Table of Contents
文章難度:★☆☆☆☆
使用前15名買賣超量與總成交量建構籌碼集中度指標,以及券商總買賣量、參與券商數和排名來建構買賣集中度指標
閱讀建議:本文主要透過籌碼資料來建構集中度相關指標,並用資料視覺化的方式呈現,需要讀者對資料視覺化與籌碼資料有一定的認識。
台灣股票市場屬於淺碟市場,所謂淺碟代表的是沒有深度,容易受到外部的震盪,而在股票市場則代表,容易受到外部力量干擾,而有明顯的漲跌幅情況,像是受到新聞的影響、或是投資大戶對單一股票大量的買入,都會明顯影響股價表現,而本文使用了幾個籌碼資料,來探討當籌碼集中於一檔股票時,對股價的影響為何,並用互動式的圖表呈現。
本文使用Mac OS並以jupyter作為編輯器
import pandas as pd
import numpy as np
import tejapi
import matplotlib.pyplot as plt
import matplotlib.transforms as transforms
from matplotlib.font_manager import FontProperties
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 解決MAC電腦 plot中文問題
plt.rcParams['axes.unicode_minus'] = False
tejapi.ApiConfig.api_key ="Your Key"
tejapi.ApiConfig.ignoretz = True
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
調整股價(日)-除權息調整(TWN/APRCD1)
主要券商進出明細-券商別(TWN/AMTOP)
資料期間取自2017年到2022年,以台積電作為例子,分別取得了買進股數、賣出股數、成交量以及收盤價資料。
df = tejapi.get('TWN/AMTOP1', #從TEJ api撈取所需要的資料
chinese_column_name = True,
paginate = True,
coid='2330',
mdate = {'gt':'2017-01-01'},
opts={'columns':['coid','mdate', 'key3','buy', 'sell', 'total']})
df1 = tejapi.get('TWN/APRCD1', #從TEJ api撈取所需要的資料
chinese_column_name = True,
paginate = True,
coid='2330',
mdate = {'gt':'2017-01-01'},
opts={'columns':['coid','mdate', 'volume', 'close_adj']})
將資料NA值刪掉,並將買進股數由大到小排序,並取出每日買進股數的最大前15筆資料
df.dropna(inplace=True)
df.sort_values(['日期','買進股數'], ascending=[1,0], inplace=True)#根據買進股數由大到小排序
df_buy = df.groupby(['日期']).head(15)#取出每個日期的前15筆
創一個新的Dataframe,並用日期當index,把剛剛篩選出來的每日買進股數作加總,放進新的表中
result = pd.DataFrame(index=df_buy['日期'].unique())#創一個新的表,日期當index
result['買進股數'] = df_buy.groupby(['日期'])['買進股數'].sum()# 把每個日期的前15筆買進股數加總
用跟買進股數一樣的方式處理賣出股數的部分
df.sort_values(['日期','賣出股數'], ascending=[1,0], inplace=True)#根據賣出股數由大到小排序
df_sell = df.groupby(['日期']).head(15)#取出每個日期的前15筆
result['賣出股數'] = df_sell.groupby(['日期'])['賣出股數'].sum()
將買進股數跟賣出股數,根據比較常見的60日跟120日做rolling的總和
result_60 = result.rolling(60).sum() #根據n日做買進/賣出rolling 總和
result_60.rename(columns = {'買進股數':'買進股數_60', '賣出股數':"賣出股數_60"}, inplace=True)
result_120 = result.rolling(120).sum() #根據n日做買進/賣出rolling 總和
result_120.rename(columns = {'買進股數':'買進股數_120', '賣出股數':"賣出股數_120"}, inplace=True)
把成交量也做60日跟120日的rolling總和,並且跟剛剛買賣股數的table做合併
df1['成交量(千股)_60'] = df1['成交量(千股)'].rolling(60).sum()
df1['成交量(千股)_120'] = df1['成交量(千股)'].rolling(120).sum()
result2 = pd.merge(result_60, df1[['成交量(千股)_60', '成交量(千股)_120','收盤價(元)']], left_index=True, right_index=True) #把成交量跟買進/賣出合起來
result3 = pd.merge(result2, result_120, left_index=True, right_index=True) #把成交量跟買進/賣出合起來
接著根據籌碼集中度的公式:((買方前15名近n日的總買超量-賣方前15名近n日的總賣超量)/近n日的總成交量)*100,把籌碼集中度計算出來
result3['60日籌碼集中度'] = ((result3['買進股數_60'] - result3['賣出股數_60'])/result2['成交量(千股)_60'])*100
result3['120日籌碼集中度'] = ((result3['買進股數_120'] - result3['賣出股數_120'])/result2['成交量(千股)_120'])*100
# ((買方前15名近n日總買超量 - 賣方前15名近n日總賣超量) / 近n日總成交量)*100
透過plotly套件將結果作成互動式的圖表,也能方便觀察特定時間的趨勢,從圖中可以看到,在疫情最恐慌的時期,台積電的60日籌碼集中度創下了自2017年以來的新低,可見籌碼大量分散,股價也跌至波段的低谷。
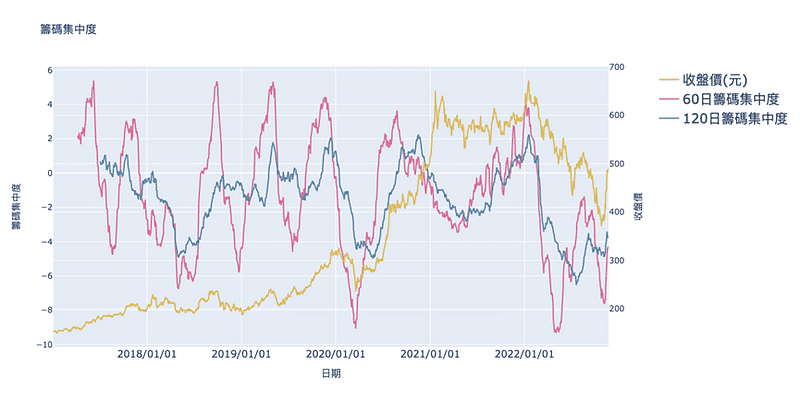
資料期間取自2021年中到2022年,以台積電作為例子,分別取得了券商名稱、券商代碼、買進股數、賣出股數。
df2 = tejapi.get('TWN/ABSR', #從TEJ api撈取所需要的資料
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2021-06-30', 'lt':'2022-11-22'},
coid="2330",
opts={'columns':['coid','mdate','key3','brk_nm','buy_s','sell_s']})
將買進股數跟賣出股數由大到小排序,並使用rank function針對每個日期的不同券商排名
df2_buy = df2.sort_values(['年月日','買進股數(股)'], ascending=[1,0]).reset_index(drop=True)
df2_sell = df2.sort_values(['年月日','賣出股數(股)'], ascending=[1,0]).reset_index(drop=True)
df2_buy['排名'] = df2_buy.groupby('年月日')['買進股數(股)'].apply(lambda x: x.rank(method='dense' ,ascending=False))
df2_sell['排名'] = df2_sell.groupby('年月日')['賣出股數(股)'].apply(lambda x: x.rank(method='dense' ,ascending=False))
計算買進張數、賣出張數、排名*張數以及每日參與的券商總數,用以後續指標計算使用
df2_buy['買進張數'] = df2_buy['買進股數(股)']/1000
df2_buy['名次_張數'] = df2_buy['排名']*df2_buy['買進張數']
attend = df2_buy.groupby('年月日')['買進股數(股)'].count()
attend.name = '參與交易券商數'
df2_buy = df2_buy.merge(attend, on='年月日')
df2_buy.set_index('年月日', inplace=True)
df2_sell['賣出張數'] = df2_sell['賣出股數(股)']/1000
df2_sell['名次_張數'] = df2_sell['排名']*df2_sell['賣出張數']
attend1 = df2_sell.groupby('年月日')['賣出股數(股)'].count()
attend1.name = '參與交易券商數'
df2_sell = df2_sell.merge(attend, on='年月日')
df2_sell.set_index('年月日', inplace=True)
買進集中度公式:(((SUM(買進張數)*參與交易券商數)/2)-(SUM(買進張數)/2)+(SUM(買進張數)*排名))/(SUM(買進張數)*排名)/2
賣出集中度公式:(((SUM(賣出張數)*參與交易券商數)/2)-(SUM(賣出張數)/2)+(SUM(賣出張數)*排名))/(SUM(賣出張數)*排名)/2
差值:買進集中度-賣出集中度
因為公式計算上較為複雜,所以在計算上我將他分成a,b,c三部分來計算,最後計算出買進集中度、賣出集中度以及差值
result = pd.DataFrame(index=(df2_buy.index).unique())
result['a1'] = ((df2_buy.groupby('年月日')['買進張數'].sum())*(df2_buy.groupby('年月日')['參與交易券商數'].head(1)))/2
result['b1'] = (df2_buy.groupby('年月日')['買進張數'].sum())/2
result['c1'] = df2_buy.groupby('年月日')['名次_張數'].sum()
result['a2'] = ((df2_sell.groupby('年月日')['賣出張數'].sum())*(df2_buy.groupby('年月日')['參與交易券商數'].head(1)))/2
result['b2'] = (df2_sell.groupby('年月日')['賣出張數'].sum())/2
result['c2'] = df2_sell.groupby('年月日')['名次_張數'].sum()
result['買進集中度'] = (result['a1'] - (result['b1']+result['c1']))/result['a1']
result['賣出集中度'] = (result['a2'] - (result['b2']+result['c2']))/result['a2']
result['差值'] = result['買進集中度'] - result['賣出集中度']
將買進集中度、賣出集中度、差值跟台積電的收盤價整合進同一張table,方便後續繪圖
final = result[['買進集中度','賣出集中度','差值']].merge(result3.loc['2021-07-01':]['收盤價(元)'], left_index=True,right_index=True)
先將差值隱藏更好觀察這張圖表,可以發現不管是買進集中度或是賣出集中度的波動都非常大,較難觀察到趨勢與股價的走勢是否有一致的存在,再來觀察看看差值與股價的關係。
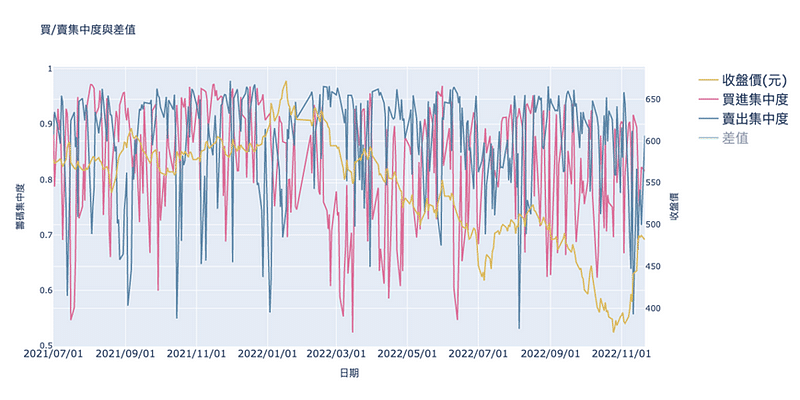
而從差值與台積電收盤價來看就比較清楚,當差值較大的時候,台積電當天的收盤價表現得較好,反之,當差值呈現下降趨勢的話,台積電的收盤價也呈現下降的趨勢,可見籌碼集中度即便是對於像台積電這種市值跟成交量龐大的公司也仍有一定的效果存在。
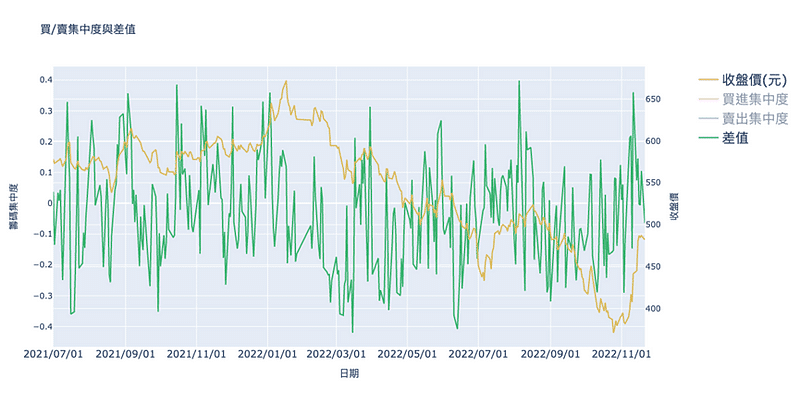
我們能從結果看到,無論是第一種60/120日籌碼集中度或是第二種買/賣出指標與差值,都可以看到籌碼集中度對股價的影響,當集中度越低或是差值越小的時候,股價往往是回落的,需要注意的是,讀者如果想使用在程式交易或是學術研究上時,可能需要考慮進一步的平滑化,否則波動這麼大的資料容易有過度產生訊號或是有定態的問題。
之後也會介紹使用TEJ資料庫來建構各式指標,並回測指標績效,所以歡迎對各種交易回測有興趣的讀者,選購TEJ E-Shop的相關方案,用高品質的資料庫,建構出適合自己的交易策略。
最後,還是要再次提醒本文所提及之標的僅供說明使用,不代表任何金融商品之推薦或建議。因此,若讀者對於建置策略、績效回測、研究實證等相關議題有興趣,歡迎選購 TEJ E Shop中的方案,具有齊全的資料庫,就能輕易的完成各種檢定。
