Table of Contents
近幾年來,機器學習(Machine Learning, ML)、深度學習(DL)和人工智慧(AI)的已在各產業獲得廣泛的應用,如圖像辨識、語音辨識等功能已在現實生活中普及化,在你我的生活環境中隨處可見。
而在金融領域上,早已有演算法工程師和計量交易員等職位,世界金融的中心華爾街更是大量招募統計學家、數學家和物理學家來開發交易策略,金融專業的跨領域結合,從著名的選擇權定價模型(Black-Scholes Model, BS model )就可以看見,該模型運用了物理學上的布朗運動來量化每日價格的波動,儘管該模型的假設存在一些缺陷,仍舊在當時獲得諾貝爾經濟學獎的殊榮,由此便能看出BS model在學術以及實務上的貢獻。
本集將帶領大家一窺機器學習的世界,介紹如何運用機器學習來預測市場~
線性回歸是在資料點中找出規律、畫出一條直線的專業說法,而在簡單線性回歸中,我們只需要決定自變數(x)與應變數(y),或更直接一點,舉例來說,我今天想用今日報酬率預測明日的報酬率,根據這個目的,我們的自變數(x)為今日報酬率,應變數(y)為明日的報酬率。
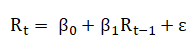
根據上面的回歸方程式我們可以在圖形上找到一條線,使得圖形上每個點到這條線的平均距離最小,也就是求使均方誤差(mean square error)最小的參數組合( β0, β1),下圖為理想中的情況。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn')
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei']
import tejapi
tejapi.ApiConfig.api_key = 'your key'
tejapi.ApiConfig.ignoretz = True
撈取 聯發科( 2454) 的日資料,斜槓方案的證券交易資料表(TWN/EWPRCD),可撈取除權息股價,報酬率資訊表(TWN/EWPRCD2)則可撈取日報酬率。
data = tejapi.get('TWN/EWPRCD',
coid='2454',
paginate = True,
chinese_column_name = True
)
return_ = tejapi.get('TWN/EWPRCD2',
coid='2454',
paginate = True,
chinese_column_name = True
)
data['報酬率%'] = return_['日報酬率(%)']
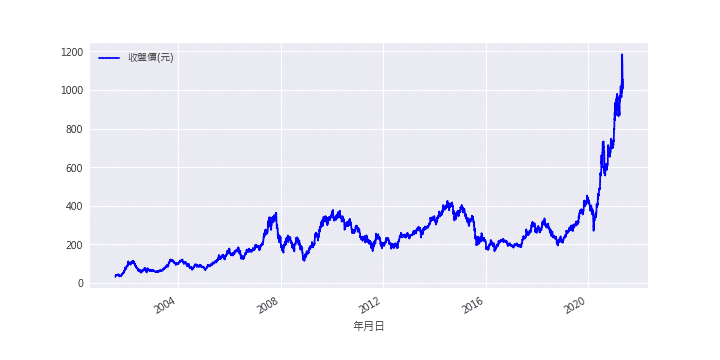
由下圖可看出,股價隨時間推移不斷上漲,股價有明顯向上的趨勢,故為非定態資料(有明顯趨勢),若直接將前一日股價當作 X,當日股價當作 Y,去跑回歸,即使結果是顯著的,也只是乍看之下有相關,屬於統計上的巧合,被稱為假性回歸(參考資料)。
⏰ 發現股價為非定態資料後,常見的解決方法為:
一階差分即是去求算股價報酬率,經過一階差分後,資料看起來已明顯地去趨勢化,此時就可以將資料帶入回歸模型當中了
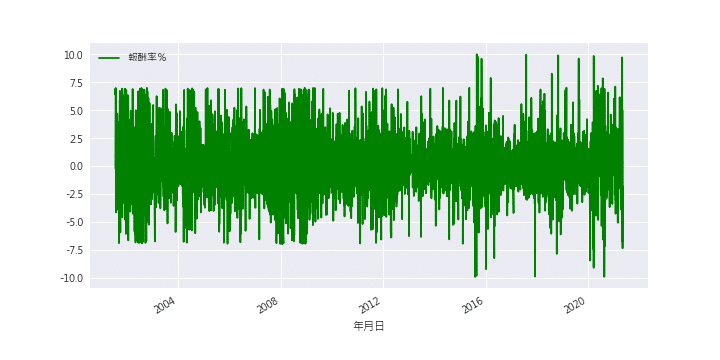
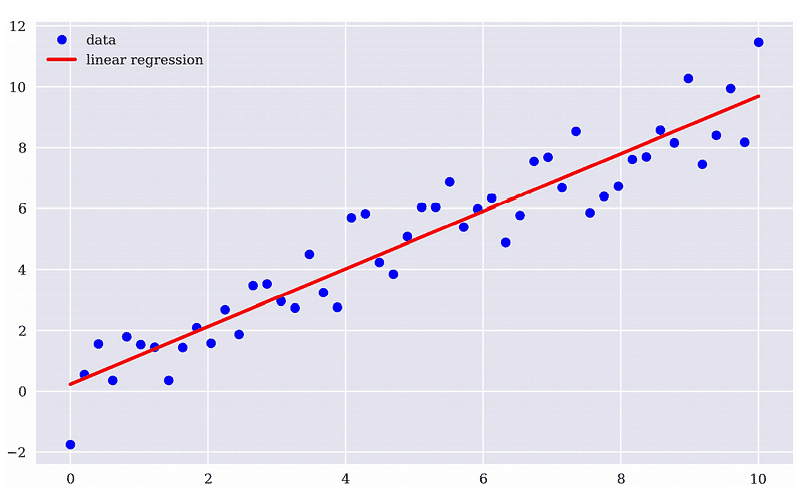
根據下圖,不難看出用回歸模型來預測報酬率實在有點難度,預測市場果然不那麼容易
# 用昨天(第t-1日)的報酬率去預測今天(第t日)的報酬率
# 因前兩個位置的值為NA,故取第3個位置以後的數值
x = data['報酬率%'].shift(1)[2:].values
y = data['報酬率%'][2:].values
reg = np.polyfit(x,y,deg=1)
# 繪圖
plt.figure(figsize=(10,6))
plt.plot(x, y, 'bo', label='data')
plt.plot(x, np.polyval(reg,x),'r',label='linear regression')
plt.legend(loc=0)
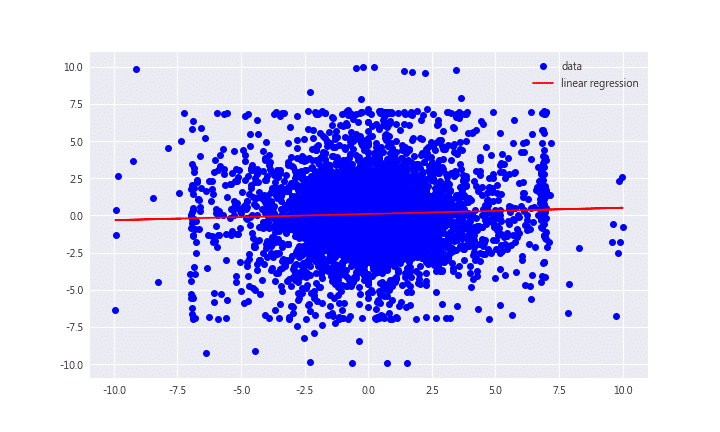
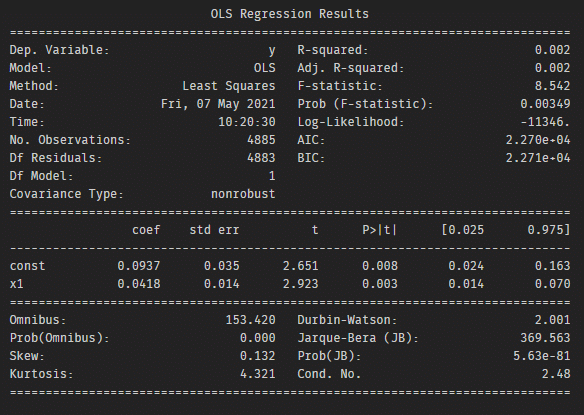
從統計報表的T統計量的絕對值大於2可知道,昨日的報酬率對於今日的報酬率有顯著影響,故昨日報酬是值得納入的變數。
修改最初的模型,認為昨日的報酬率所富有的資訊含量不夠,以至於預測能力不佳,因此考慮增加更多變數,除了落後一期的報酬率外,多考慮了落後2期、3期的報酬率,回歸式如下:
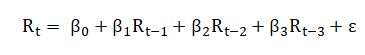
# 落後一期至三期的報酬率
data['R_t-1'] = data['報酬率%'].shift(1)
data['R_t-2'] = data['報酬率%'].shift(2)
data['R_t-3'] = data['報酬率%'].shift(3)
x = data[['R_t-1','R_t-2','R_t-3']][4:].values
y = data['報酬率%'][4:].values
reg_t3 = np.linalg.lstsq(x,y, rcond=None)[0]
# 繪圖
plt.figure(figsize=(10,6))
plt.plot(y[1000:1300],label = 'true_value')
plt.plot(np.dot(x, reg_t3)[1000:1300],color = 'green',label = 'predict')
plt.legend()
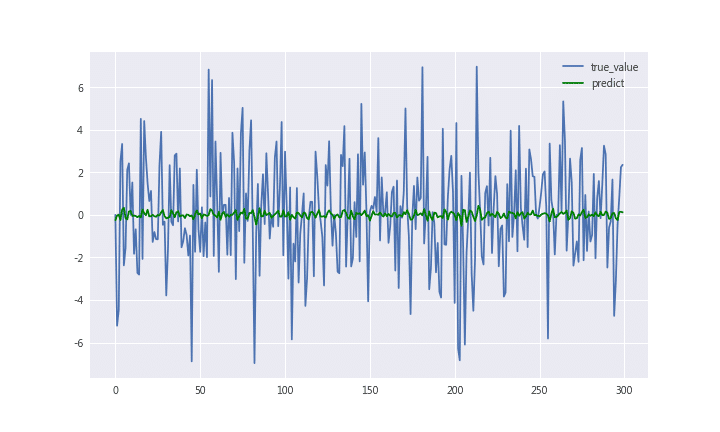
根據報表可看出,落後一期與三期的報酬率,其實對今日的報酬率有顯著影響,因此建模的過程中可以考慮不必再加入過多的期數作為自變數!!
線性回歸的部分就暫且先告一段落了,預測市場一直是財務和統計上相當熱門的議題,有興趣的朋友可以去參考相關文獻,或者自行去探索其他有效的因子~
羅吉斯回歸雖然名字中有回歸兩個字,但實際上它是屬於分類法的一種。
分類法不同於回歸的地方在於,分類法的輸出是類別,屬於間斷變數(0, 1);回歸的輸出則是數值,屬於連續變數(0, 0.1, 0.5, 1.2)。
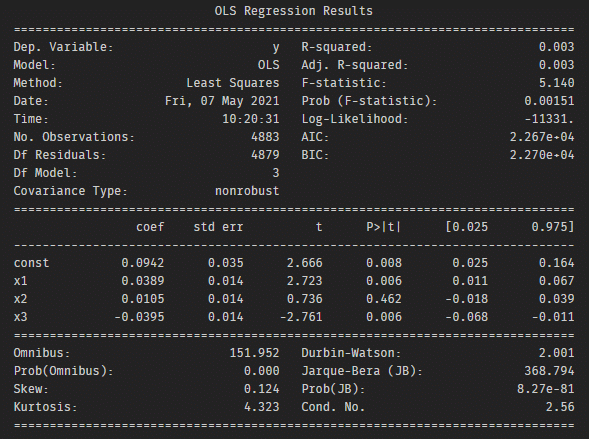
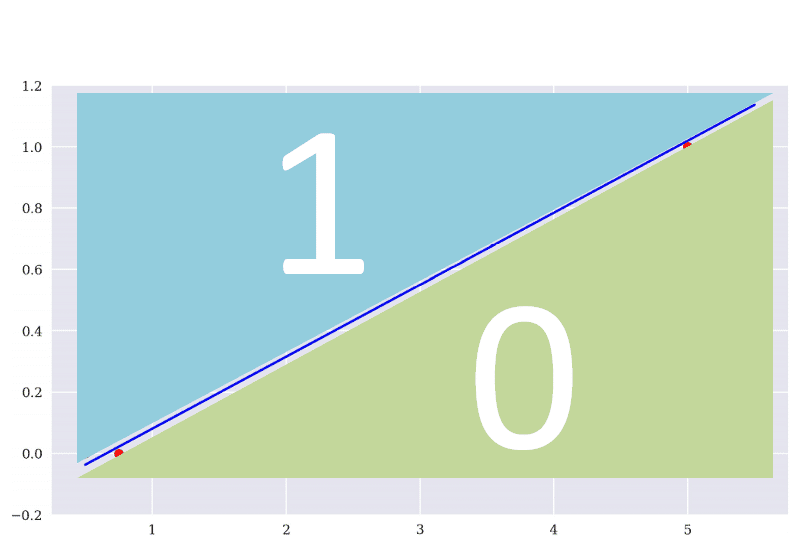
上述的線性回歸目的在找一條離所有資料點的平均距離最近的直線,那羅吉斯回歸就是在找一條可區分出最多資料的斜直線。理想情況如下,由下圖所示,該模型在類別1的部分只分錯兩筆資料,而在類別0僅分錯1筆。
由於前面的線性回歸模型預測效果不佳,再加上要準確預測明日的報酬率確實太過困難,因此我們嘗試來簡化問題,由預測報酬率轉向預測明天漲跌,畢竟我們其實不用知道正確的報酬率數值,只要能知道明日市場的走向就能建構策略。
📈羅吉斯回歸分析📈
np.where(條件, 符合條件輸出, 不符合輸出):
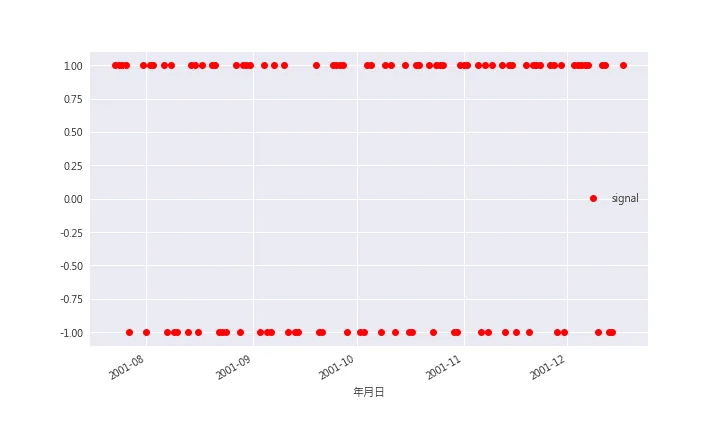
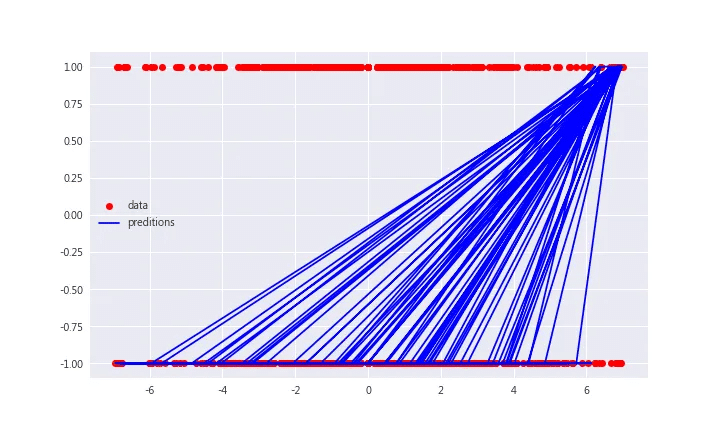
報酬率>0的,輸出 1,反之,則輸出 -1。data['signal'] = np.where(data['報酬率%']>0,1,-1) # 繪圖 data[:100].plot(x = '日期', y = 'signal', style = 'ro', figsize = (10,6) )資料散佈圖–分類(1, -1) from sklearn import linear_model lm = linear_model.LogisticRegression(solver = 'lbfgs') R_t1 = x.reshape(1,-1).T signal = y lm.fit(R_t1,signal) preditions = lm.predict(R_t1) plt.figure(figsize = (10, 6)) plt.plot(x, y, 'ro', label = 'data') plt.plot(x, preditions, 'b', label = 'preditions') plt.legend(loc = 0)預測結果 預測準確率
預測準確率為 0.5471,約略大於5成。
from sklearn.metrics import accuracy_score preditions = lm.predict(R_t1) accuracy_score(preditions, y)結論
自己實作了報酬率的預測,是不是發現要預測市場真的相當的不容易啊 😎😎~但是看到模型準確率不高也不用灰心,因為不是只有預測才能夠在市場賺錢 💰,未來我們會分享不用預測也能賺到錢的原因,請持續關注我們的Medium。
最後,如果喜歡本篇文章的內容請幫我們點擊下方圖示👏 ,給予我們更多支持與鼓勵,有任何的問題都歡迎在下方留言/來信,我們會盡快回覆大家👍👍
一個優秀的策略必須建構在"穩定""品質高""資料長度長"的資料源之上,而 TEJ API就是你最好的選擇!!
完整程式碼
延伸閱讀
相關網站連結
- API官方網站:TEJ API 官網
- 本文範例產品包:TEJ E SHOP
有任何使用上的問題都歡迎與我們聯繫:聯絡資訊