Table of Contents
Lasso模型的全稱為最小絕對值收斂和選擇算式,主要運用在迴歸分析中的解釋變數篩選並通過「懲罰項目」的參數設定調整複雜度,因此,透過Lasso模型便可以降低「過度擬合」的問題,並且提升解釋變數的有效性。
Lasso模型的懲罰項用於衡量「誤差項」與「解釋變數量」之間孰輕孰重,也就是在挑選模型參數的過程中便不會只參考誤差項最小化,還會綜合考量解釋變數的數量不要太多,讓模型有適當的複雜度。
懲罰項參數設定則會影響到模型會考慮哪一個面相較多,若參數小,則該模型較注重「減少誤差」;反之,參數大,則模型較注重「減少解釋變數的量」,所以這就需要執行人員選定一個區間的數值不斷進行測試。
Note:懲罰項參數的設定需大於 0,才會符合想要考慮越少參數越好的這項條件;此外,Python套件中懲罰項參數設定為Alpha欄位。
本文使用 MacOS 並以 Jupyter Notebook作為編輯器
# 基本功能 import numpy as np import pandas as pd
# 繪圖 import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.set()
# TEJ API import tejapi tejapi.ApiConfig.api_key = 'Your Key' tejapi.ApiConfig.ignoretz = True
總體經濟說明表:針對總體經濟表的科目所使用的說明表,資料代碼為(GLOBAL/ABMAR)。
總體經濟表:政府部門發布的總體經濟指標,來源包含IMF與OECD,以及相關專業刊物。資料代碼為(GLOBAL/ANMAR)。
factor = tejapi.get('GLOBAL/ABMAR',
opts={'columns': ['coid','mdate', 'cname', 'freq']},
chinese_column_name=True,
paginate=True)
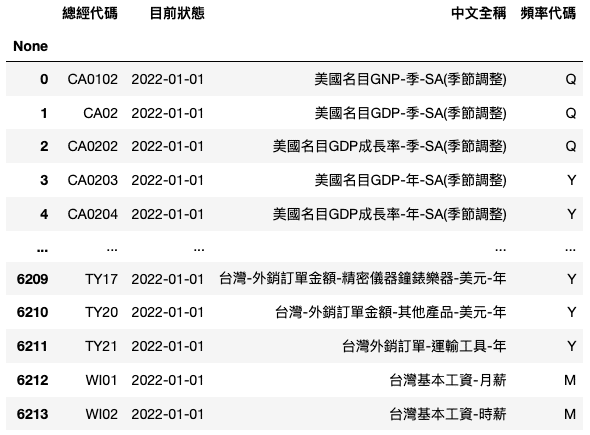
# 挑選資料 list1 = list(factor['總經代碼'][i] for i in range(0,6214) if '台灣' in factor.iloc[i,2] and factor['頻率代碼'][i] == 'Q')
# 整理表格 factor = factor[factor['總經代碼'].isin(list1)].reset_index().drop(columns =['None', '目前狀態', '頻率代碼'])
因為總經指標種類繁多,不可能將所有的數據都考慮進模型當中,所以本文僅會考慮「台灣的資料」;此外,因為經濟成長率的統計週期為每季,因此也僅會考量「季資料」。

data = tejapi.get('GLOBAL/ANMAR',
mdate={'gte': '2008-01-01', 'lte':'2021-12-31'},
opts={'columns': ['coid','mdate', 'val', 'pfr']},
coid = list1, # 符合條件的指標
chinese_column_name=True,
paginate=True)
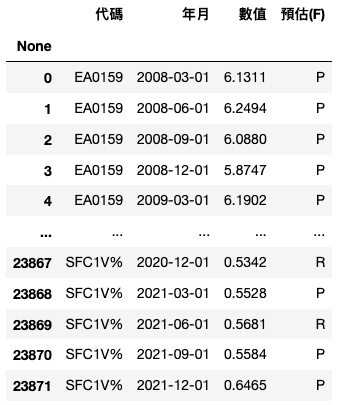
data = data[data['預估(F)'] != 'F']
本文在數據方面的考量會將預估值排除。
data = data.set_index('年月')
df = {}
for i in list1:
p = data[data['代碼'] == i]
p = p['數值']
df.setdefault(i, p)
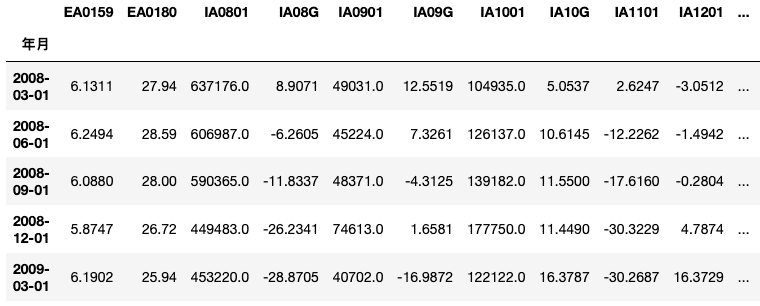
df = pd.concat(df, axis = 1)
先設定「年月」為index,再透過迴圈列出各別指標的數據,最後將其並列排序。
# 列出所有經濟成長率指標 growth_reference = list(factor['總經代碼'][i] for i in range(0,427) if '經濟成長率' in factor.iloc[i,1])
factor[factor['總經代碼'].isin(growth_reference)]
# 選定'NE0904-季節調整後年化經濟成長率'作為經濟成長率指標 growth = df['NE0904']
本文考量到台灣是出口貿易導向的國家,經濟容易受到全球消費循環影響,所以選擇「NE0904-季節調整後年化經濟成長率(saar)」為本文的經濟成長率依據。
# 移除各項經濟成長率指標 df = df.drop(columns = growth_reference)
# 移除具有缺失值的指標 df = df.dropna(axis = 1, how = 'any')
from statsmodels.tsa.stattools import adfuller
for i in df.columns.values:
p_value = adfuller(df[i])[1]
if p_value > 0.05:
df = df.drop(columns = i)
df = df.dropna(axis = 1, how = 'any')
print('解釋變數量:', len(df.columns))
print('經濟成長率定態檢定P值:', '{:.5f}'.format(adfuller(growth)[1]))
透過迴圈對各解釋變數進行定檢定,並且設定若為非定態的數據便直接踢除,不再進行差分或變動率的計算;另外,在末端也統計解釋變數的總量,總共有148個;最後,進行經濟成長率的檢定,檢定結果P值為0.0000,因此符合定態的條件。
from sklearn.linear_model import Lasso from sklearn.pipeline import Pipeline from sklearn.preprocessing import PolynomialFeatures
df_train = df.head(45) df_valid = df.tail(10)
growth_train = growth.head(45) growth_valid = growth.tail(10)
內文僅呈現大懲罰項(Alpha)的模型程式碼,中、小Alpha的內容與其皆相同,而考量到篇幅,此處不呈現該過程。(詳見完整程式碼)
# 大alpha模型
Lasso_l = Pipeline(steps = [('poly', PolynomialFeatures(degree = 1)), ('Lasso', Lasso(alpha = 1000))])
large = Lasso_l.fit(df_train, growth_train)
growth_pred_l = large.predict(df_valid)
large_alpha = list(growth_pred_l)
print('大Alpha的MSE:', metrics.mean_squared_error(growth_valid, large_alpha))
考量到解釋變數量總共有148個,本次模型變僅考慮各變數本身的影響力,並不考慮交互作用,所以degree的部分設定為1;此外,在設定懲罰項時,以Alpha=10, 100, 1000為三個級距,儘量讓模型在挑選變數上更為嚴格。
最後列印出各模型的MSE,如下:
大Alpha的MSE: 207.82
中Alpha的MSE: 526.29
小Alpha的MSE: 1399.59
由上列比較可以認知到,懲罰項目較大的模型表現較好,以下將透過圖表查看,並選擇最終運用的模型。
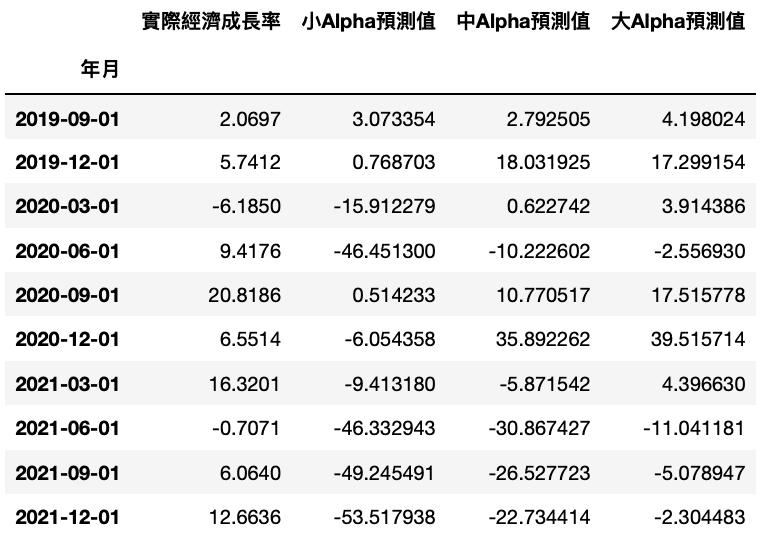
pred_data = {'小Alpha預測值': small_alpha, '中Alpha預測值': medium_alpha, '大Alpha預測值':large_alpha}
result = pd.DataFrame(pred_data, index = growth_valid.index)
final = pd.concat([growth_valid, result], axis = 1)
final = final.rename(columns={'NE0904':'實際經濟成長率'})
# 讓python套件運用中文文字 plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.figure(figsize=(15,8))
plt.plot(final['實際經濟成長率']) plt.plot(final['小Alpha預測值']) plt.plot(final['中Alpha預測值']) plt.plot(final['大Alpha預測值'])
plt.legend(('實際成長率', '小Alpha預測', '中Alpha預測', '大Alpha預測'), fontsize=16)
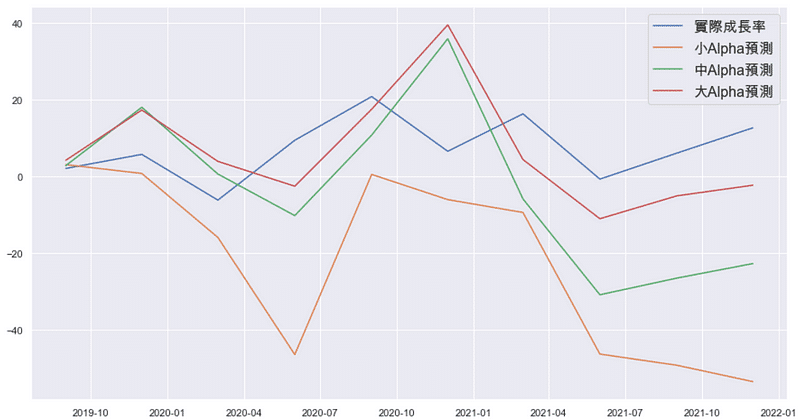
透過圖表可以清楚比較,大、中、小三個懲罰項參數級距的模型,的確是大Alpha的模型預測結果最貼近實際情形,因此本文後續便以該模型尋找有效經濟成長解釋變數。
# 重新擬合一次模型 lasso = Lasso(alpha = 1000) mdl = lasso.fit(df_train,growth_train)
# 列出係數大於0的變數 lasso_coefs = pd.Series(dict(zip(list(df_valid), mdl.coef_))) coefs = pd.DataFrame(dict(Coefficient=lasso_coefs)) coid = coefs[coefs['Coefficient'] > 0].index
# 回傳變數代號尋找中文名稱 factor[factor['總經代碼'].isin(coid)]
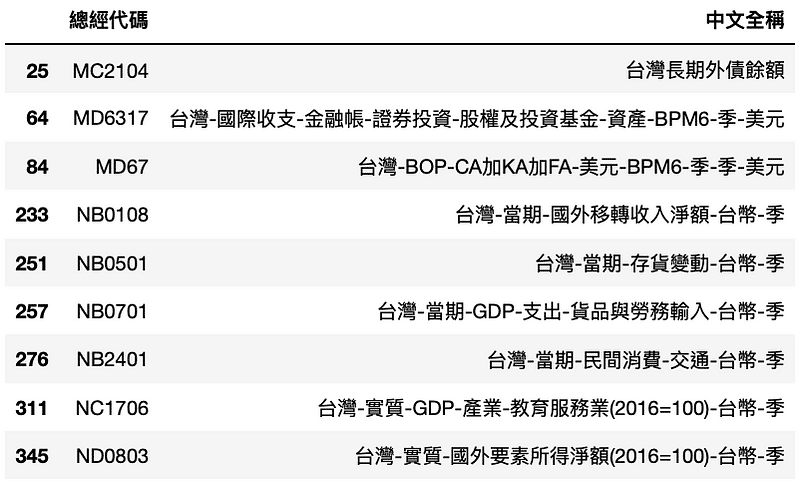
從上表可以看出,主要的有效變數由貿易、國際金融等相關數據組成,符合台灣作為出口貿易導向國家的情形;此外,從教育服務業的GDP這個項目,也可以了解人口教育素質的提升,對經濟成長亦有所驅動,因此培育下代人才也是台灣需要持續關注的議題。
藉由上述的過程,本文首先示範資料的篩選以及前處理;接著進行模型的擬合與比較;最終找出影響經濟成長的有效變數。當然,在資料處理的階段,本文為求篇幅儘量簡短,沒有進行更多的資料轉換或差分等程序,這是讀者可以自行選擇處理的,並不一定要依照本文的處理方式;此外,在模型的參數設定中,我們也鼓勵讀者後續用不同的組合試做,實際體驗一遍這樣的過程,相信會更有收穫。最後,若讀者對於模型建置有興趣,又苦於沒有齊全的資料,歡迎選購 TEJ E Shop中的方案,相信讀者具有完整的資料庫後,就能輕易完成自己的模型建置。
