使用PCA主成份分析優化投資組合
Table of Contents
文章難度:★★★★☆
數學的本質不是將簡單的事情變複雜,而是將複雜的事物簡化。- Stan Gudder
主成分分析(Principal Component Analysis,後簡稱為 PCA),為非監督式學習中的一項關鍵技術,被廣泛用於機器學習與統計學領域來分析資料、降低數據維度。核心精神在於將原始數據拆解成具有代表性的主成分,達到降維的目的,並重新描述數據。
本研究的主旨在於運用股票的日報酬資料,利用 PCA 來取得主成分,並建立投資組合。閱讀本篇文章讀者將會看到以下重點:
了解 PCA 之特徵值與特徵向量,並以此設計投資組合
回測投資組合績效的方法,可用於各式投資策略
本文使用Windows OS並以jupyter作為編輯器
import tejapi
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
tejapi.ApiConfig.api_key = "Your Key"
0050指數成分股資料集 — 上市上櫃指數(TWN/EWISAMPLE)
0050股價報酬(日)-報酬率(TWN/APRCD2)
0050調整股價(日) — 除權息調整(TWN/APRCD1)
指數資料期間:2013.01.01–2022.11.24
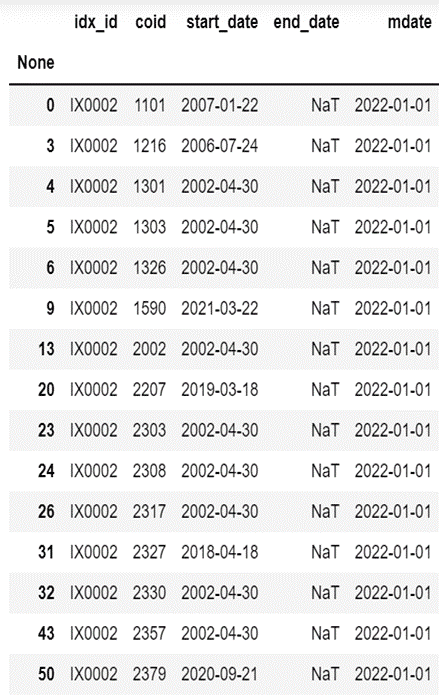
0050成分股載入,載入規則依照[“end_date”]欄位做篩選,選出目前尚在成分股中的股票。
mdate = {'gte':'2000-01-01', 'lte':'2022-11-24'}
data = tejapi.get('TWN/EWISAMPLE',
idx_id = "IX0002",
start_date = mdate,
paginate=True)
data1 = data[data["end_date"] < "2022-11-24"]
diff_data = pd.concat([data,data1,data1]).drop_duplicates(keep=False)
coid = list(diff_data["coid"])
print(len(coid))
diff_data
0050報酬率載入
for i in range(0,len(coid)):
print(i)
if i == 0:
df = tejapi.get('TWN/EWPRCD2',
coid = coid[i],
mdate = {'gte':'2013-01-01', 'lte':'2022-11-24'},
paginate=True)
df.set_index(df["mdate"],inplace=True)
Df = pd.DataFrame({coid[i]:df["roia"]})
else:
df = tejapi.get('TWN/EWPRCD2',
coid = coid[i],
mdate = {'gte':'2013-01-01', 'lte':'2022-11-24'},
paginate=True)
df.set_index(df["mdate"],inplace=True)
Df1 = pd.DataFrame({coid[i]:df["roia"]})
Df = pd.merge(Df,Df1[coid[i]],how='left', left_index=True, right_index=True)
日月光投控( 3711 )於 2018/04/30 後上市才有報酬率資料,予以剔除。
上海商業儲蓄銀行( 5876 )於 2014/09/25 後上市才有報酬率資料,予以剔除。
矽力-KY (6415)於 2013–12–12 後上市才有報酬率資料,予以剔除。
del Df["3711"]
del Df["5876"]
del Df["6415"]
故本文改以截至 2022/11/24 前,0050成分股並剔除以上3檔股票,共 47 檔為研究對象。
故本文改以截至 2022/11/24 前,0050成分股並剔除以上3檔股票,共 47 檔為研究對象。
資料視覺化
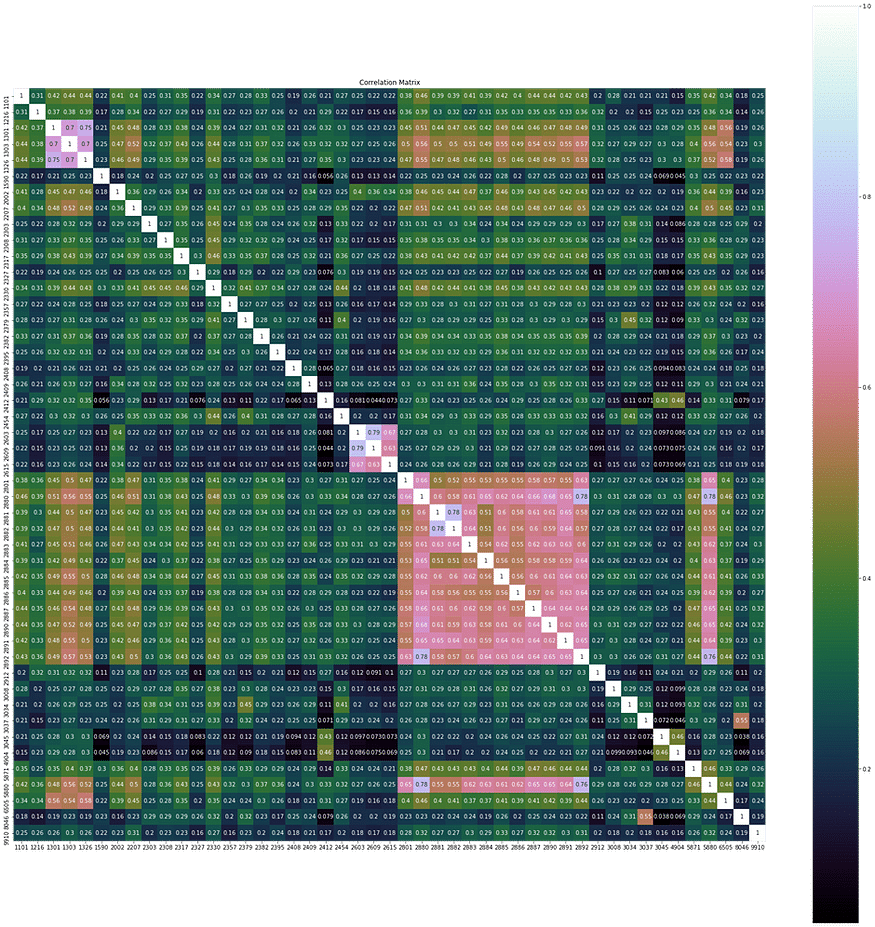
首先我們須對資料集有基本的認識,我們觀察各成本股報酬率的相關性,可以看出日報酬間存在顯著正相關性,因此資料可以更低的維度來表達,即小於目前的 47 維度。
cor = Df.corr()
plt.figure(figsize=(30,30))
plt.title("Correlation Matrix")
sns.heatmap(cor, vmax=1,square=True,annot=True,cmap="cubehelix")
資料標準化
建模型之前,我們並不知道資料集中每個特徵的重要性,這很可能造成大量信息流失,因此對每個特徵進行標準化處理,使得資料範圍相同,再進行PCA。
scale = StandardScaler().fit(Df)
rescale = pd.DataFrame(scale.fit_transform(Df),columns=Df.columns,index=Df.index)
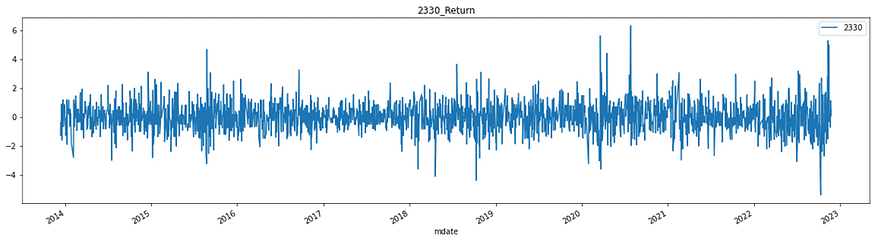
#標準化視覺化
plt.figure(figsize=(20,5))
plt.title("2330_Return")
rescale["2330"].plot()
plt.grid=True
plt.legend()
plt.show()
模型設置
我們希望將原有的 47 維度資料降低至 10 維度,讓原始資料以10個主成分來表示即可。
n_components = 10
pca = PCA(n_components=n_components)
Pc = pca.fit(X_train)
PCA 解釋變數
第一主成分表示了原始資料中最大的變異數,第二個主成分表示了原始資料中的第二大變異數,並以次類推。
fig, axes = plt.subplots(ncols=2)
Series1 = pd.Series(Pc.explained_variance_ratio_[:n_components ]).sort_values()
Series2 = pd.Series(Pc.explained_variance_ratio_[:n_components ]).cumsum()
Series1.plot.barh(title="Explained Variance",ax=axes[0])
Series2.plot(ylim=(0,1),ax=axes[1],title="Cumulative Explained Variance")
print("變數累積解釋比例:")
print(Series2[len(Series2)-1:len(Series2)].values[0])
print("各變數解釋比例:")
print(Series1.sort_values(ascending=False))
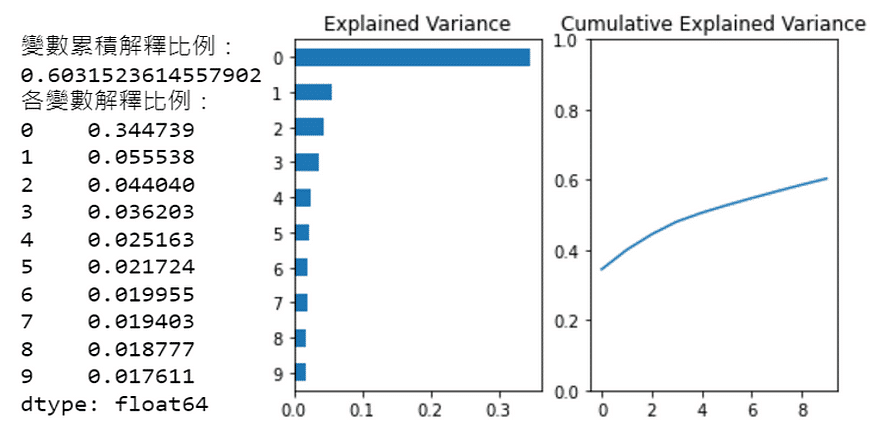
由左圖可看出前 10 個主成分解釋變異數情形,第一個主成分就佔了原資料35% 的變異數,代表第一主成分解釋了 35% 的 47 檔股票日報酬變化,而這個決定性很大的主成分通常稱作「市場」因素。
由右圖可看出前 10個主成分,共解釋了這 47 檔股票日報酬約 60% 的變異數。
設置投資組合權重
在上個步驟中,我們看出主成分解釋變數情形,接下來探討原先資料,也就是 47 檔股票,對這 10 個主成分的相關性。並以此設計投資組合權重。
n_components = 10
weights = pd.DataFrame()
for i in range(n_components):
weights["weights_{}".format(i)] = pca.components_[i] / sum(pca.components_[i])
weights = weights.values.T
weight_port = pd.DataFrame(weights,columns=Df.columns)
weight_port.index = [f'Portfolio{i}' for i in range(weight_port.shape[0])]
weight_port
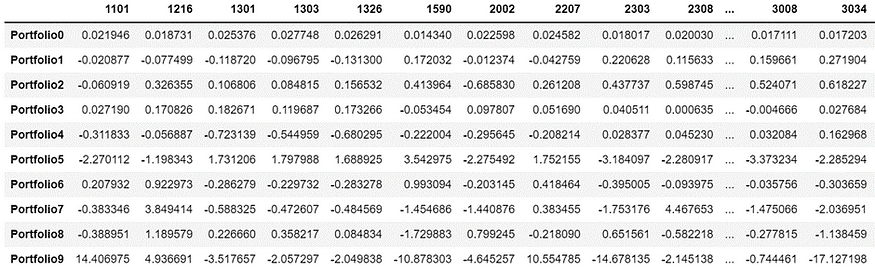
解釋投資組合權重設置方法
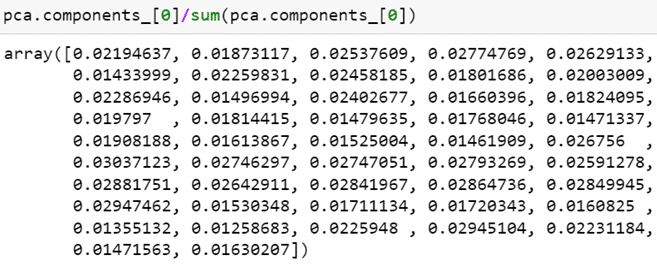
第一主成分解釋了 35% 的變異,我們來看各變數(47檔股票),對第一主成分的相關性。
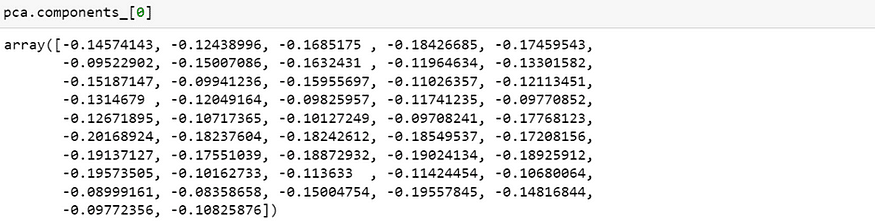
由 array 中可看出,47 檔股票對於第一主成分的相關性都是同向的(均為負數),而數值大小差異並不大,這更可以驗證我們上述說明第一主成分為「市場」因素。
weight_port.iloc[0].T.sort_values(ascending=False).plot.bar(subplots=True,figsize=(20,5),
legend=False,sharey=True,ylim=(-0.75,0.75))
再來,我們以各股票的相關性 / 各股票相關性數值總和 ,完成投資組合權重。
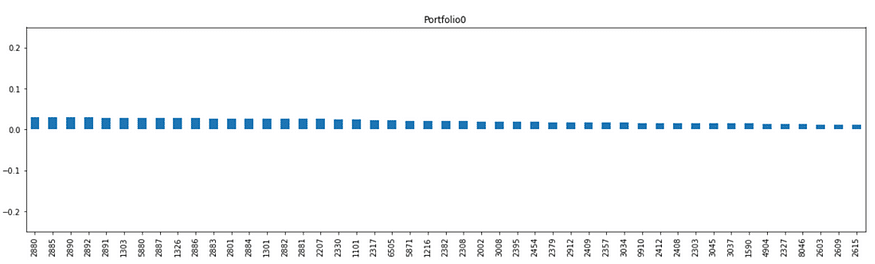
畫出前五大主成分投資組合之權重
weight_port[:5].T.plot.bar(subplots=True,layout = (int(5),1),figsize=(20,25),
legend=False,sharey=True,ylim=(-2,2))
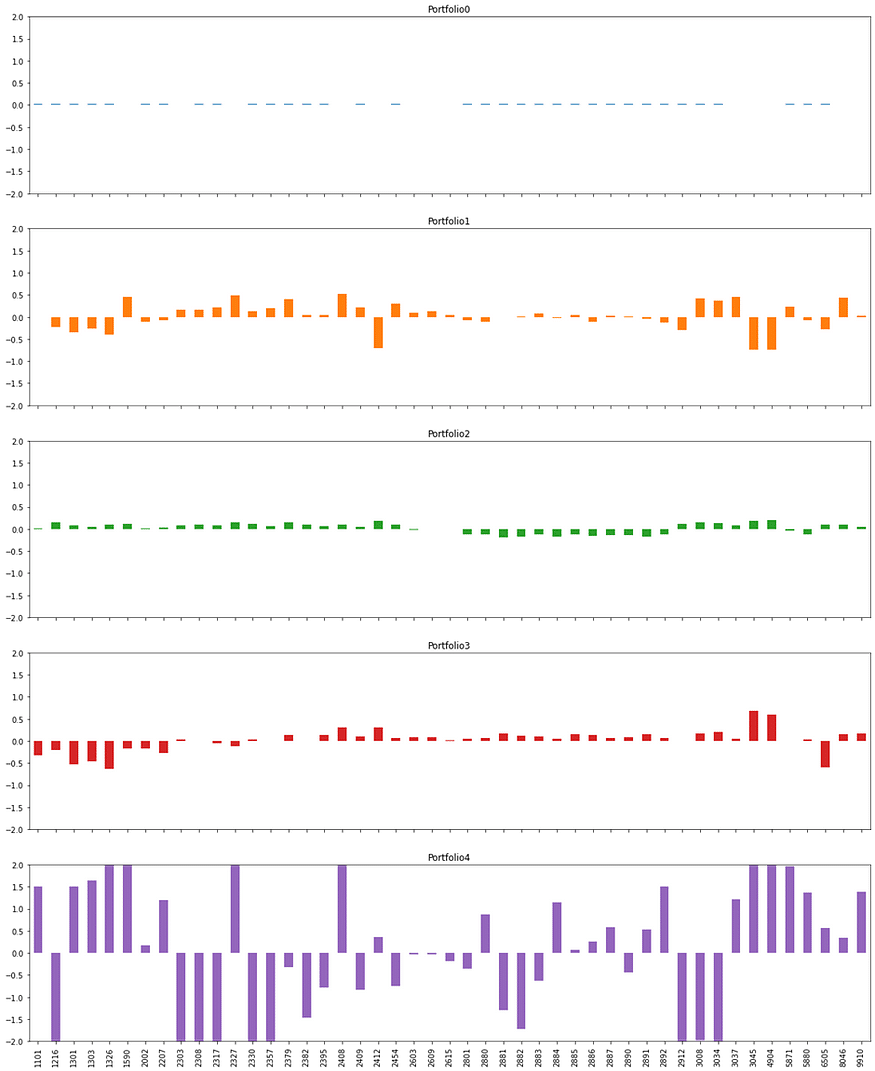
檢視其他主成分分類邏輯
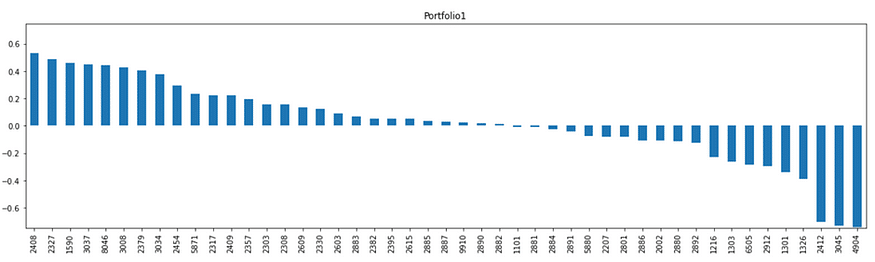
Portfolio 1
前三名分別為南亞科(2408)、國巨(2327)、亞德克KY(1590);後三名分別為遠傳(4904)、台灣大(3045)、中華電(2412),可看出Portfolio 1電子股權重較高,傳產、電信股較低。
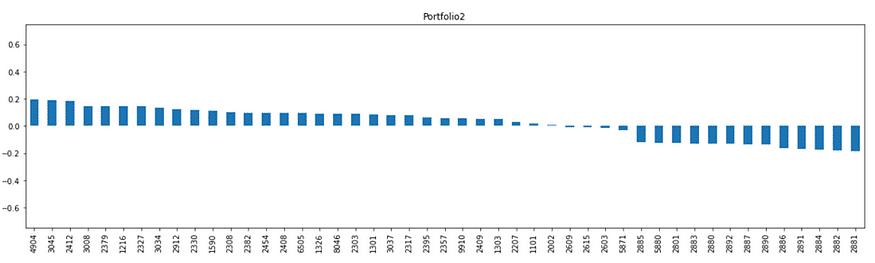
Portfolio 2
前三名反而為電信三雄,而後面大多為金融股,可看出Portfolio 2為非金融投資組合。
我們以夏普比率( Sharpe Ratio )來做為衡量指標,夏普率(或夏普值)是在基金投資或是資產配置時,用來衡量整個投資組合績效與穩定性的重要指標。表示「在承受1%的風險下,能得到多少報酬?」
本文夏普比率公式 = 以年化報酬率 / 年化風險做計算
def sharpe_ratio(ts_returns):
ts_returns = ts_returns
days = ts_returns.shape[0]
n_years = days/252
if ts_returns.cumsum()[-1] < 0:
annualized_return = (np.power(1+abs(ts_returns.cumsum()[-1])*0.01,1/n_years)-1)*(-1)
else:
annualized_return = np.power(1+abs(ts_returns.cumsum()[-1])*0.01,1/n_years)-1
annualized_vol = (ts_returns*0.01).std()*np.sqrt(252)
annualized_sharpe = annualized_return / annualized_vol
return annualized_return,annualized_vol,annualized_sharpe
選出Top5 Portfolio
n_components = 10
annualized_ret = np.array([0.]*n_components)
sharpe_metric = np.array([0.]*n_components)
annualized_vol = np.array([0.]*n_components)
coids = X_train.columns.values
n_coids = len(coids)
pca = PCA(n_components=n_components)
Pc = pca.fit(X_train)
pcs = pca.components_
for i in range(n_components):
pc_w = pcs[i] / sum(pcs[i])
eigen_port = pd.DataFrame(data={"weights":pc_w.squeeze()},index=coids)
eigen_port.sort_values(by=["weights"],ascending=False,inplace=True)
#權重與每天報酬內積,得出每日投資組合報酬
eigen_port_returns = np.dot(X_train.loc[:,eigen_port.index],eigen_port["weights"])
eigen_port_returns = pd.Series(eigen_port_returns.squeeze(),
index = X_train.index)
ar,vol,sharpe = sharpe_ratio(eigen_port_returns)
annualized_ret[i] = ar
annualized_vol[i] = vol
sharpe_metric[i] = sharpe
sharpe_metric = np.nan_to_num(sharpe_metric)
N=5
result = pd.DataFrame({"Annual Return":annualized_ret,"Vol":annualized_vol,"Sharpe":sharpe_metric})
result.dropna(inplace=True)
#Sharpe Ratio of PCA portfolio
ax = result[:N]["Sharpe"].plot(linewidth=3,xticks=range(0,N,1))
ax.set_ylabel("Sharpe")
result.sort_values(by=["Sharpe"],ascending=False,inplace=True)
print(result[:N])

畫出投資組合期間報酬走勢圖
def Backtest(i,data):
pca = PCA()
Pc = pca.fit(data)
pcs = pca.components_
pc_w = pcs[i] / sum(pcs[i])
eigen_port = pd.DataFrame(data={"weights":pc_w.squeeze()},index=coids)
eigen_port.sort_values(by=["weights"],ascending=False,inplace=True)
#權重與每天報酬取內積得出每日投資組合報酬
eigen_port_returns = np.dot(data.loc[:,eigen_port.index],eigen_port["weights"])
eigen_port_returns = pd.Series(eigen_port_returns.squeeze(),
index = data.index)
ar,vol,sharpe = sharpe_ratio(eigen_port_returns)
return eigen_port_returns,ar,vol,sharpe
報酬走勢視覺化
def Weight_plot(i):
top_port = weight_port.iloc[[i]].T
port_name = top_port.columns.values.tolist()
top_port.sort_values(by=port_name,ascending=False,inplace=True)
ax = top_port.plot(title = port_name[0],xticks=range(0,len(coids),1),
figsize=(15,6),
rot=45,linewidth=3)
ax.set_ylabel("Portfolio Weight")
portfolio = 0
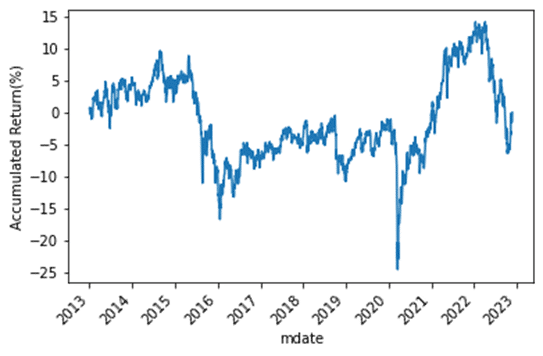
train_returns,train_ar,train_vol,train_sharpe = Backtest(portfolio,X_train)
ax = train_returns.cumsum().plot(rot=45)
ax.set_ylabel("Accumulated Return(%)")
Weight_plot(portfolio)
小結
以上提供投資組合簡單的回測方法並視覺化,可見由 PCA 方法建構的投資組合績效並不好,其實這也是可預見的,PCA 只是針對報酬相關性做投組分類,並不代表能有好的報酬。
本篇提供 PCA 針對台灣 50指數(因資料缺失剔除三檔),共 47 檔股票,針對日報酬做研究,將原 47 檔股票降維成 10個主成分,根據主成分與各股票之相關性,建構投組權重並針對各別主成分做討論,除了可看出股票市場中影響最大的「市場」因素確實存在,也可看出 PCA 在分類方面仍有一定邏輯。惟要詳細解釋每個主成分所代表的意義然有其困難所在。
最後,還是要再次提醒本文所提及之標的僅供說明使用,不代表任何金融商品之推薦或建議。因此,若讀者對於建置策略、績效回測、研究實證等相關議題有興趣,歡迎選購 TEJ E Shop中的方案,具有齊全的資料庫,就能輕易的完成各種檢定。
