
Table of Contents
隨著工業化的蓬勃發展,人們發現全球各地漸漸發生的氣候變化會對自然環境、社會及全球經濟會產生嚴重的影響,例如極端氣候、海平面上升與空氣污染等現象,各國開始思考要怎麼與自然環境共存,因此聯合國在2005年提出企業應該將「環境」、「社會責任」與「公司治理」,也就是大家常說的 “ESG” 納入企業經營的評量基準,希望可對社會及金融市場、個人的投資組合產生正面影響,也使企業也必須思考要如何在不斷變化商業環境中維持顧營收成長的情況下同時達成永續經營的目標。
但是在市場中,每天都有數也數不清的消息資訊出現在市場上,透過個人想了解全部的資訊細節著實困難,因此今天的主題就是透過「TESG事件雷達」搭配主題分析幫助我們快速了解 各大政府公開資訊平台、股東會年報、企業永續報告書所討論的 ESG 議題為何。
普遍來說,一個文本會是由多個主題組成,而且每個主題所佔的文章比例各不相同,因此文本中相應主題的關鍵字出現次數也會有所不同,主題模型來可以用於分析文本內的字詞,以統計的方式來計算文本可能屬於每個主題的機率分佈。
Latent Dirichlet Allocation ( 隱含狄利克雷分配 ) 是一種非監督式主題模型,是一般化的PLSI ( 機率潛在語義分析 )。它用於按主題收集、分類和降低文本的維度。 LDA 是一種主題模型方法,可用於分析文本的主題分佈,以機率分佈的形式表達每個文本的主題。
本文使用Mac OS並以jupyter作為編輯器
import tejapi
# 前處理套件
import pandas as pd
import re
import numpy as np
from datetime import datetime
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
# 模型套件
from numba import jit, cuda
import gensim
from gensim import corpora, models
from gensim.models.coherencemodel import CoherenceModel
from gensim.models.ldamodel import LdaModel
# 視覺化套件
import matplotlib
import matplotlib.pyplot as plt
import pyLDAvis.gensim_models
from wordcloud import WordCloud
# 輔助套件
import warnings
warnings.filterwarnings("ignore")
tejapi.ApiConfig.api_key = "Your Key"
tejapi.ApiConfig.ignoretz = True
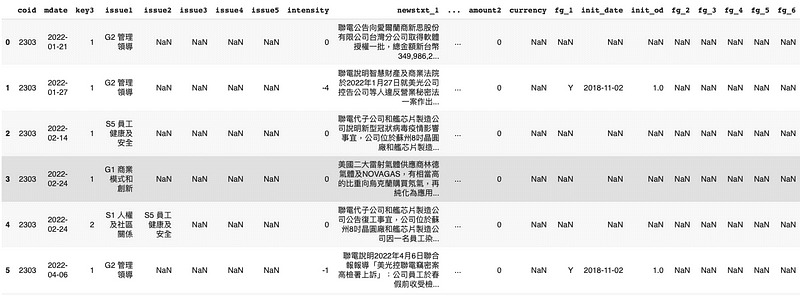
資料期間從 2022–01–01 至 2023–04–01,以台積電 (2330) 作為實例,抓取事件內容作為分析資料。
stock_id = '2330', '2303', '2881', '3045'
gte, lte = '2022-01-01', '2023-04-01'
TESG = tejapi.get('TWN/AEWATCHA',
paginate = True,
coid = stock_id,
mdate = {'gte':gte, 'lte':lte},
)
df = TESG
df["mdate"] = pd.to_datetime(df["mdate"])
本次實作我們使用中研院研發的NLP套件 「ckip_transformers」來作為文章斷詞與詞性標注的工具,原因是「ckip_transformers」的斷詞結果相較於「jieba」、「SnowNLP」等基於中國中文用法開發的套件,斷詞結果更接近台灣人的習慣。
# Initialize drivers
print("Initializing drivers ... WS")
# device=0 為使用gpu進行運算,如電腦無gpu者可改為 device=-1 用cpu運算
ws_driver = CkipWordSegmenter(model="albert-base", device=0)
print("Initializing drivers ... POS")
pos_driver = CkipPosTagger(model="bert-base", device=0)
print("Initializing drivers ... NER")
接著就對文章進行斷詞與詞性標註,這裡使用 python 中的 lambda 函式來對每一筆資料進行處理,其優點是效能高且程式碼簡單,相較於 for 迴圈能更快完成大量資料處理。
df["seg"] = list(map(lambda x: ws_driver([x]), list(df["newstxt_1"])))
df["seg"] = df["seg"].apply(lambda x : x[0])
df["pos"] = df["seg"].apply(lambda x : pos_driver(x))

由上圖我們可以發現經過詞性標注後,單一單詞有可能擁有多種詞性,而對於大多數的語言,句子的意義主要集中在名詞及動詞上,因此下一步我們需要過濾出斷詞中為名詞或動詞的單詞,並將結果放入一個新的欄位「N_or_V」。
# 詞性過濾
def fltr_nv(word_lst, pos_lst):
lst = []
for word, pos in zip(word_lst, pos_lst):
for i in pos:
if i.startswith(("N", "V")):
lst.append(word)
break
return lst
df["N_or_V"] = df.apply(lambda x : fltr_nv(x["seg"], x["pos"]), axis = 1)
再來我們篩查看其中資料分布的月份。
# 計算每月文章數
gb_corp = df_corp[["mdate", "N_or_V"]].groupby([df.mdate.dt.year, df.mdate.dt.month])
a = 0
lst = []
for group_key, group_value in gb_corp:
group = gb_corp.get_group(group_key)
dct = {
"month" : datetime.strptime(str(group['mdate'].iloc[0])[:7], "%Y-%m"),
"key_word" : [i for i in group['N_or_V']]
}
lst.append(dct)
print(f"{group_key} : {len(group)}")
a+=len(group)
print(a)

我們透過文字雲來觀察每篇文章的重點單字,可以看到雖然我們未使用 TF-IDF 、Rext Rank等等關鍵字擷取的方法,僅僅經過詞性篩選所得到的結果看似已經非常不錯了。
!wget https://raw.githubusercontent.com/victorgau/wordcloud/master/SourceHanSansTW-Regular.otf -o /dev/null
%matplotlib inline
# 從 Google 下載的中文字型
font = 'SourceHanSansTW-Regular.otf'
df_keyword = pd.DataFrame(lst)
df_keyword["key_word"] = df_keyword["key_word"].apply(lambda x : " ".join(x[0]))
df_keyword["pic"] = df_keyword["key_word"].apply(lambda x : WordCloud(font_path=font, max_words = 20, background_color = "white").generate(x))
plt.imshow(df_keyword["pic"].iloc[10])
plt.axis("off")
plt.show()

我們使用 gensim 這個套件來進行 LDA 模型的建置,首先第一步必須建立字典並且為字典中的每個單字給予相對應的編號,再計算每個編號 ( 單詞 ) 在全部文章中出現的次數。
# 將過濾後的單詞轉換為轉換為list of list形式
seg_lst = list(df_corp["N_or_V"])
# corpora.Dictionary() input 是文字的 list of list
dictionary = corpora.Dictionary(seg_lst)
# corpus為 (編號:出現字數) 的 list of list
corpus = [dictionary.doc2bow(i) for i in seg_lst]
接下來就要來建立模型了,這邊遇到一個問題,由於 LDA 主題分類需要事先給定要分類的主題數才能運作,但究竟分類成幾類才是最恰當的呢?
這裡我們使用 Log Perplexity 與 Topic Coherence 來衡量分類數量。
Log Perplexity 解釋了模型預測結果中的 “不確定性” 水準,也就是對於一篇文章來說,我們有多不確定 它是屬於某個主題的,所以主題的個數越多,模型的困惑度就越低,但要注意的是,當主題數很多的時候,生成的模型往往會過擬合,所以不能單純依靠困惑度來判斷一個模型的好壞。
相比之下,Topic Coherence 會衡量主題中高分詞之間的語義相似度,這些測量有助於區分 語義可解釋的主題 和 基於統計推斷的主題,分數越高代表主題之間的一致性越低。通常,一致性分數會隨著主題數量的增加而增加。 隨著主題數量的增加,一致性分數增加幅度會遞減。 這時經常使用 elbow technique ( 手肘法 ) 在主題數量和連貫性得分之間進行權衡。
而關於具體這兩個方法為何能幫助我們判斷主題個數的原因在這裡就不細說了,目前需要的概念只有Log Perplexity越低代表分類效果越好、Topic Coherence越高代表分類效果越好
這裡要提醒一點,沒有一種準則說 Perplexity、Coherence 應該落在哪裡才是好的,我們得到分數及其價值取決於其計算的資料。 例如,在一種情況下,0.5的分數可能足夠好,但在另一種情況下是不可接受的。
唯一的規則是,我們希望把 Perplexity 分數最小化、Coherence分數最大化。
# 困惑度計算
def perplexity(num_topics):
ldamodel = LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes = 30)
print(ldamodel.print_topics(num_topics = num_topics, num_words = 15))
print(ldamodel.log_perplexity(corpus))
return ldamodel.log_perplexity(corpus)
# 主題一致性計算
def coherence(num_topics):
ldamodel = LdaModel(corpus, num_topics = num_topics, id2word = dictionary, passes = 30, random_state = 42)
print(ldamodel.print_topics(num_topics = num_topics, num_words = 15))
ldacm = CoherenceModel(model = ldamodel, texts = seg_lst, dictionary = dictionary, coherence="c_v")
print(ldacm.get_coherence())
return ldacm.get_coherence()
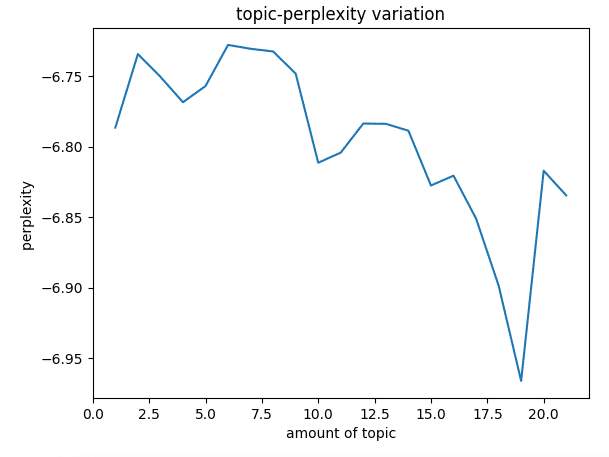
由上圖我們可以發現 Log Perplexity 在主題數為 9 之後會急速下降,這隱含的意義為模型可能產生過擬合的情形,所以我們選擇的主題數應該要小於 10 ,因此 Topic Coherence 我們將給定的主題數為 1 ~ 9 進行計算。
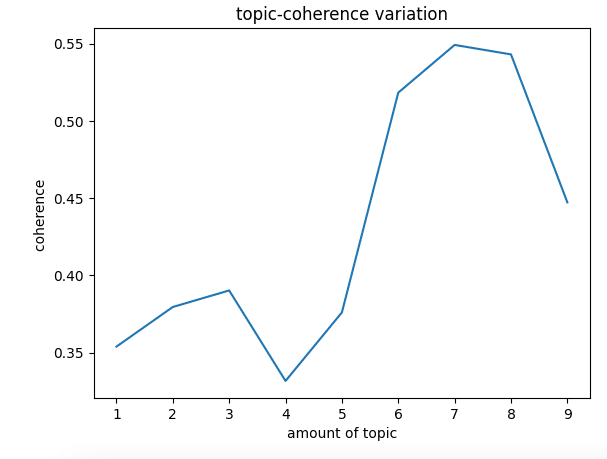
結果顯示當主題數為 7 時,分類模型著最高的分數,如此一來我們就確定了應該要將文章分類成 7 類,接著就將主題數輸入模型。
num_topics = 7
lda = LdaModel(corpus, num_topics = num_topics, id2word = dictionary, passes = 30, random_state = 42)
# 印出每個主題中的前15個關鍵字詞
topics_lst = lda.print_topics()
print(topics_lst)
這樣模型就完成了,我們透過「pyLDAvis」這個視覺化套件來呈現模型分類結果,詳細視覺化程式碼在文章最後會提供。
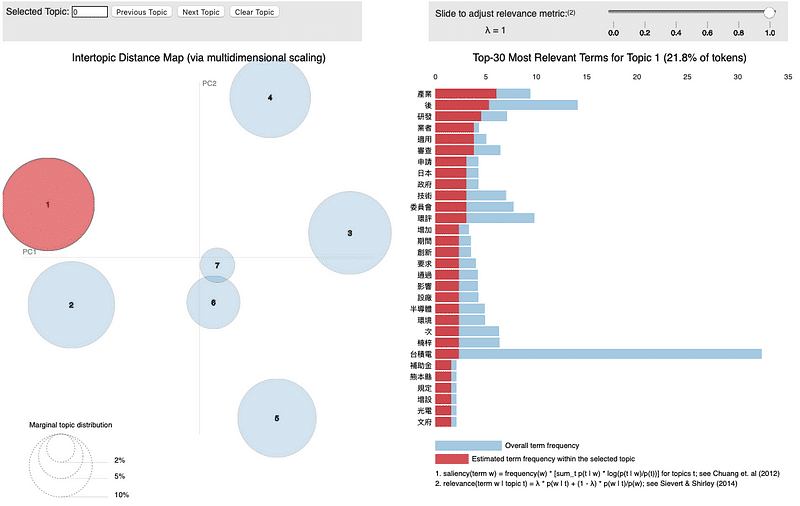
pyLDAvis的視覺化圖表包含兩張圖表,左側為主題的分類結果,每一個圓圈代表一個主題,面積越大代表包含的文章數越多,座標軸為 PCA 主成分分析的結果,橫軸為第一主成分,縱軸為第二主成分,圓圈之間的距離則為個主題的相似程度。
右側關鍵字的統計量,藍色長條圖為全部文章的關鍵字出現次數,紅色為該主題關鍵字出現次數,透過調整上方的 λ 值能顯示出該主題中的獨特關鍵字,λ 越低越獨特。
我們可以看到文章大致分類效果算不錯,除了第六主題與第七主題有重疊外,其他主題之間分類明確。
然而,LDA 只是以數學的方式對文章進行分群,在數學上或許可以直觀的解釋分群結果的原因與意義,但卻往往與人類的判斷不吻合,有時甚至呈現反相關,這些結果以人的角度觀察時不一定能用清晰的概念或邏輯解釋出來,
並且資料是否有經過妥善的前處理也會很大程度的影響最終分類的結果,套一句IT界的老話「垃圾進,垃圾出」,確實的做好資料前處理才有可能得到理想的結果。然而,前處理往往程序多而繁雜,並且依照任務需求的不同常常會要求須具備一定程度的專業知識、相關經驗,不是單單憑藉一己之力可以輕易達成的。
TESG 事件雷達透過龐大的資料來源、專業研究員分析以及自然語言處理模型能幫助使用者不再需要具備上述複雜且高門檻的技術與知識就能快速掌握各公司 ESG 的最新消息。
TESG 事件雷達擁有四大優勢:
