著剔除在 2020–01–01 至 2022–12–31之間下市櫃的九家公司。在證券屬性資料表中,欄位 ”mkt” 為 “DIST”即代表目前狀態為下市櫃公司,我們以此作為資料篩選的依據。
如同之前的步驟對過濾後的股價資料依照股票代碼進行分組。
without_dist_coid = comp_data.loc[(comp_data["coid"].isin(inter_coid)) & (comp_data["mkt"] != "DIST")]["coid"].unique()
fltr_price_data = price_data[price_data["coid"].isin(without_dist_coid)]
group = fltr_price_data.groupby("coid")接著一樣執行交易策略
principal = 1000000
total_return_2 = 0
df_without_dist = pd.DataFrame(columns = ["日期", "標的", "買入/賣出", "單價", "單位", "剩餘現金", "部位"])
for g in group.groups.keys():
reuslt = MA_strategy(group.get_group(g), principal)
total_return_2 += round(reuslt[1], 2)
df = pd.concat([df_without_dist, reuslt[0]], ignore_index=True)return_without_dist = (total_return_2/(1000000*len(group.groups.keys())) - 1) *100
print(f"ROI : {return_without_dist}%")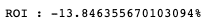
根據計算,剔除下市櫃公司後的績效確實與原本績效相比更好一點,雖然兩者績效皆為負數,但透過程式實作,我們可以明確發現其中的報酬率存在差異。
一般投資者在進行績效回測時都會選取在回測時間區段內存活的公司,而忽略了再回測區段中下市櫃的公司也應當列入考慮。而存活下來的公司體質在客觀層面上就較為優秀,因而使模型產生了較好的投資報酬率,但這樣的結果並不準確也並不全面,應當納入下市櫃公司的股價資訊才能更完善的反應當時市場的情形。
倖存者偏差可能導致選股策略的過度優化。如果投資者僅基於過去成功股票的特定因素來選股,而忽略了整體市場的變化和不確定性,則可能無法應對市場的變化,從而影響投資結果。為了避免倖存者偏差對選股的負面影響,投資者應該採取全面的研究方法,包括考慮成功和失敗股票的情況。他們應該關注整體市場的趨勢、行業的發展、公司的基本面和風險管理等因素,而不僅僅依賴於過去成功股票的表現。此外,投資者應該擁有長期的投資視野,避免過度關注短期的股票表現,並建立自己的投資策略,以符合個人的投資目標和風險承受能力。
溫馨提醒,本次策略與標的僅供參考,不代表任何商品或投資上的建議。之後也會介紹使用 TEJ 資料庫來建構各式指標,並回測指標績效,所以歡迎對各種交易回測有興趣的讀者,選購TEJ E-Shop的相關方案,用高品質的資料庫,建構出適合自己的交易策略。
● TEJ API 資料庫首頁
● TEJ E-Shop 完整資料庫購買
