
Table of Contents
對於股票交易市場中,我們常聽到所謂的熱門族群,而熱門族群代表著量增價漲,亦或是某些股票當我們看到新聞時已經上漲一段時間,而我們要如何及早發現這些股票,是本文想要實現的,一樣以成交量增長做為篩選條件,一次幫我們把所有市場的股票都給篩選,也能大幅減少我們尋找標的的時間。
而本文一樣是使用較為彈性的設計,可供讀者自行修改,後面會談及如何修改所參數,本文篩選條件設計如下:
1. 今日成交量是前”4”日平均的5倍
2.需要上漲3%以上
3. 交易量至少大於 500
本文使用 Window10 並以 Spyder(anaconda31) 作為編輯器
###匯入套件##########數據分析三寶import pandas as pdimport matplotlib.pyplot as pltimport numpy as np#################TEJimport tejapitejapi.ApiConfig.api_key = 'Your Key'tejapi.ApiConfig.ignoretz = True###############畫k線from mplfinance.original_flavor import candlestick_ohlcfrom matplotlib.dates import date2num ,num2dateimport matplotlib.ticker as tickerimport matplotlib.dates
證券交易資料表:上市(櫃)未調整股價(日),資料代碼為(TWN/EWPRCD)。
證券屬性資料表 : 上市(櫃)產業別與名稱,資料代碼為(TWN/ANPRCSTD)。
data=tejapi.get('TWN/EWNPRCSTD' ,chinese_column_name=True )select=data["上市別"].unique()
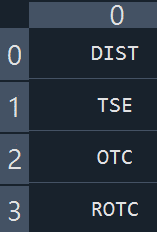
選取上市上櫃別
select=select[1:3]condition =(data["上市別"].isin(select)) & ( data["證券種類名稱"]=="普通股" )data=data[condition] ######設條件twid=data["證券碼"].to_list()
將選取的上市上櫃資料放入證券交易資料庫中,並挑選出證券代號、開盤價、收盤價、最高價、最低價、調整股價、交易量、日期。
opts={'columns': ['coid','open_d','close_d','high_d','low_d' ,'mdate', 'volume', 'close_adj']}start='2022-1-01'end="2022-03-8"tw=tejapi.get('TWN/EWPRCD',coid=twid,mdate={'gt':start,'lt':end},paginate=True,chinese_column_name=True,opts=opts)a=twa=tw.groupby(by=["證券碼"])b=list(a) #######ˇ
使用groupby函數將每一個證券碼分類,將groupby後的資料放在list裡面才能觀察
點開裡面的形式如下
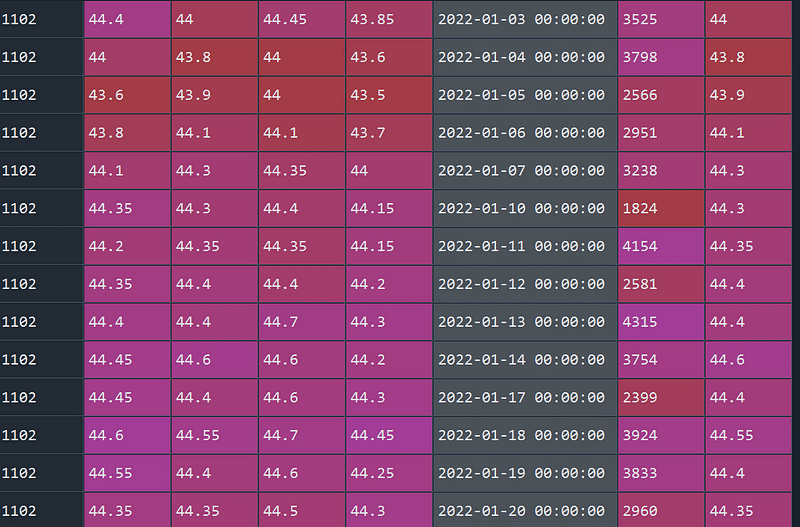
def selectstock(b,number,minnum,num) : # b為用groupby做出來的listoutput=[]for i in range(len(b)):a=b[i][1]a["五日均量"]=a["成交量(千股)"].rolling(5).sum()a["五日均價"]=a["收盤價-除權息"].rolling(5).mean()a["前幾日平均"]=(a["五日均量"]-a["成交量(千股)"]) / 4a["成交量"+str(number)+"倍喔"]=a["成交量(千股)"]-a['前幾日平均'] *numbera.drop('五日均量',axis=1)if a["成交量(千股)"].mean() > minnum :output.append(a)stockineed=[]
for j in output:j.reset_index(drop=True,inplace=True)if j["成交量"+str(number)+"倍喔"][len(j)-1] > 0 :if j["收盤價-除權息"][len(j)-1] > j["收盤價-除權息"][len(j)-2]*num :stock=j["證券碼"][0]stockineed.append(stock)return stockineed
此函式是有3個參數設計 (number,minnum,num)
number 可以選擇倍數 本文選 前”4″日平均的5倍
minnum 可以選擇篩選成交量之最小值 本文選”500″
num 當日上漲幅度 本文選取 ” 3″ %
stockineed=selectstock(b,5,500,1.03)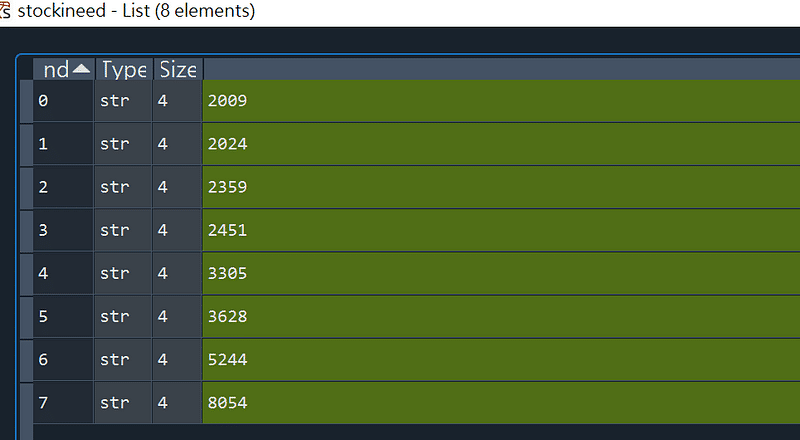
這些資料為本次篩選出來的股票代碼一共有八檔股票符合條件
condition=tw["證券碼"].isin(stockineed)tw1=tw[condition]
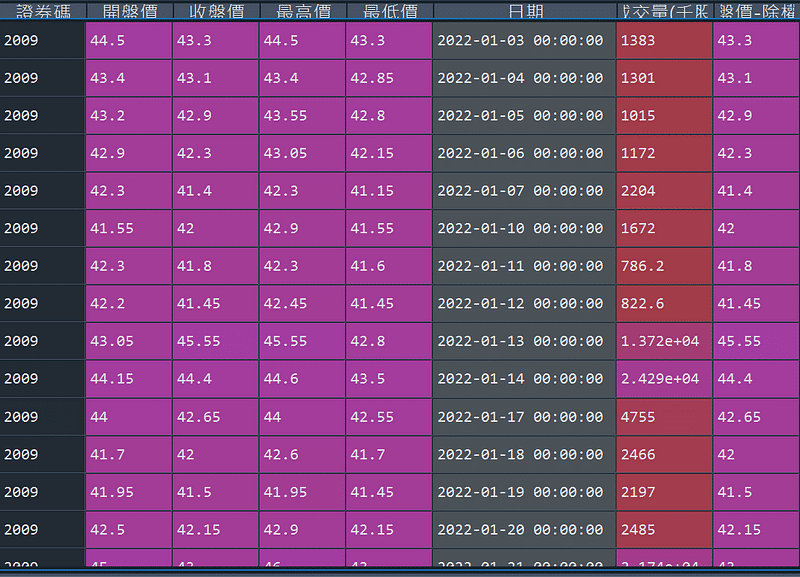
a=tw1.groupby("證券碼")a=list(a)for i in a:i[1].set_index("日期",inplace=True) ###將日期設為index
與剛才一樣的步驟將資料使用groupy函數聚合
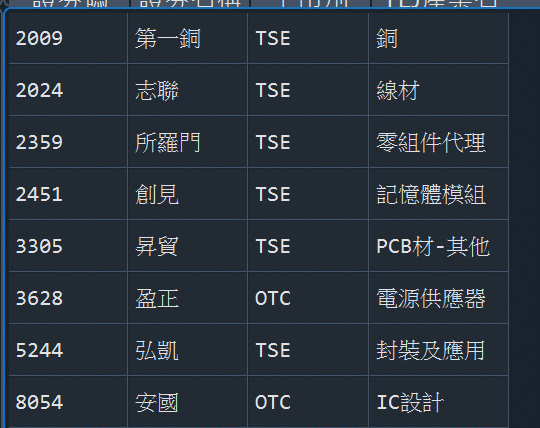
我們能得到篩選出來股票的日交易資料,我們使用剛才得到股票代碼取尋找分別代表的產業類別,方便畫圖時顯示,並且打算把它畫出來!
opts={'columns': ['coid','stk_name','mkt','tejindnm',]}data1=tejapi.get('TWN/ANPRCSTD' ,opts=opts,chinese_column_name=True,paginate=True,coid=stockineed)
def getplot(finaldata):for i in range(len(finaldata)):out=finaldata[i][1]name=data1[data1["證券碼"]==finaldata[i][0]]outputname0=name.loc[i,'證券名稱']##為了得到標題outputname1=name.loc[i,'上市別'] ##outputname2=name.loc[i,"TEJ產業名"]### out.reset_index(drop=True,inplace=True)if outputname1 == "TSE":outputname1 ="上市"else :outputname1= "上櫃"fig = plt.figure(figsize=(6,6))grid = plt.GridSpec(3, 3, wspace=0.4, hspace=0.3)ax1=plt.subplot(grid[:2, :])ax2=plt.subplot(grid[2, :])date= [i for i in range(len(out))]##### 獲取 0開始的順序 因為如果使用原日期假日會有空缺out_index= [tuple([date[i],out.開盤價[i],out.最高價[i],out.最低價[i],out.收盤價[i]]) for i in range(len(out))]candlestick_ohlc(ax1, out_index, width=0.6, colorup='r', colordown='g', alpha=0.75)ax1.set_xticks(range(0, len(out.index), 10))ax1.set_xticklabels(out.index[::10])ax1.set_title([str(out["證券碼"][0]),outputname0,outputname1,outputname2])ax1.set_ylabel('Price')ax1.grid(linestyle="--",alpha=0.8)red_pred = np.where(out["收盤價"] >= out["開盤價"],out["成交量(千股)"], 0)blue_pred = np.where(out["收盤價"] < out["開盤價"], out["成交量(千股)"], 0)out1=out.reset_index(drop=True )ax2.bar(out1.index,red_pred, facecolor="red")ax2.bar(out1.index,blue_pred,facecolor="green")ax2.set_xticks(range(0, len(out.index), 5))ax2.set_xticklabels(out.index[::5])ax2.set_ylabel('vol')plt.legend(loc='best')fig.autofmt_xdate()fig.tight_layout()plt.show()
此程式能將畫出股票的k線以及成交量在同一張圖上
getplot(a) ###前面聚合後的List(a)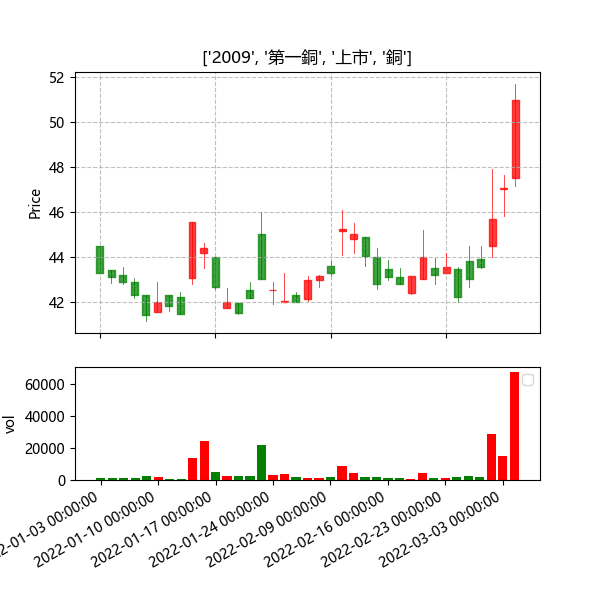
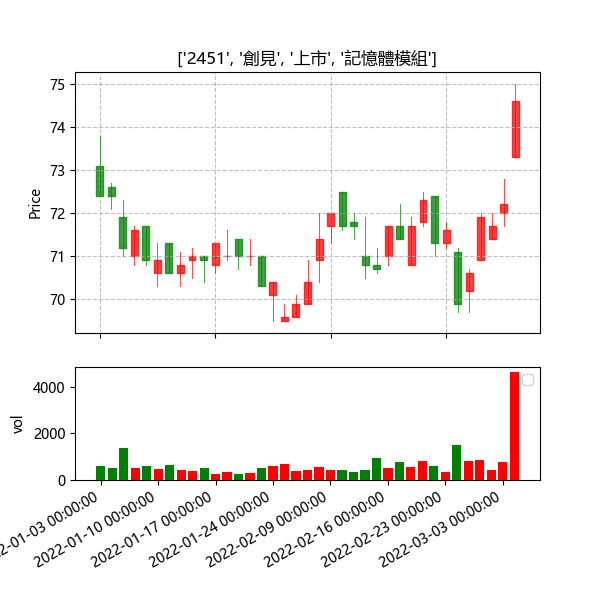
就會畫出篩選的股票啦,也可以在此加入均線等等讓圖看起來更豐富,每天都可以用這個程式自動篩選股票。
藉由這次程式的篩選,我們依然能找到這次大跌下的強勢股,也是一個可以用來挑選標地物的好方法,配合上次的量能回測的操作模式或許是一個不錯的獲利模式,而更改篩選參數也能找到出量下跌的標的,每個人對於投資都有自己喜歡的方式,而我們能藉由程式的方式找尋符合自己進場邏輯的標的,以節省下許多挑選的時間,所以歡迎對各種交易回測有興趣的讀者,選購TEJ E-Shop的相關方案,用高品質的資料庫,建構出適合自己的交易策略。
