
Table of Contents
透過前兩篇文章想必大家應該都已經知道要如何透過TEJ API來抓取資料,然後再儲存到適合的格式,最後再定期更新了吧!那本篇文章就是在跟大家說明,如何透過python當中最重要的兩個資料工具包Numpy及Pandas對抓下來的資料進行第一步地處理&分析~
Numpy的設計主要是為了方便且高效的來處理n維且大量數據的陣列,並搭配內建函數給予使用者對資料進行初步快速地處裡。
import numpy as np
a = np.array([0, 0.5, 1.0, 1.5, 2.0]) #float ndarray -1-1. b = np.array(['a', 'b', 'c']) #string ndarray -1-2. c = np.arange(0, 10, 2) #array([0, 2, 4, 6, 8]) -2. c[2:] #array([4, 6, 8]) -3. c[:2] #array([0, 2]) -4.
上面的例子分別代表的是:
a = np.arange(0, 30, 2) #array([0, 2, 4, ..., 28])
a.sum() #210 -1-1. a.mean() #14.0 -1-2. a.std() #8.640987 -1-3. a.cumsum() #array([0, 2, 6, 12, ...,210]) -1-4.
lst = [0, 2, 4] lst*2 = [0, 2, 4, 0, 2, 4] -2-1 a+a #array([0, 4, 8, ..., 56]) -2-2. a*a #array([0, 4, 16, ..., 784]) -2-3.
上面的例子分別代表的是:
其中第一個用法即是透過numpy內建的大量方法直接計算。
而在第二個例子裏面就可以看到numpy的向量化數學運算,因為如果是在一般的list下(2–1),可以看到把list乘2的話會把list當中的元素量變成原來的兩倍而不是數值變兩倍,但如果是numpy(2–2, 2–3)則是可以把陣列裡面的元素相對應位置進行數學運算~
b = np.array([a, a*2]) #array([0, 2, 4, ..., 28],
[0, 4, 8, ..., 56])
b[0] #array([0, 2, 4, ..., 28]) -1-1. b[0][1] #2 -1-2. b.sum(axis = 1) #array([210, 420]) -1-3.
b.shape #(2, 15) -2-1.
b.reshape(5,6) #array([0, 2, 4, 6, 8, 10], -2-2.
...
[36, 40, ..., 56]])
上面的例子分別代表的是:
接下來看到的是numpy在多維陣列的表現,在選擇上一樣是透過”[]”進行,不同的地方是因為能選的東西變多了,所以可以透過兩個”[][]”分別代表先選哪一列,再選甚麼位置。
那如果是要做一些矩陣運算的時候,就可以透過shape找到現在陣列的形狀再用reshape改成想要的形狀後就可以做運算~
#boolean
b > 15 #array([False, False, ..., True], -1-1.
[False, False, ..., True])
np.where(b>15, 1, 0) #array([0, 0, ..., 1], -1-2.
[0, 0, ..., 1])
#random variable np.random.normal(5, 2, 10) -2-1. np.random.standard_normal(5) -2-2.
#financial pip install numpy_financial import numpy_financial as npf
npf.fv(0.03, 5, 0, -1000) #1159.27 -3-1. #fv(rate, nper, pmt, pv) npf.irr([-95, 3, 3, 3, 103]) #0.0439 -3-2. #irr(values)
上面的例子分別代表的是:
其實numpy還有許許多多針對陣列當中數據處裡的應用,小編很難只透過一篇文章就全數道盡 ,剩下的大家有興趣可以透過Numpy官方網站或是在下方告訴我們囉!
Pandas是一種專門分析表格資料的工具包,就如同Excel一樣,他是以一種叫做DataFrame類別的方式將資料以表格的方式呈現,以協助使用者更為方便的分析資料,尤其是以時間序列為主的金融資料。
import pandas as pd
df = pd.DataFrame([1, 2, 3, 4],
columns = ['Numbers'],
index = ['index_a','index_b','index_c','index_d'])

從上面可以看到我們透過上述程式碼產出一個,欄位名稱為Numbers,列名稱分別為index_a,b,c,d的表格。
df.loc['index_a'] #Numbers 1 -1-1.
df.iloc[0:2] #參考完整程式碼 -1-2.
df * 2 #same as numpy -1-3.
#新增"Name"欄位
df['Name'] = ['Amy', 'Bob', 'Catherine', 'Duke'] -2-1.
#選取整個欄
df['Numbers'] -2-2.
#刪除欄位
df.drop('欄位名 ', axis=1) -2-3.
#Math df['Numbers'].sum() #10 -3-1. df['Numbers'].mean() #2.5 -3-2. df['Numbers'].std() #1.291 -3-3.
上面的例子分別代表的是:
Pandas的基礎應用當中,其實大多數跟我們之前如同我們之前提過的numpy陣列,在選擇上一樣透過中括號對[“欄位名稱”]進行新增/選擇,但如果是要刪除的話,則要透過drop()的方式對已有欄位進行刪去。在運算上,Pandas DataFrame 一樣可以直接對欄位裡面的數值進行基本的統計值運算~
import tejapi tejapi.ApiConfig.api_key = “你的api_key”
df = tejapi.get('TWN/EWPRCD',
coid = ['2330'],
mdate={'gte':'2020-01-01', 'lte':'2020-12-31'},
opts={'columns': ['mdate','open_d','high_d','low_d','close_d']},
paginate=True
)
#Math df.describe() np.mean(df) np.log(df)
#作圖 df['close_d'].plot()
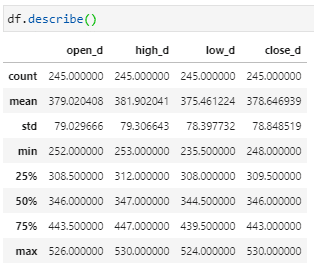
在pandas資料基本分析裡面,我們採用的例子一樣是透過TEJ API得到的2330股價日資料,然後就可以直接透過describe()的方式得到大部分可能會需要用到的敘述統計值(如上圖 ),而如果想要對這些數值進行運算,就可以透過我們之前提到的numpy工具直接對整個表格進行運算噢!
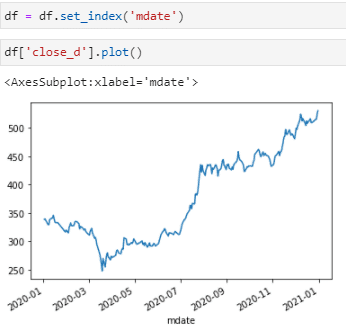
最後就是基本作圖,在Python的作圖方法裡面也是有數種操作方式,而Pandas則是提供了小編覺得其中最為簡便的一種。如果想要呈現的圖表並不複雜的話(如股價走勢、股價報酬率變化等),可以直接透過選取該欄位資料然後加上.plot(),就可以直接看到結果啦(如上圖 )
而在這邊唯一要注意的是,圖表中的X與Y軸分別代表的是Index以及欄位資料,所以才會對原先抓下來的資料先做一個set_index()的動作噢!
這次分享給大家的是如何使用Python當中的Numpy還有Pandas工具包對資料進行初步整理/分析,但這兩個工具裡面的功能其實包山包海,短短一篇文章實在是難以詳述,所以~如果有興趣或者疑問可以上他們的網站亦或是在下方留言告我們 ❗️❗️那麼在這篇文章之後,我們就會進入透過這兩個工具包對金融資料進行分析應用啦,請大家好好期待 ❗️❗️
最後,如果喜歡本篇文章的內容請幫我們點擊下方圖示 ,給予我們更多支持與鼓勵,有任何的問題都歡迎在下方留言/來信,我們會盡快回覆大家
有任何使用上的問題都歡迎與我們聯繫:聯絡資訊
