All roads lead to Rome

Table of Contents
TEJ offers different ways to access to TEJ database through programming languages, such as Python-based REST API and TEJ API, R-based R API or NET-based .Net API. Even though the mechanisms behind these are a bit different, the logic of getting data and the way to set input parameter share many similarities, which enable users to turn to different methods more flexibly. Therefore, this week, we are about to compare REST API to TEJ API and see what suits you the most !
Windows OS and Jupyter Notebook
#Basic modules required
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np#Modules required by REST API
import requests, json#Modules required by TEJ API
import tejapi
tejapi.ApiConfig.api_key = 'Your Key'

key = "&api_key=" + "Your Key"
database = 'TWN/APRCD'
coid = "&coid=" + "2454,3034,2379"
date_start = "&mdate.gte=" + "2000-01-01"
date_end = "&mdate.lte=" + "2020-12-31"
columns = "&opts.columns="+ "coid,mdate,open_d,high_d,low_d,close_d"
paginate = ''
key: the key to database, please change ‘Your Key’ into the key you get after purchasing the database
database: the code of database, here we choose Unadjusted Stock Price
coid: the code of the stock, we select these three (2454、3034、2379) firms. If you rather choose all firms, assign empty string to coid
coid = ''date_start: the starting date, if there’s no limitation set on it, also assign empty string
date_start = ''date_end: the ending date, if there’s no limitation set on it, also assign empty string
date_end = ''columns: selected columns, the code of columns can be viewed in the column description of that database. If you want all columns, just assign empty string
columns = ''paginate: set empty string by default, and it’ll be altered later on in loop
url = "https://api.tej.com.tw/api/datatables/" + database + ".json?" + coid + date_start + date_end + columns + key + paginate
rq = requests.get(url)
Then we attach those variables at the end of basic link to form a modified link. The .json? within the link represents the json output format. In the next step, requests.get() is used to load the contents of the website which are stored in rq. Finally, we display the content of rq with json()
rq.json()
column_info = rq.json()['datatable']['columns']
Since from the above we know the data type of rq.json() is dictionary, which also contains several dictionaries. Therefore, we choose the second layer dictionary and get the column information with its corresponding key ‘columns’

chinese_columns = [i['cname'] for i in column_info]
So we can extract Chinese columns name based on column information structure

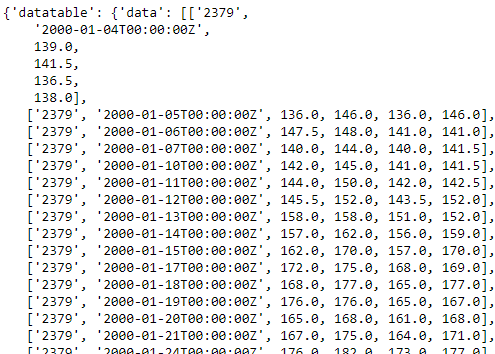
data = rq.json()['datatable']['data']
Here we choose the key ‘data’ of the second layer dictionary, which contains stock price that we need

data_table_a = pd.DataFrame(data, columns = chinese_columns)
Form a DataFrame by combining stock price data and column names
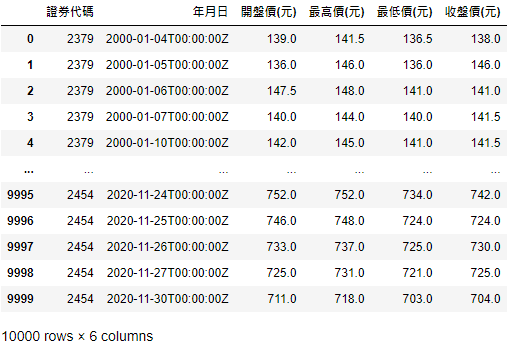
Because TEJ set the limitation on data amount of single access, which is exactly 10,000 amounts, the above result may not have all data we want
next_cursor_id = rq.json()['meta']['next_cursor_id']
print(next_cursor_id)
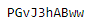
To make sure the completeness of data, we use the above way. If next_cursor_id is shown as a random code, meaning still some data is on the next page. But if it prints out None, indicating it’s the last page of data pool. What’s worth noting is that every time we call requests.get(), next_cursor_id will change accordingly, even we apply the same link
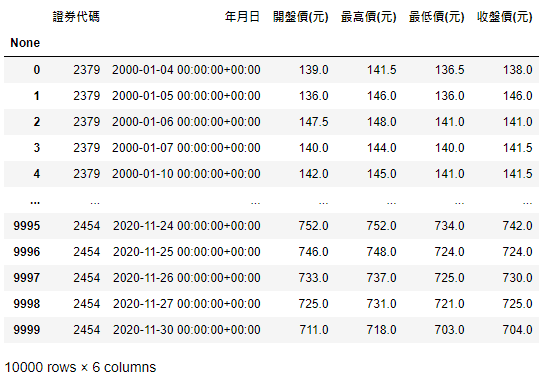
data_table_b = tejapi.get('TWN/APRCD',
coid = ['2454','3034','2379'],
mdate = {'gte':'2000-01-01', 'lte':'2020-12-31'},
opts = {'columns':['coid','mdate','open_d','high_d','low_d','close_d']},
chinese_column_name = True)
As for TEJ API, we use tejapi.get() function with several inputs. We can see the way to select data range is quite the same. But TEJ API can directly return a Dataframe with no need to combine data and column names.
stock_price_a = pd.DataFrame()while True:
#Reset url
url = "https://api.tej.com.tw/api/datatables/" + database + ".json?" + coid + date_start + date_end + columns + key + paginate
#Load website
rq = requests.get(url)
#Select Chinese column
column_info = rq.json()['datatable']['columns']
chinese_columns = [i['cname'] for i in column_info]
#Obtain data
data = rq.json()['datatable']['data']
#Form a dataframe
data_table = pd.DataFrame(data, columns = chinese_columns)
#Store in the container
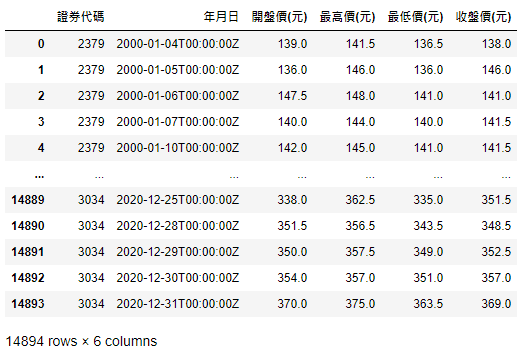
stock_price_a = stock_price_a.append(data_table).reset_index(drop=True)
#Check if there's next page
next_cursor_id = rq.json()['meta']['next_cursor_id']
#Whether or not to escape the loop
if next_cursor_id == None:
break
else:
paginate = '&opts.cursor_id=' + next_cursor_id
By continuing to use the variables built at the beginning, we firstly create an empty DataFrame stock_price_a as a container. Then enter into while loop and keep storing each page’s data in stock_price_a until next_cursor_id become None, meaning there’s no next page.
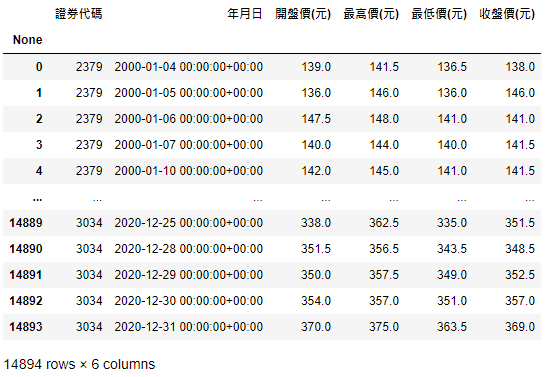
stock_price_b = tejapi.get('TWN/APRCD',
coid = ['2454','3034','2379'],
mdate = {'gte':'2000-01-01', 'lte':'2020-12-31'},
opts = {'columns':['coid','mdate','open_d','high_d','low_d','close_d']},
paginate = True,
chinese_column_name = True)
With regards to TEJ API, we just need to add paginate = True to guarantee the completeness of data
key = "&api_key=" + "Your Key"
database = 'TWN/AIM1A'
coid = "&coid=" + "2454,3034,2379"
date_start = "&mdate.gte=" + "2000-01-01"
date_end = "&mdate.lte=" + "2020-12-31"
columns = "&opts.columns=" + "coid,mdate,R531,7210,R106,R504"
pivot = "&opts.pivot=True"
paginate = ''
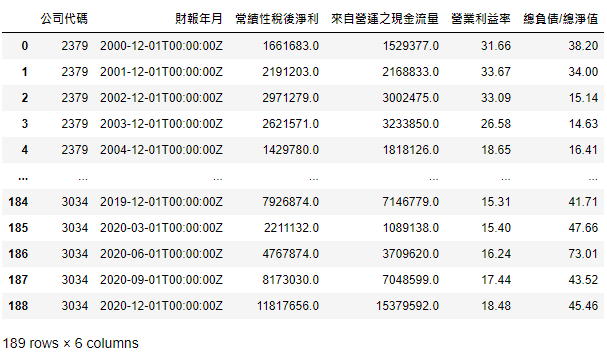
Here we choose Consolidated financial statements (cumulative) database. The firms selected and time periods are the same as Case1 and Case2. It’s worth noting that the codes of financial accounts should be looked up in advance to become the column information here, and we also add pivot variable to make Dataframe easier to deal with (To see more details, please refer to 【Introduction(6)】- Obtain Financial Data) . The following data obtaining structure are much similar to Case2
finance_a = pd.DataFrame()
while True:
#Reset url
url = "https://api.tej.com.tw/api/datatables/" + database + ".json?" + coid + date_start + date_end + columns + key + pivot + paginate
#Load the website
rq = requests.get(url)
#Chinese column
column_info = rq.json()['datatable']['columns']
chinese_columns = [i['cname'] for i in column_info]
#Financial data
data = rq.json()['datatable']['data']
#Form a dataframe
data_table = pd.DataFrame(data, columns = chinese_columns)
#Store in finance_a
finance_a = finance_a.append(data_table).reset_index(drop=True)
#Check if there's next page
next_cursor_id = rq.json()['meta']['next_cursor_id'] #Condition to escape the loop
if next_cursor_id == None:
break
else:
paginate = '&opts.cursor_id=' + next_cursor_id
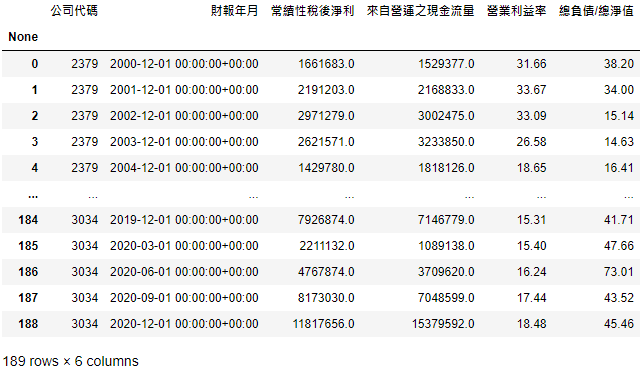
finance_b = tejapi.get('TWN/AIM1A',
coid = ['2454','3034','2379'],
mdate = {'gte':'2000-01-01', 'lte':'2020-12-31'},
opts = {'columns':['coid','mdate','R531','7210','R106','R504'],'pivot':True},
paginate = True,
chinese_column_name = True)
With these three examples, we figure out no matter which method we choose, the procedures are all standard and easy to understand. Thus, we recommend readers to set up a function to avoid these repetitive works. To sum up, REST API provides web-crawl mechanism to access to database and its output format is json or xml, which both has its pros and cons, while TEJ API use module built by TEJ and has advantages of quick and efficient access to database. However, this article doesn’t intend to decide which one is better, but aims to deepen readers’ understanding of access to database. If readers are interested in certain databases, welcome to E-shop to choose the optimal plan for yourself !
