
Table of Contents
柏頓.墨基爾(Burton G. Malkiel)是 1970 年代以來最具影響力的經濟學家之一。他在 1973 年出版的傳世經典《漫步華爾街》中提出了著名的「隨機漫步理論」,認為市場大部分時間是有效率的,並強烈建議大眾應優先考慮低成本的指數化投資。
然而,墨基爾也深知市場並非完美無瑕,對於追求超越大盤的投資者,他提出了一套「生存指南」。 他主張投資者不應盲從技術分析,而應理性結合「磐石理論」(基本面內在價值)與「空中樓閣理論」(群眾心理預期),尋找具備成長潛力且價格合理的標的。其策略核心並非預測市場短期走勢,而是透過紀律化且可重複驗證的條件,篩選出「獲利具備成長潛力、但估值尚未被市場充分反映」的企業,藉此在長期投資中對抗市場的隨機波動。本研究將利用 TEJ 量化資料庫與 TQuant Lab 回測系統,將這套源於 20 世紀美股的大師法則,精準對接至現代台股市場。透過高品質的數據回測,我們將驗證這套「理性選股」策略在台灣是否依然能開創超額報酬,並展示數據驅動決策在風險控管與收益增強上的實戰價值。
為了將墨基爾「高品質、低估值」的理念落實為可執行的量化邏輯,我們設定了以下進出場條件:
選股條件:
本研究的所有數據均取自 TEJ 台灣經濟新報 資料庫,透過標準化處理確保跨年度數據的一致性。
👉 立即前往 [GitHub] 獲取 TQuant Lab 完整程式碼,掌握策略實作細節。
透過 TQuant Lab 的回測系統實證,柏頓.墨基爾的「成長與估值平衡策略」展現了優異的穩定性。回測結果顯示,本策略在長達 64 個月的測試期間中,不僅在累積報酬率上大幅勝過大盤,更展現了卓越的超額報酬能力(Alpha 值達 0.22)。 雖然台股市場波動劇烈,年化波動率約 32.97%,但透過嚴格篩選具備實際盈餘成長與低本益比的標的,該策略在獲利效率上依然維持了高水準,其夏普比率(Sharpe Ratio)達到 1.10,顯示其在承擔風險的同時,能換取相當優異的報酬對價。
表:策略績效指標摘要
| 指標項目 | 墨基爾選股策略 | 台灣加權指數 (Benchmark) |
| 年化報酬率 (Annual return) | 36.24% | 15.97 % |
| 累計報酬率(Cumulative returns) | 421.60% | 120.63% |
| 年化波動率 (Annual Volatility) | 32.97% | 18.53 % |
| 夏普比率 (Sharpe Ratio) | 1.10 | 0.893 |
| 最大回撤 (Max Drawdown) | -38.22 % | -26.74% |
| Alpha | 0.22 | -0.003 |
| Beta | 0.92 | 0.93 |
從累積報酬率曲線可以發現,策略在 2020 年後的台股多頭行情中具備極佳的進攻性,這主要歸功於選股濾網精準捕捉了「營收成長」與「稅後淨利」雙優的企業。 即使在 2022 年大盤大幅修正期間,由於低本益比的評價保護,策略績效與大盤的差距依然持續拉開,形成顯著的超額報酬。
圖 1:策略累計報酬率圖(Cumulative Returns)
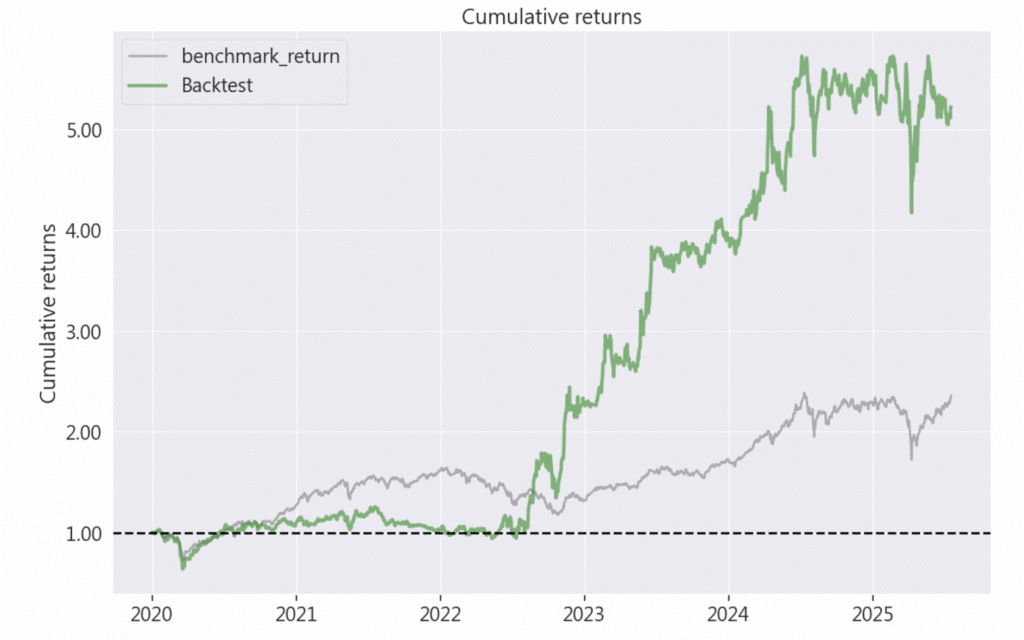
說明:圖中綠線為 Backtest 策略,灰線為 Benchmark 大盤
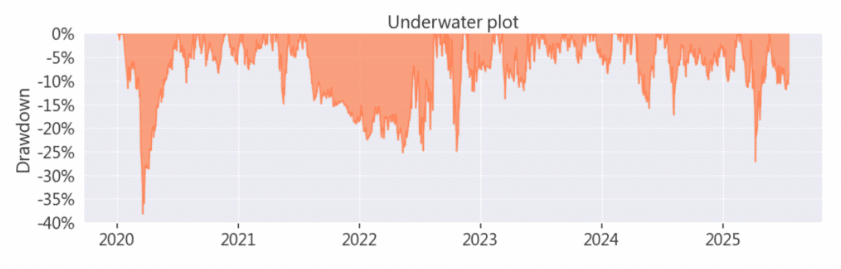
圖 2:最大回撤圖(Drawdown)
最大回撤(MDD)反映了投資過程中可能面臨的最極端帳面損失。 本策略的最大回撤(MDD)為 -38.219%,顯示即使具備穩定選股邏輯,在系統性風險發生時仍可能承受顯著波動。這也提醒量化投資者,在追求高報酬的同時,必須同步思考部位集中度與風險曝險管理。透過數據分析,投資者可理解如何利用 TEJ 資料庫中的風險因子,進一步優化進出場時機,以緩解回撤帶來的心理壓力。
經由 TEJ API 與 TQuant Lab 的數據實證,柏頓.墨基爾(Burton G. Malkiel)的選股法則在台股市場展現了顯著的有效性。本研究核心邏輯在於結合「企業盈利增長動能」與「相對估值位階」進行篩選,實證結果顯示該組合在 64 個月的測試區間內,累積報酬率達 421.60%,且 Alpha 值為 0.22,反映出該量化模型具備產生穩定超額報酬之能力。
在台股高度波動的環境中,透過「本益比排序」與「營收成長率優於產業平均」的雙重過濾,能篩選出具備長期競爭優勢的標的。此量化實證結果顯示,即便在具備「隨機漫步」特徵的市場中,藉由嚴謹的因子定義與高品質的數據庫支持,投資者仍能建構出具有統計顯著性的投資組合,並有效規避非理性市場情緒所帶來的估值偏離風險。
縱使回測數據表現優異,但從 TQuant Lab 產出的風險指標分析,本策略仍有以下可優化之面向:
動態再平衡機制(Dynamic Rebalancing): 目前採固定 120 天之調整頻率。未來可嘗試導入「事件觸發型再平衡」,針對個別標的之波動率(Volatility)或基本面劇烈變動進行即時調整,以提升資本配置之效率。
墨基爾的經典法則強調「以合理的數據,驗證長期的價值」。然而,要在台股數千檔標的中,即時計算「優於產業平均」的成長率並排序「本益比分位點」,需仰賴高效的量化工具。
量化回測最忌諱使用「未來資料」。TEJ 量化資料庫 的核心優勢在於完善的 Point-in-Time (PIT) 當時點數據架構。這代表資料庫紀錄的是數據「當時」發布的正確數值與時間點,而非事後修正後的數字。透過 PIT 數據,您能確保回測時使用的是當時市場真正能取得的資訊,徹底排除「前瞻偏差(Look-ahead Bias)」,讓回測績效具備極高的實戰參考價值。
TQuant Lab 是專為量化交易者設計的專業開發環境,整合了從數據調取、策略研發至績效評估的全流程優勢:
數據的品質與工具的效率,決定了量化模型的生命力。不論您是想複製大師經典策略,或是開發獨門的因子模型,TEJ 與 TQuant Lab 都是您在資本市場中最堅實的數據後盾。
本文內容僅供研究與學術探討之用,不構成任何投資建議。
