
Table of Contents
在產業輪動的脈絡中,我們觀察到一項耐人尋味的現象:航運指數的轉強,似乎經常領先於半導體的上漲。這樣的關聯性若能被驗證並轉化為可操作的邏輯,便可能成為投資決策中的寶貴線索。
本篇將以前文「從數據觀察產業輪動:解構航運與半導體的領先與落後關係」的實證分析為基礎,進一步探討如何將「航運領先、半導體跟隨」的輪動假說,轉化為具體的資產配置策略。我們將結合景氣燈號、產業表現指標與時序條件,建構一套回測框架,模擬歷史期間的實際操作情境。透過策略績效的評估,我們希望回答一個核心問題:若航運真的能預告半導體行情,我們該如何跟上這波接力賽?
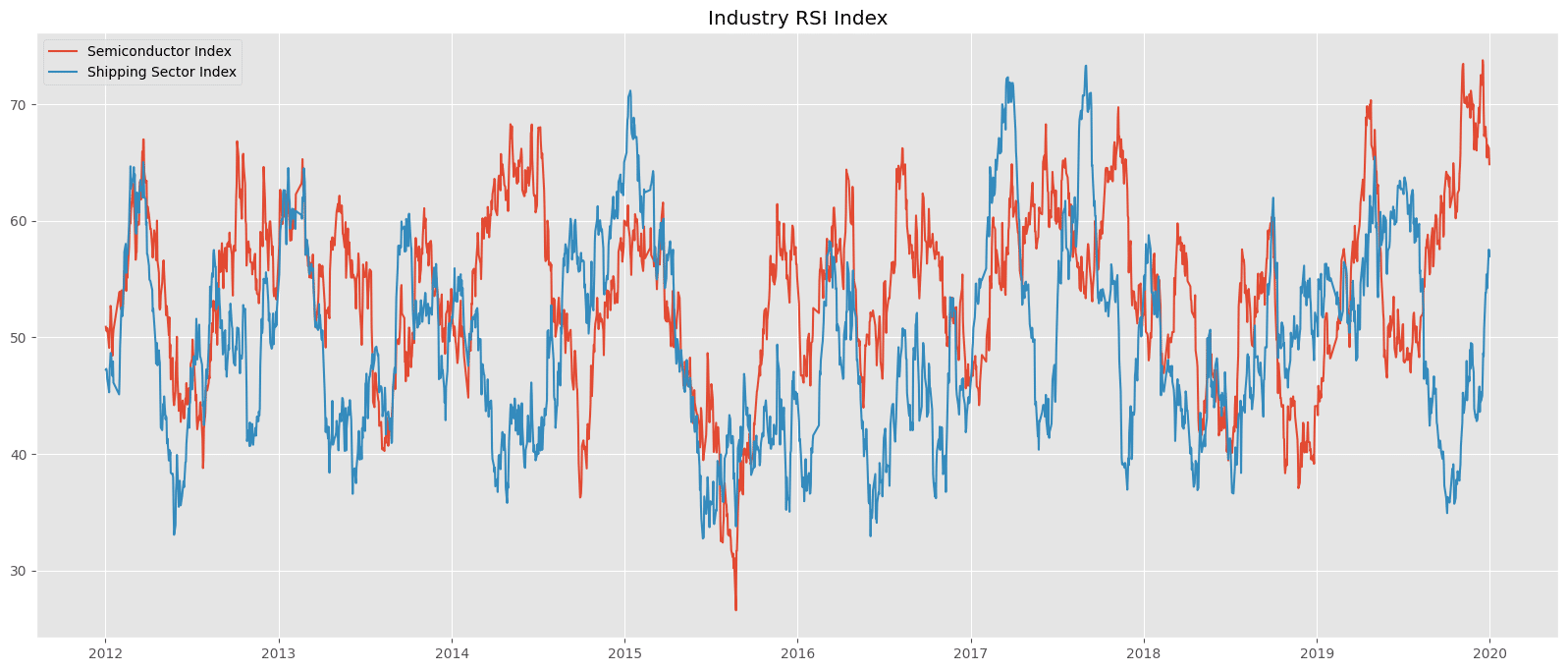
我們可以觀察到上一篇文章的分析結果,研究時間為2012-2020年初,航運產業以及半導體產業的 RSI 數值確實呈現明顯的輪動關係,接下來則是需要去關心我們如何利用這種輪動關係,設計出一套可靠的投資策略。為了避免前世偏誤,我們使用2020以後的市場資料當作策略回測時研究的對象,這會讓我們的策略分析更加可靠。
👉 前情提要:從數據觀察產業輪動:解構航運與半導體的領先與落後關係
從文章「從景氣燈號到資產輪動:一套避開熊市的量化策略」當中可以得知,通過景氣信號燈的信號可以有效避開熊市的波動,只在牛市持有股票部位,熊市持有短天期國債等避險資產,並且回測出不錯績效結果。搭配上述觀察的產業輪動現象「航運 → 半導體」,我們可以在牛市階段觀察到產業輪動的信號時,將原本持有的 0050 ETF 短期置換成產業輪動的相關股票(半導體類股),賺取資金輪動的報酬之後再換回 0050 ETF ,期望這樣的操作可以優化上述文章的績效結果。策略的比較基準為台股加權報酬率指數 (IR0001),後續簡稱大盤。
實際操作方式為在景氣信號燈處於上升階段時,如果觀察到航運類指數的 RSI 數值大於65(我們認為當時該產業處於相對高點,產業循環開始),則買入持有半導體相關類股(選擇有代表性的大公司作為標的),直到半導體指數的 RSI 數值相對於買入時上升 15(產業循環結束),則出場賣出半導體類股並買回 0050 ETF。若產業循環未結束時市場進入熊市則平倉掉所有股票部位,買入短天期債券(這部分設計與景氣週期文章相同)。
在本策略中,針對「半導體產業」的資產配置,我選取了十檔具代表性的台灣半導體相關個股,涵蓋從上游晶圓代工到中游IC設計、下游封裝測試與記憶體等完整供應鏈。具體包括:
晶圓代工:台積電(2330)與聯電(2303)為晶圓代工雙雄,分別代表先進製程與成熟製程的核心廠商;世界先進(5347)則專攻8吋晶圓,聚焦利基市場。
IC設計:聯發科(2454)為全球主要手機與通訊晶片設計商;聯詠(3034)與天鈺(4961)則專精於顯示器驅動IC,屬於面板供應鏈重要角色。
封裝與測試:日月光投控(3711)、力成(6239)與欣銓(3264)為主要封裝與測試廠商,涵蓋後段製程與測試服務。
記憶體:南亞科(2408)為台灣DRAM大廠,與全球記憶體價格與供需循環關聯性高。
這些個股共同構成台灣半導體產業的關鍵結構,亦具備足夠流動性與市值,適合用於實證回測與資金配置的模擬。
import tejapi
import pandas as pd
import numpy as np
tejapi.ApiConfig.api_key = "your key"
tejapi.ApiConfig.api_base = "https://api.tej.com.tw"
# ========================================================
# 下載景氣信號燈的分數資料
data = tejapi.get('GLOBAL/ANMAR', mdate={'gte':'2000-01-01', 'lte':'2025-04-09'}, coid = 'EA1101')
# ========================================================
# 下載 0050 ETF 以及 00865B ETF 的調整後價格資料
data2 = tejapi.get('TWN/AAPRCDA', coid = ['0050'], mdate={'gte':'2000-01-01', 'lte':'2025-04-09'})
df_price = data2[['mdate','close_d', 'avgclsd']].copy()
data3 = tejapi.get('TWN/AAPRCDA', coid = ['00865B'], mdate={'gte':'2000-01-01', 'lte':'2025-04-09'})
df_bond = data3[['mdate','close_d', 'avgclsd']].copy()
# ========================================================
data['mdate'] = pd.to_datetime(data['mdate'])
data['val_shifted'] = data['val'].shift(1)
df_price['mdate'] = pd.to_datetime(df_price['mdate'])
df_bond['mdate'] = pd.to_datetime(df_bond['mdate'])
data = data.set_index('mdate', drop=False)
df_price = df_price.set_index('mdate', drop=False)
df_bond = df_bond.set_index('mdate', drop=False)
df_P_daily = data.resample('D').ffill()
df = df_price.join(df_P_daily, how = 'left', rsuffix='_P')
df = df.join(df_bond, how = 'left', rsuffix='_bond')
df['mdate'] = df['mdate'].dt.strftime('%Y-%m-%d')
df['mdate'] = pd.to_datetime(df['mdate'])
# ========================================================
# 將兩筆資料視覺化,觀察其過去情況
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=3, ncols=1, figsize=(20, 10), sharex=True)
plt.style.use('ggplot')
axes[1].plot(df['mdate'], df['avgclsd'], label = '0050 Price')
axes[1].set_title(f'0050 History Price')
axes[1].legend()
axes[0].plot(df['mdate'], df['val_shifted'], label = 'SCORE')
axes[0].axhline(y = 38, label = 'Red Light Bound', color = 'red', linestyle = '--')
axes[0].axhline(y= 16, label = 'Blue Light Bound', color = 'blue', linestyle = '--')
axes[0].set_title(f'SCORE')
axes[0].legend()
axes[2].plot(df['mdate'], df['avgclsd_bond'], label = 'Short_term_bond Price')
axes[2].set_title(f'00865B Short_term_bond History Price')
axes[2].legend()
plt.tight_layout()
plt.show()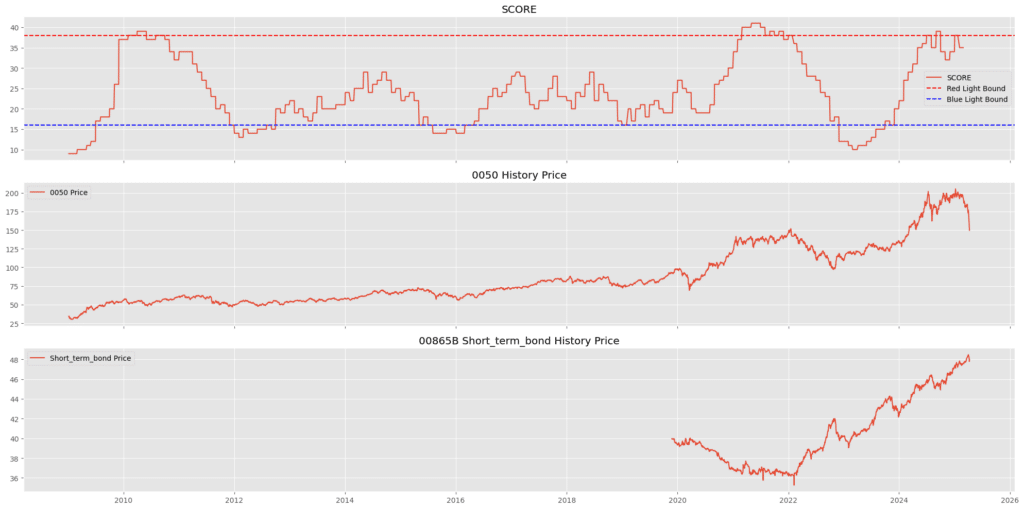
codes = [
"IX0001", "IX0002", "IX0003", "IX0006", "IX0010", "IX0011", "IX0012",
"IX0016", "IX0017", "IX0018", "IX0019", "IX0020", "IX0021", "IX0022",
"IX0023", "IX0024", "IX0025", "IX0026", "IX0027", "IX0028", "IX0029",
"IX0030", "IX0031", "IX0032", "IX0033", "IX0034", "IX0035", "IX0036",
"IX0037", "IX0038", "IX0039", "IX0040"
]
names = [
"加權指數", "台灣50指數", "台灣中型指數", "台灣高股息指數", "水泥工業類指數",
"食品工業類指數", "塑膠工業類指數", "紡織纖維類指數", "電機機械類指數",
"電器電纜類指數", "化學生技醫療類指數", "化學工業指數", "生技醫療指數",
"玻璃陶瓷類指數", "造紙工業類指數", "鋼鐵工業類指數", "橡膠類指數",
"汽車工業類指數", "電子類指數", "半導體業指數", "電腦及週邊設備業指數",
"光電業指數", "通信網路業指數", "電子零組件業指數", "電子通路業指數",
"資訊服務業指數", "其他電子業指數", "建材營造類指數", "航運業類指數",
"觀光事業類指數", "金融保險類指數", "貿易百貨類指數"
]
import pandas as pd
import numpy as np
import tejapi
import os
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Arial'
tej_key = "your key"
tejapi.ApiConfig.api_key = tej_key
os.environ['TEJAPI_BASE'] = "https://api.tej.com.tw"
os.environ['TEJAPI_KEY'] = tej_key
start_dt = pd.Timestamp('2006-01-01', tz = 'UTC')
end_dt = pd.Timestamp('2025-04-23', tz = "UTC")
import TejToolAPI
co = ['coid','Industry', 'mkt', 'vol', 'open_d', 'high_d', 'low_d', 'close_d', 'roi', 'shares', 'per', 'pbr_tej','mktcap']
data = TejToolAPI.get_history_data(start = start_dt,
end = end_dt,
ticker = codes,
columns = co,
transfer_to_chinese = True)
data_use = data.pivot(index='日期', columns='股票代碼', values='收盤價')
def compute_rsi(series, period = 60):
delta = series.diff()
gain = delta.where(delta > 0, 0.0)
loss = -delta.where(delta < 0, 0.0)
avg_gain = gain.rolling(window=period).mean()
avg_loss = loss.rolling(window=period).mean()
rs = avg_gain / avg_loss
rsi = 100 - (100 / (1 + rs))
return rsi
df_ind = data_use.iloc[:, 1:].apply(compute_rsi)
df_ind['mdate'] = df_ind.indeximport os
import tejapi
plt.rcParams['font.family'] = 'Arial'
tej_key = 'your key'
os.environ['TEJAPI_BASE'] = "https://api.tej.com.tw"
os.environ['TEJAPI_KEY'] = tej_key
from zipline.data.run_ingest import simple_ingest
from zipline.api import set_slippage, set_commission, set_benchmark, symbol, record
from zipline.api import order_target_percent, order_percent, order
from zipline.api import set_long_only, set_max_leverage
from zipline.finance import commission, slippage
from zipline import run_algorithm
semiconductor_stocks = [
'2330', # 台積電:晶圓代工龍頭
'2303', # 聯電:成熟製程晶圓代工
'2408', # 南亞科:DRAM 記憶體
'3711', # 日月光投控:封裝與測試
'3034', # 聯詠:顯示器 IC 設計
'2454', # 聯發科:手機與通訊 IC 設計大廠
'5347', # 世界先進:8 吋晶圓代工
'6239', # 力成:封裝測試服務
'3264', # 欣銓:測試服務為主
'4961' # 天鈺:顯示驅動 IC
]
pool = ['0050', 'IR0001', '00865B'] + semiconductor_stocks
start_date = '2009-01-01'
end_date = '2025-04-30'
start_ingest = start_date.replace('-', '')
end_ingest = end_date.replace('-', '')
simple_ingest(name = 'tquant' , tickers = pool , start_date = start_ingest , end_date = end_ingest)
def initialize(context, pool = pool):
set_slippage(slippage.TW_Slippage(spread = 1 , volume_limit = 1))
set_commission(commission.Custom_TW_Commission(min_trade_cost=20, discount=1.0, tax = 0.003))
set_benchmark(symbol('IR0001'))
context.i = 0
context.pool = pool
context.state = False
context.score = None
context.hedge_state = None
context.buy_date = []
context.sell_date = []
context.a = 0
context.b = 0
context.bond = symbol('00865B')
context.stock = symbol('0050')
context.semi = None
context.boat = None
context.cycle2 = False
context.aa = 0
context.bb = 0
context.cycle_start_date = []
context.cycle_end_date = []
def handle_data(context, data, score_data = df, ind_data = df_ind):
backtest_date = data.current_dt.date()
today_data = score_data[score_data['mdate'] == pd.to_datetime(backtest_date)]
context.last_score = context.score # 記錄舊的 score
if not today_data.empty:
context.score = today_data['val_shifted'].iloc[-1]
else:
# 若無資料,就沿用舊的 score
context.score = context.last_score
today_data_2 = ind_data[ind_data['mdate'] == pd.to_datetime(backtest_date)]
context.semi = today_data_2["IX0028"].iloc[-1]
#context.bio = today_data_2['IX0021'].iloc[-1]
context.boat = today_data_2['IX0037'].iloc[-1]
record(score = context.score)
if context.state == True:
# ==================================================================
if context.boat >= 65 and context.cycle2 == False :
print(f'{backtest_date} : Cycle 2 Start')
context.cycle_start_date.append(pd.to_datetime(backtest_date))
context.cycle2 = True
order_target_percent(symbol('0050'), 0)
for i in semiconductor_stocks:
order_target_percent(symbol(i), 1.0 / len(semiconductor_stocks))
context.a = context.semi
if context.cycle2 == True and context.semi >= context.a + 15:
print(f'{backtest_date} : Cycle 2 End')
context.cycle_end_date.append(pd.to_datetime(backtest_date))
context.cycle2 = False
for i in semiconductor_stocks:
order_target_percent(symbol(i), 0)
order_target_percent(symbol('0050'), 1.0)
# ==================================================================
if context.hedge_state == True and context.cycle2 == True:
print(f'Bull Market Ending')
#context.end_date.append(pd.to_datetime(backtest_date))
for i in semiconductor_stocks:
order_target_percent(symbol(i), 0)
order_target_percent(symbol('0050'), 0)
context.cycle2 = False
# ==================================================================
if context.score <= 16 and context.state == False:
order_target_percent(context.stock, 1.0)
print(f"Date: {backtest_date}, Score: {context.score}, 買進 0050")
context.buy_date.append(pd.to_datetime(backtest_date))
context.state = True
if context.hedge_state == True:
order_target_percent(context.bond, 0)
print(f"Date: {backtest_date}, Score: {context.score},賣出債券")
context.hedge_state = False
if context.score >= 38 and context.state == True:
order_target_percent(context.stock, 0)
print(f"Date: {backtest_date}, Score: {context.score}, 賣出 0050")
context.sell_date.append(pd.to_datetime(backtest_date))
context.state = False
if context.hedge_state == False :
order_target_percent(context.bond, 1.0)
print(f"Date: {backtest_date}, Score: {context.score},買入債券避險")
context.hedge_state = True
if context.score > 16 and context.score < 38 and context.aa == 0:
context.aa = 1
print('進入景氣循環')
if context.state == False:
order_target_percent(context.stock, 1.0)
print(f"Date: {backtest_date}, Score: {context.score}, 買進 0050 ETF")
context.buy_date.append(pd.to_datetime(backtest_date))
context.state = True
# 因為 00685B 從 2019-11-25 才開始被交易
if pd.to_datetime(backtest_date) >= pd.to_datetime('2019-11-25') and context.bb == 0:
context.bb = 1
context.hedge_state = False
record(Leverage = context.account.leverage)
df_ind_plot = df_ind[df_ind['mdate'] >= pd.to_datetime('2020-01-01')]
plt.rcParams['font.family'] = 'DejaVu Sans'
def analyze(context, perf):
plt.style.use('ggplot')
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(18, 15), sharex=True)
axes[0].plot(perf.index, perf['algorithm_period_return'], label = 'strategy')
axes[0].plot(perf.index, perf['benchmark_period_return'], label = 'benchmark')
for idx, i in enumerate(context.buy_date):
if idx == 0:
axes[0].axvline(x = i, color = 'red', label = 'Bull Market Start', linestyle = '--', alpha = 0.5)
axes[0].axvline(x = i, color = 'red', linestyle = '--', alpha = 0.5)
for idx, i in enumerate(context.sell_date):
if idx == 0:
axes[0].axvline(x = i, color = 'black', label = 'Bear Market Start', linestyle = '--', alpha = 0.5)
axes[0].axvline(x = i, color = 'black', linestyle = '--', alpha = 0.5)
for idx, i in enumerate(context.cycle_start_date):
if idx == 0:
axes[0].axvline(x = i, linestyle = '--', color = '#F39C12', label = 'Cycle Start')
else:
axes[0].axvline(x = i, linestyle = '--', color = '#F39C12')
for idx, i in enumerate(context.cycle_end_date):
if idx == 0:
axes[0].axvline(x = i, linestyle = '--', color = '#6C3483', label = 'Cycle End')
else:
axes[0].axvline(x = i, linestyle = '--', color = '#6C3483')
axes[0].set_title(f'Industry Rotation Algorithm_period_return')
axes[0].legend()
axes[1].bar(perf.index, perf['score'], label='score')
axes[1].set_title('Business cycle index')
axes[1].legend()
axes[2].plot(perf.index, perf['Leverage'], label = 'Leverage')
axes[2].set_title('Leverage')
axes[2].legend()
axes[3].plot(df_ind_plot.index, df_ind_plot['IX0028'], label = 'Semi index RSI')
axes[3].plot(df_ind_plot.index, df_ind_plot['IX0037'], label = 'Ship index RSI')
axes[3].set_title('Industry RSI')
axes[3].legend()
plt.tight_layout()
plt.show()
results = run_algorithm(
start = pd.Timestamp('2020-01-01', tz = 'utc'),
end = pd.Timestamp('2025-04-10', tz = 'utc'),
initialize = initialize,
handle_data = handle_data,
analyze = analyze,
bundle = 'tquant',
capital_base = 1e5)
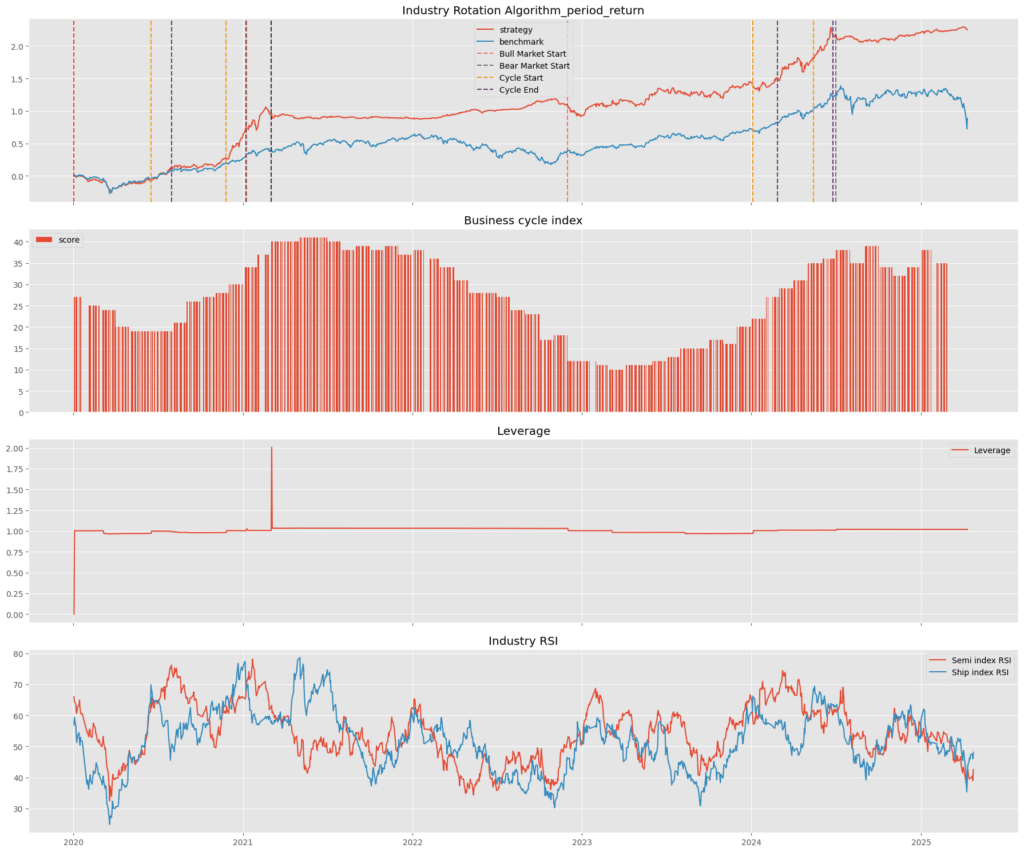
從第一張圖的策略績效比較來看,在整段牛市期間共偵測到 5 次「航運 → 半導體」的產業輪動信號(橘色線顯示的時間點)。其中,前 3 次出現在 2020 年,第 4, 5 次則發生於較後期。整體來說,這幾次輪動信號中,有 4 次成功捕捉到半導體類股的強勁上漲趨勢,分別為第 2 至 5 次。其中第2, 3次進場效果最為顯著,使得策略的累積報酬率大幅超越 台股大盤(Benchmark),達成我們預期透過輪動機制提升超額報酬的目標。第 4, 5 次雖也成功搭上半導體上漲波段,但由於當時整體台股行情主要由半導體所驅動,因此策略相較於大盤的超額報酬上漲力度有限。
第二張圖呈現回測期間的景氣指數(score),對應每次景氣輪動信號的背景經濟環境。可以發現,每次策略進場時機大多落在景氣由谷底回升或進入擴張的初期階段,符合經濟循環與資金輪動的邏輯。
第三張圖則顯示策略於整段回測期間的槓桿使用情況。除了兩個時間點因牛熊轉換而發生的換倉操作使槓桿瞬間升高至 2.0,其餘大多數期間均維持在 1.0 左右,顯示整體策略並未依賴過度槓桿來強化績效,槓桿使用風險控制得宜。
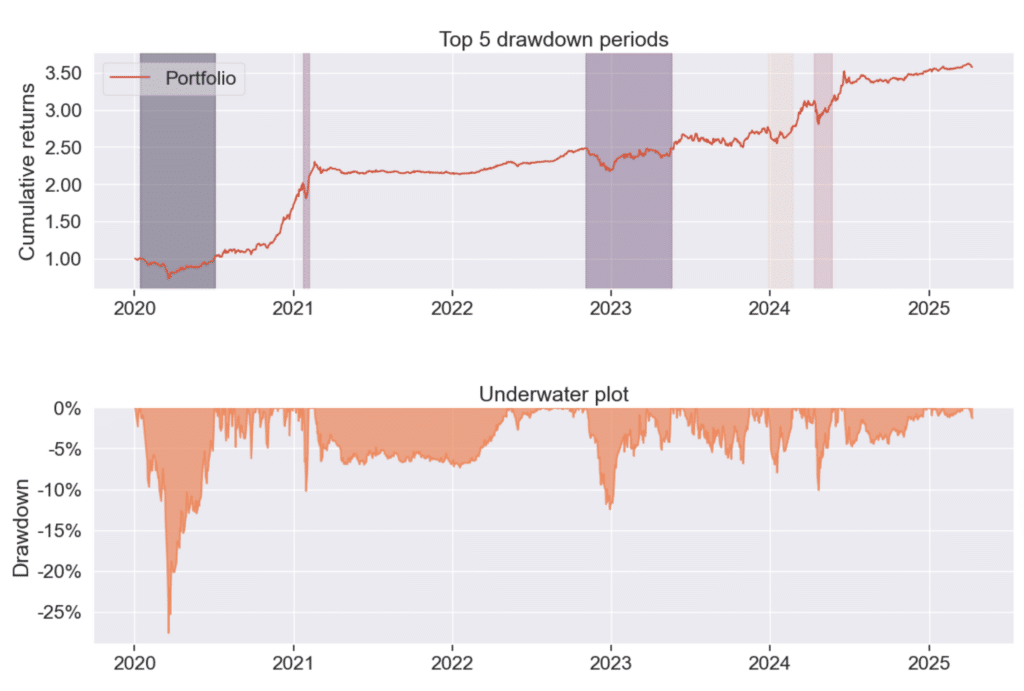
圖中顯示的是產業輪動策略的回撤圖以及深水圖,從圖中可以判斷大部分時期的回撤落在-10%以內,這是非常優秀的回撤結果,顯示出策略長期穩定獲利的能力。但是在2020年初有一小段時間的回撤為 -27% 左右,此時策略的持有標的為 0050 ETF 因此可以視為是市場的系統性風險所致。實際上當時的下跌段也是因為疫情的突然爆發而產生的,屬於黑天鵝事件,因此我們可以不用過於在意此時的下跌段。
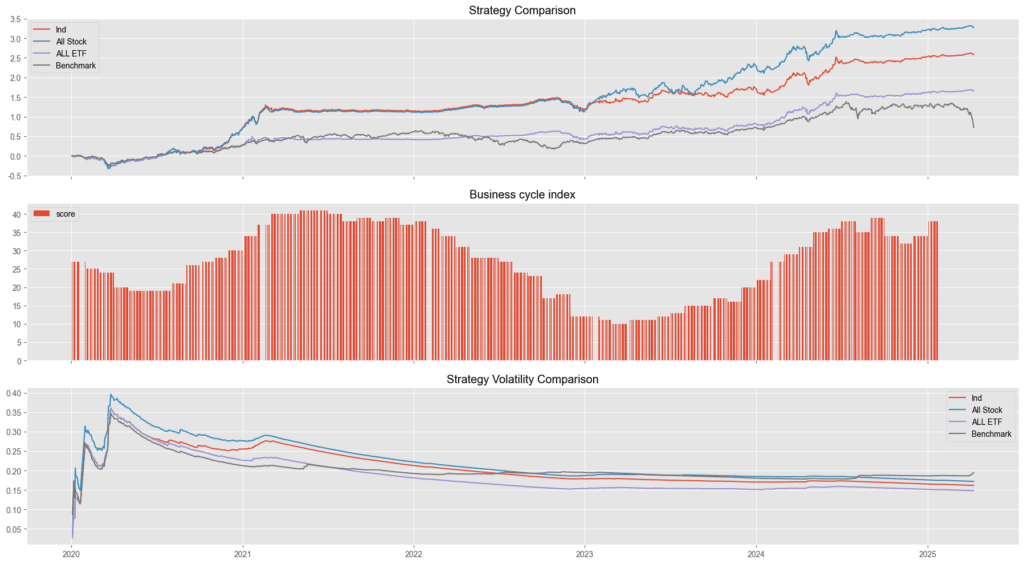
上圖呈現四種策略在回測期間的績效與風險比較:
從第一張圖的累積報酬表現可看出,藍色線策略雖然報酬率最高,但伴隨顯著波動風險。在第三張圖的波動度比較中也能觀察到,其大部分時間的波動率均高於其他策略。
相比之下,本研究提出的產業輪動策略(紅色線)表現穩健且具備良好的風險控制能力。其報酬表現雖略低於全股票策略,但明顯高於純 ETF 策略,且波動度位於兩者之間,達成風險與報酬之間的平衡。整體而言,產業輪動策略未出現因頻繁調倉導致績效下滑的情況,反而在資金流向判斷與進出時機上展現出實質優勢,具有實務應用潛力。
策略比較表格與分析
| 績效指標/策略 | 產業輪動策略 | 牛市半導體策略 | 牛市0050策略 | Benchmark |
| 年化報酬率 | 28.584% | 33.23% | 21.24% | 12.047% |
| 累積報酬率 | 257.52% | 327.48% | 165.40% | 77.97% |
| 年化波動度 | 16.179% | 17.21% | 14.84% | 18.52% |
| 夏普值 | 1.64 | 1.75 | 1.37 | 0.71 |
| 卡瑪比率 | 1.04 | 0.98 | 0.77 | 0.45 |
| 最大回撤期間 | -27.60% | -34.07% | -27.60% | -26.74% |
| Alpha | 0.23 | 0.28 | 0.16 | 0 |
| Beta | 0.39 | 0.42 | 0.39 | 0.93 |
本文所提出的產業輪動策略,在多項績效指標中展現出良好的風險報酬平衡。年化報酬率達 28.58%,雖略低於牛市期間全買半導體的策略(33.23%),但明顯高於僅持有 0050 ETF 的策略(21.24%)與大盤基準(12.05%)。累積報酬率亦達到 257.52%,展現強勁的長期成長能力。在風險方面,產業輪動策略的最大回撤為 -27.60%,控制水準與 ETF 策略相當,顯著優於半導體策略的 -34.07%。整體來看,該策略雖不以極端高報酬為目標,卻有效兼顧風險控制與報酬穩定性。
進一步觀察風險調整後的績效指標,產業輪動策略的夏普值為 1.64,卡瑪比率為 1.04,兩者皆優於 ETF 與大盤,且在卡瑪比率上為四項策略中最高,顯示策略能在承受相對可控虧損的情況下,取得相對優異的年化報酬。此外,Alpha 值達 0.23,說明在扣除市場影響後,仍具備明顯的超額報酬能力;而 Beta 僅為 0.39,代表策略波動對市場變動的敏感度較低,具有防禦性資產配置的特性。綜合上述結果,產業輪動策略在風險與報酬之間取得良好平衡,為實務操作上具潛力且穩健的投資方法。
歡迎投資朋友參考,之後也會持續介紹使用 TEJ 資料庫來建構各式指標,並回測指標績效,所以歡迎對各種交易回測有興趣的讀者,選購 TQuant Lab 的相關方案,用高品質的資料庫,建構出適合自己的交易策略。
溫馨提醒,本次分析僅供參考,不代表任何商品或投資上的建議。
機器學習算法 XGBoost 提升技術指標一目均衡表的投資績效
