
Table of Contents
近來演算法興起,發展出各式各樣的數學模型用以分析並解決問題,經典的演算法為「迴歸模型」,但隨著科技的進步,發展出能自我改進學習的算法 — 機器學習(Machine Learning),發展至今成為最火熱的類累神經網路模型 (Deep Learning)。
本文章介紹樹狀模型 XGBoost,文章將會分兩部分,上半段為環境設定與模組安裝,以及資料庫的介紹。下半段為資料的預處理,模型的訓練、預測和視覺化。
先來介紹當今火紅的的演算法 XGBoost,所謂的 Boosting 就是一種將許多弱學習器集合起來,變成一個更強大的學習器,對於最終預測結果都有更高的準確度。
XGBoost ( Extreme Gradient Boosting ),是一種擬合殘差的梯度下降算法 Gradient Boosted Tree (GBDT),每一步學習是基於之前的錯誤中進步,並會保留原本的模型,並加入新的函數,作為修正上次學習的錯誤,此為集合多個弱學習器。應用方面主要解決監督式學習,可以處理分類也可以解決迴歸問題。
本文使用 Mac OS 並以 Jupyter Notebook 作為編輯器
由於 XGBoost 使用到眾多的模組,如果版本不一致會產生報不完的錯誤。我們可以建立新的環境來安裝這些模組,安裝的方式有很多種方法,本安裝為較為簡單易懂的方式,以求發生最少錯誤。

Anaconda 可以說是初學者的懶人包,解決目前各系統的不一致導致安裝困難的狀況,擁眾多愛好者及企業用戶外,整理了超過1000種的 Packages可安裝,適用於 Windows、Linux 和 MacOS 不同作業系統環境,也具虛擬環境管理器,對於在安裝、執行機器學習環境上變得簡單快速
Windows 系統的話可以點 Anaconda Prompt
輸入建立環境指令
conda create -n 新環境名稱 python==3.8
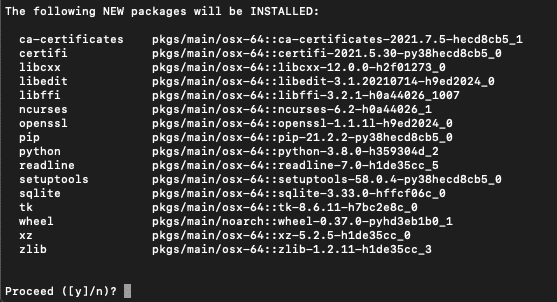
會跳出問你是否安裝,輸入 y 再按 enter 就成功了!我們新環境名稱範例為 test,當然也可以輸入你喜歡的名稱
conda env list
我們可以輸入以上指令,查看目前我們有哪些的虛擬環境,確認一下有建立成功
conda activate 新環境名稱
此時終端機最前面括號 (base) 就會變成我們剛剛建立新環境的名稱 (test),代表啟動成功
如果之後安裝失敗,要重新安裝,我們只要簡單的輸入一串指令就可以移除新創的環境,再重新安裝一次,完全不用擔心影響其他的環境
conda env remove -n 新環境名稱
conda activate 新環境名稱
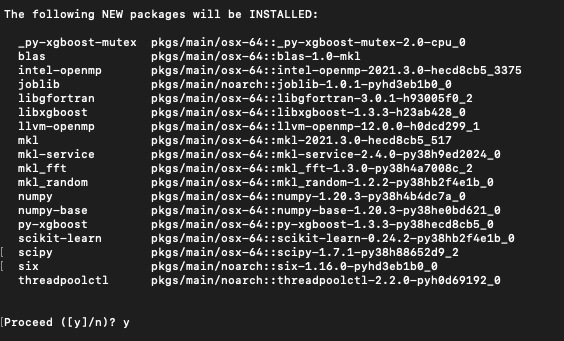
conda install py-xgboost
一樣會詢問是否要安裝這些模組,輸入 y 再按 enter 就開始安裝了,跑完就成功啦!是不是非常簡單!
Homebrew 我們可以理解為一種安裝方式,例如 python 的模組安裝是使用 pip ,而在 macOS,Homebrew 就是最被廣為使用的套件管理工具。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"在終端機上輸入上串指令以安裝
brew install graphviz
以上就是我們這次文章主要會用到的模組了!不過在新環境裡,XGBoost 沒有部份我們需要的模組,就得另外安裝一下,各模組中間用空格隔開
pip install pandas matplotlib tejapi

最後趕快在 jupyter 檢視是否成功安裝!
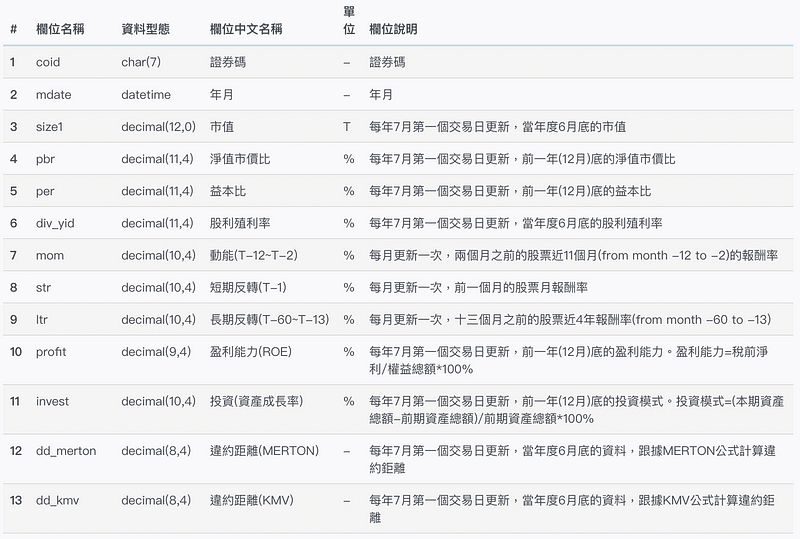
本文章將使用 台灣_多因子DB(TWN/AFF_RAW) 裡面所提供的交易因子,作為演算法需的變數,此資料庫參考 Kenneth R. French 網頁及 2000 年以來於財金前三大期刊 (JF、RFS、JFE) 發表的重要且有用投資因子,將各學者衡量因子的指標,利用台灣市場資料計算好,以月頻率方式將所有指標的資料整理好。
df = tejapi.get('TWN/AFF_RAW',
coid = '9921',
mdate={'gte': '2015-01-01', 'lte':'2020-12-31'}
chinese_column_name = True,
paginate = True)
本文章上半部分為講解模組安裝,相信大部分的人在一開始接觸程式時,一定會到許多安裝上的狀況,裝來裝去還是沒辦法成功,最後電腦要整台重灌,因此環境的安排也是一個重要的課題喔!在大家都成功安裝後,文章下半部分會開始使用資料庫,處理數據,把資料餵給模型,最後得出我們要的預測值,作為我們投資的參考。
