
Table of Contents
吉姆.史萊特(Jim Slater)是英國知名的成長型投資大師,曾替週日電訊報 (Sunday Telegraph) 撰寫投資組合推薦專欄,於 1963至1965年間獲取約 68.9 % 報酬率,與此同時,英國股市僅上漲 3.6%,吉姆.史萊特因此聲名大噪。其最著名的莫過於以「祖魯原則」為依據的投資方法,主張在投資市場向必須學習祖魯族一樣,集中火力在自己選定的利基專門領域,這樣才能發揮優勢。吉姆.史萊特則特別注重中小型公司長期獲利的成長及相對強度,並以本益比/成長率比值(PEG)等作為評價的重要標準,如以下所示 :
本文使用 Windows OS 並以 Jupyter Notebook 作為編輯器
import pandas as pd import numpy as np import tejapi import matplotlib.pyplot as plt tejapi.ApiConfig.api_key = "Your Key" tejapi.ApiConfig.ignoretz = True
由於吉姆.史萊特的選股條件,部分包含一些主觀判斷的因素,在參考目前台灣市場環境後,整合出以下客觀、可量化的指標作為篩選條件
條件一: 公司總市值 < 市場平均總市值
條件二: 過去五年稅後淨利皆為正
條件三: 過去三年稅後淨利成長率皆 >= 15%
條件四: 預估稅後淨利成長率 >= 15%
條件五: 近五年平均營運現金流量 > 近五年平均稅後淨利
條件六: 近年營運現金流量 > 近年稅後淨利
條件七: 近年營業利益率 >= 10%
條件八: 近年可運用資本報酬率 >= 10%
條件九: 最近一季負債/淨值比 < 50%
條件十: 最近董監事持股比例 >= 20% 或是 最新一期董監事持股比例增加
條件十一: 預估本益比 <= 20
條件十二: 預估本益比/預估稅後盈餘成長率比值 <= 1.2
條件十三: 超額報酬(月) > 0
選股條件: 至少符合 9項以上基本面條件,而交易面條件皆須滿足
投組持有期間: 為了避免前視偏誤,參考證券分析之開山始祖一班傑明.葛拉漢的投資心法的做法,以Q4財報公佈日(統一設隔年3/31)開始持有一年。例如2004年完整財務數據,將於2005/03/31公佈,故當期投組持有期間為 2005/03/31 ~ 2006/03/31
投組報酬率: 投組完整持有一年的報酬率,並考慮交易成本
security = tejapi.get('TWN/ANPRCSTD',
paginate = True,
chinese_column_name = True)
stock_list = security[(security['上市別'] == 'TSE') & (security['證券種類名稱'] == '普通股')]['證券碼'].tolist()

data = pd.DataFrame() #存放迴圈結果 for coid in stock_list: #撈取2000年起的財務資料 finance = tejapi.get('TWN/AIM1A', coid = coid, mdate = {'gte':'2000-01-01'}, opts = {'pivot':True, 'columns':['coid','mdate','MV','R531','R405','7210','R106','2402','0010','1100','R504']}, paginate = True, chinese_column_name = True) #篩選出12月份資料,即年資料 finance = finance[finance['財報年月'].dt.month == 12].reset_index(drop=True) #新增配對年欄位,以利後續合併 finance['配對年'] = finance['財報年月'].dt.year #新欄位: 預估稅後淨利成長率 (用5年簡單平均去估) finance['預估稅後淨利成長率'] = finance['稅後淨利成長率'].rolling(5).mean() #新欄位: 近五年平均營運現金流量 finance['近五年平均營運現金流量'] = finance['來自營運之現金流量'].rolling(5).mean() #新欄位: 近五年平均稅後淨利 finance['近五年平均稅後淨利'] = finance['常續性稅後淨利'].rolling(5).mean() #條件二: 過去五年稅後淨利皆為正 finance['淨利大於零'] = np.where(finance['常續性稅後淨利'] > 0, 1, 0) finance['條件2'] = np.where(finance['淨利大於零'].rolling(5).sum() == 5, 1, 0) #條件三: 過去三年稅後淨利成長率皆 >= 15% finance['淨利成長大於15'] = np.where(finance['稅後淨利成長率'] >= 15, 1, 0) finance['條件3'] = np.where(finance['淨利成長大於15'].rolling(3).sum() == 3, 1, 0) #條件四: 預估稅後淨利成長率 >= 15% finance['條件4'] = np.where(finance['預估稅後淨利成長率'] >= 15, 1, 0) #條件五: 近五年平均營運現金流量 > 近五年平均稅後淨利 finance['條件5'] = np.where(finance['近五年平均營運現金流量'] > finance['近五年平均稅後淨利'], 1, 0) #條件六: 近年營運現金流量 > 近年稅後淨利 finance['條件6'] = np.where(finance['來自營運之現金流量'] > finance['常續性稅後淨利'], 1, 0) #條件七: 近年營業利益率 >= 10% finance['條件7'] = np.where(finance['營業利益率'] >= 10, 1, 0) #條件八: 近年可運用資本報酬率 >= 10% finance['可運用資本報酬率'] = (finance['稅前息前淨利']/(finance['資產總額']-finance['流動負債']))*100 finance['條件8'] = np.where(finance['可運用資本報酬率'] >= 10, 1, 0) #條件九: 最近一季負債/淨值比 < 50% finance['條件9'] = np.where(finance['總負債/總淨值'] < 50, 1, 0) #刪除NaN值 finance = finance.dropna().reset_index(drop=True) #撈取籌碼面資料 chip = tejapi.get('TWN/ABSTN1', coid = coid, mdate = {'gte':'2000-01-01'}, opts = {'columns':['coid','mdate','fld005']}, paginate = True, chinese_column_name = True) #新欄位: 最新一期董監事持股比例是否增加 chip['最新月持股增加'] = np.where(chip['董監持股%'] > chip['董監持股%'].shift(1),1,0) #年化, 篩選出每年2月份資料。因為投組建立時(3/31),最新一期的資料為2月份 chip = chip[(chip['年月日'].dt.month == 2)].reset_index(drop=True) #條件十: 最新董監事持股比例 >= 20% or 最新一期董監事持股比例增加 chip['條件10'] = np.where((chip['董監持股%'] >= 20) | (chip['最新月持股增加'] == 1),1,0) #新增年欄位,因為財報年的隔年才建構投組,所以籌碼數據配對的是去年的財務數據 chip['配對年'] = chip['年月日'].dt.year - 1 #以公司代碼、財報年月合併形成一個暫時的dataframe temp = finance.merge(chip, on = ['公司代碼','配對年']) #將此暫時的表存到迴圈外的data data = data.append(temp).reset_index(drop = True)
每次迴圈為一檔股票的處理,由於資料量龐大,運行的時間約 40分。處理的流程大致為將資料調整成相同頻率 (年化)、利用 np.where() 建立條件滿足欄位,最後在合併源自於不同資料庫的資料,並將結果儲存在 data。另外在篩選、疊加、排序或刪除資料時,索引會因此被打亂,所以習慣加上 reset_index(drop=True)。以下為 data 最終結果
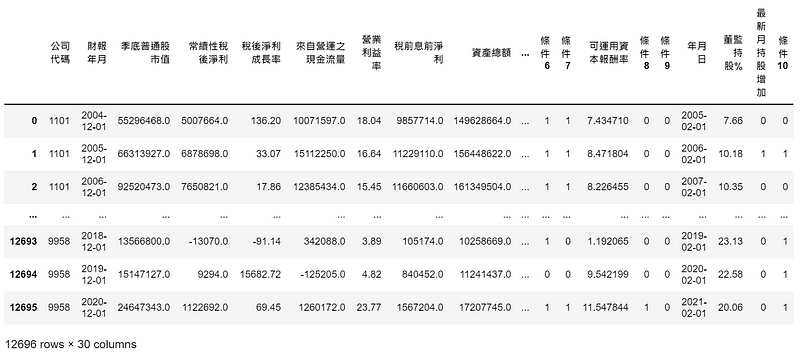
data_cp = data.copy()
為了避免修改到原資料而需重新撈取,以備份檔進行操作。
#計算市場平均總市值 avg_mv = data_cp.groupby(by = '財報年月')['季底普通股市值'].mean()
#將計算出市場平均總市值,以財報年月配對到原資料,形成新的一欄 data_cp['市場平均總市值'] = data_cp['財報年月'].map(avg_mv)
#條件一: 公司總市值 < 市場平均總市值 data_cp['條件1'] = np.where(data_cp['季底普通股市值'] < data_cp['市場平均總市值'], 1, 0)
擁有所有公司市值資訊後,即可建立條件一。這邊使用 map() 將索引為財報年月的 avg_mv 與 data_cp的財報年月欄配對,並將值投射到新欄位
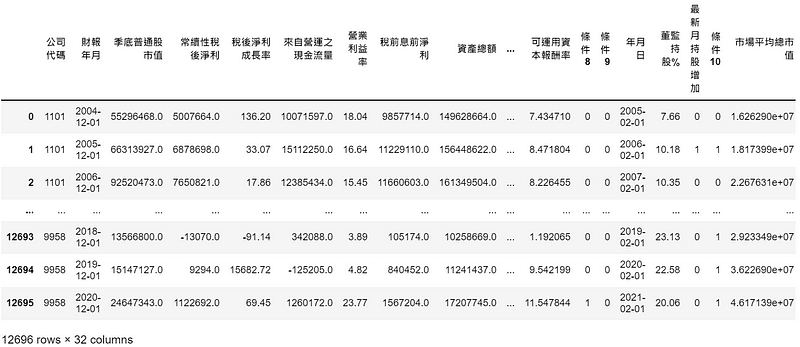
#整理出之後需要的欄位 data_cp = data_cp[['公司代碼','財報年月','季底普通股市值','預估稅後淨利成長率','條件1','條件2','條件3','條件4','條件5','條件6','條件7','條件8','條件9','條件10']] data_cp['分數'] = data_cp['條件1'] + data_cp['條件2'] + data_cp['條件3'] + data_cp['條件4'] + data_cp['條件5'] + data_cp['條件6'] + data_cp['條件7'] + data_cp['條件8'] + data_cp['條件9'] + data_cp['條件10']
#取大於9分的股票 data_cp = data_cp[data_cp['分數'] >= 9].sort_values(by = '財報年月').reset_index(drop=True)
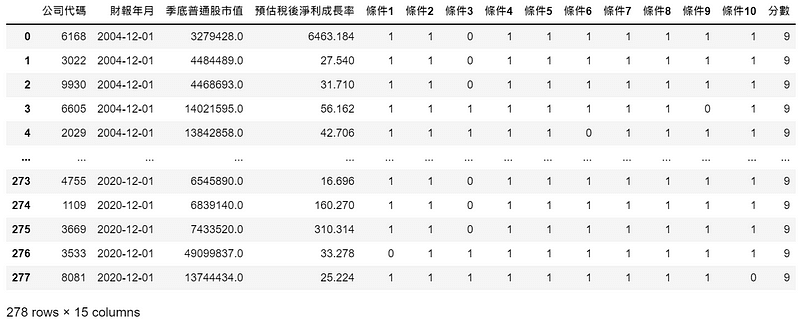
Panel = pd.DataFrame() #儲存每檔股票的完整資訊 Return = pd.DataFrame() #儲存投組報酬率 #儲存日期,並轉成DatatimeIndex序列。為了使用 .year提取年份功能 date_list = pd.DatetimeIndex(data_cp['財報年月'].unique()) for date in date_list: #每一年產生一張dataframe table = data_cp[data_cp['財報年月'].dt.year == date.year].reset_index(drop=True) #取得建構投組時,成分股的前一整年本益比 stocks = table['公司代碼'].tolist() pe_ratio = tejapi.get('TWN/APRCD1', coid = stocks, opts = {'columns':['coid','mdate','per_tse']}, mdate = {'gte': date + pd.Timedelta(days = 120 - 365) , 'lte': date + pd.Timedelta(days = 120)}, paginate = True, chinese_column_name = True) #計算過去一年平均本益比,當作預估本益比 pe_estimate = pe_ratio.groupby(by = '證券代碼').mean().reset_index() #取得股價相對強度,以超額報酬(月)衡量 relative_performance = tejapi.get('TWN/APRCD2', coid = stocks, opts = {'columns':['coid','mdate','rois_m']}, mdate = {'gte': date + pd.Timedelta(days = 120 - 5), 'lte': date + pd.Timedelta(days = 120)}, #只需要最靠近投組建構日的最後一筆資料,以5日區間確保涵蓋到至少一日交易日 paginate = True, chinese_column_name = True) #取得每檔股票,最後一筆超額報酬資料 relative = relative_performance.groupby(by = '證券代碼').last().reset_index() #合併交易面資料 merge = pe_estimate.merge(relative, on = '證券代碼') #改欄位名,以利與table合併與辨識 merge = merge.rename(columns = {'證券代碼':'公司代碼', '本益比-TSE':'預估本益比'}) merge = table.merge(merge[['公司代碼', '預估本益比','超額報酬(月)-大盤']], on = '公司代碼') #新欄位: 預估本益比與成長率比值 (PEG) merge['預估本益比與成長率比值'] = merge['預估本益比']/merge['預估稅後淨利成長率'] #交易面條件十一、十二、十三篩選,得到最終投組的成分 final = merge[(merge['預估本益比'] <= 20)&(merge['預估本益比與成長率比值'] <= 1.2) & (merge['超額報酬(月)-大盤'] > 0)].reset_index(drop=True) #新欄位: 計算成分股於投組內的市值權重,用於之後計算市值加權投組報酬 final['權重'] = final['季底普通股市值']/ final['季底普通股市值'].sum() #撈取該年成分股、市場的年報酬 stocks = final['公司代碼'].tolist() ret = tejapi.get('TWN/APRCD2', coid = stocks + ['Y9997'], paginate = True, opts = {'columns':['coid','mdate','roi_y']}, mdate = {'gte': date + pd.Timedelta(days = 120), 'lte': date + pd.Timedelta(days = 120+365)}, chinese_column_name = True) #期間報酬率: 取得這段期間的最後一筆,即為持有成分股這一年的報酬率 period_ret = ret.groupby(by = '證券代碼')['年報酬率 %'].last().reset_index() #新欄位: 財報年月,值皆為日期,為了後續合併 period_ret['財報年月'] = date #改變欄名以利合併 period_ret = period_ret.rename(columns = {'證券代碼':'公司代碼'}) #將final表與期間報酬合併, outer代表保留市場資料(否則欄位有nan值會排除) temp = final.merge(period_ret,on = ['公司代碼','財報年月'], how = 'outer') #儲存每年的完整資料 Panel = Panel.append(temp).reset_index(drop=True) #投組報酬: 2005年(2004財報年)始持有投組,2020財報年不計算(因尚未持有一年) if 2020 > date.year >= 2004: #交易成本 fee = 0.1425*2 + 0.3 #投組平均加權報酬率(排除最後一筆市場報酬) eq_port = temp.loc[:,'年報酬率 %'].values[:-1].mean() - fee #投組市值加權報酬率(去掉na 是為了排除市場報酬) val_port = (temp['權重']*temp['年報酬率 %']).dropna().sum() - fee #市場報酬(最後一筆資料) mkt = temp['年報酬率 %'].values[-1] #儲存報酬率 Return = Return.append(pd.DataFrame(np.array([date,eq_port,val_port,mkt]).resha
這邊以年份進行迴圈,並於迴圈內進行交易面條件篩選、投組報酬率的計算。其中撈取本益比的資料期間為建構投組的前一整年,例如當財報日期為 2020–12–01時,將於2021–03–31 (120日後)建構投組,因此考慮建構前一整年 (2020–03–31 ~ 2021–03–31)的本益比;而此投組會持有至約 2022–03–31,以成分股該日的年報酬率作為投組報酬的計算。但因尚未持滿一年,故計算投組報酬時會排除以 2020年財務數據為篩選依據的投組
Panel
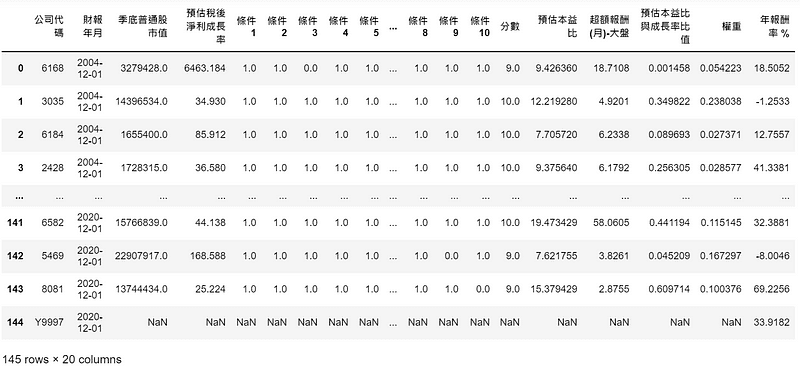
Return
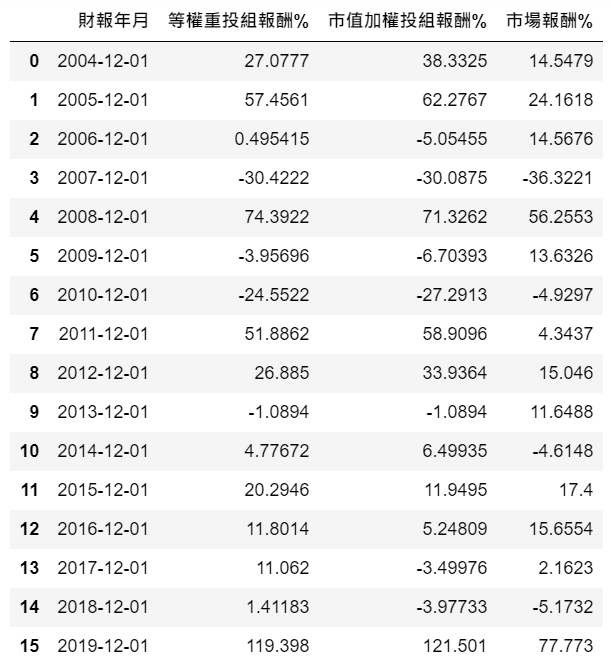
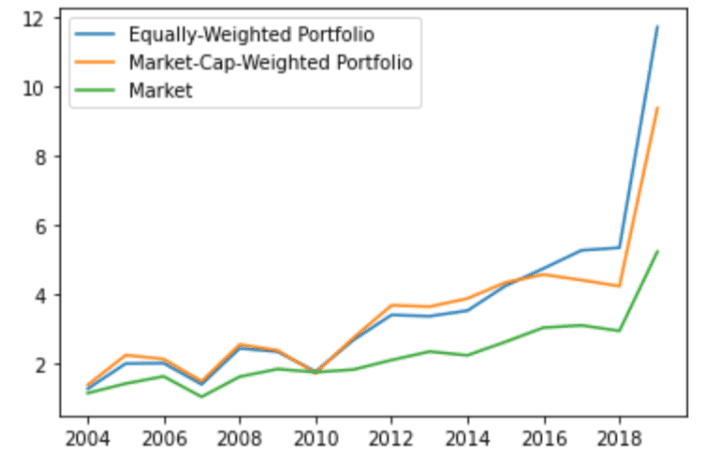
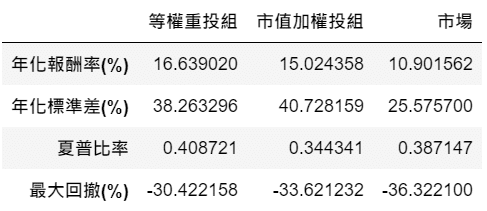
由於本篇撈取的資料量較大,涵蓋了上市公司多年度的財務、籌碼與交易面數據,所以建議可先由少數公司、較短期間測試,或是自行調整量化指標的標準,若短期績效不錯,可再拉長時間區間進行回測檢驗。除了資料時間長度,資料的品質與多樣化程度更是不能忽略,因此推薦讀者於TEJ EShop選購各類型的資料庫,嘗試以量化方式實踐不同投資大師的投資哲學吧!
本文僅供參考之用,因以目前上市公司為主,故或有倖存者偏差疑慮、部分計算也較為簡略。因此本文不構成要約、招攬或邀請、誘使、任何不論種類或形式之申述或訂立任何建議及推薦,讀者務請運用個人獨立思考能力,自行作出投資決定,如因相關建議招致損失,概與作者無涉。
