
Table of Contents
盈餘是投資人在意的關鍵指標之一,盈餘高低及未來走向會影響投資人持股意願,若投資人預期公司盈餘增加,會提高持股意願。而盈餘可分為現金部分與應計項目部分,應計項目又可分為裁決性與非裁決性,公司管理層操控縱的,即為裁決性應計項目部分。根據過去研究,公司管理層有誘因透過會計原則、損益之自由裁量權等手段,來達到其擬定的盈餘目標。
在投資人與公司管理層存在資訊不對稱的情況下,公司管理層採用裁決性應計項目作為盈餘管理的手段,投資人可能因此錯估公司的真實盈餘,而高估公司未來股價。故本文透過衡量每年公司盈餘管理程度,可以讓我們避免持有在同產業中有較高盈餘管理程度的公司。
本文使用 Windows OS 並以 Jupyter Notebook 作為編輯器
# 功能模組import pandas as pdimport numpy as npimport statsmodels.api as smimport matplotlib.pyplot as pltfrom scipy.stats import wilcoxon# TEJ APIimport tejapitejapi.ApiConfig.api_key = 'Your key'
Step 1. 撈取產業代碼、財務與股價資料
# 匯入 台灣交易所所有代碼code = tejapi.get("TWN/EWNPRCSTD",paginate=True,opts={'columns':['coid', 'mdate', 'stypenm','market','tseindnm']},chinese_column_name=True)# 匯入 財務資料data = tejapi.get('TWN/AIM1A',coid = code['證券碼'].tolist(),mdate= {'gte': '2012-01-01','lte':'2020-12-31'},opts={'pivot':True,'columns':['coid', 'mdate','0010','0130','R531','7210','3100','0400','3990']},chinese_column_name=True,paginate=True)# 匯入 財報發布日data_annouce = tejapi.get('TWN/AIFINA',coid = code['證券碼'].tolist(),mdate= {'gte': '2012-01-01','lte':'2020-12-31'},opts={'columns':['coid', 'mdate', 'a0003']},chinese_column_name=True,paginate=True)
股價是日頻率資料,一檔股票至少有千筆資料,而 TEJ為維持主機運行的穩定,系統限制單次取得最大筆數為10,000筆,可使用 paginate=True 參數分次取得資料,但總筆數單次最多為1,000,000筆。故我們可以將公司以50家分一組,以便迴圈分次撈取資料。
groups = []while True:if len(security_list) >= 50:groups.append(security_list[:50])security_list = security_list[50:]elif 0 <= len(security_list) < 50:groups.append(security_list)break# 匯入未調整股價data_price = pd.DataFrame()for group in groups:data_price = data_price.append(tejapi.get('TWN/APRCD',coid = group,mdate= {'gte': '2013-03-01','lte':'2021-3-31'},opts={'columns':['coid', 'mdate','close_d']},chinese_column_name = True,paginate = True)).reset_index(drop=True)
Step 2. 只保留三月底收盤價與年底資料
將欄位名稱改成相同欄位名稱,以便合併不同 Dataframe時,不會重複出現相同欄位名稱。因為益本比的分母限定是每年三月底收盤價,故data_price只需要保留三月底股價資料,data 也只需要保留年底資料。
# 資料前處理code = code.rename({'證券碼': '公司'}, axis=1) # 改名字data = data.rename({'公司代碼':'公司'}, axis=1) # 改名字data_annouce = data_annouce.rename({'年/月':'財報年月'}, axis=1) # 改名字data_price = data_price.rename({'證券代碼':'公司'}, axis=1) # 改名字data_price['年'] = data_price['年月日'].dt.year - 1 # 改成財報年data_price = data_price[data_price['年月日'].dt.month == 3]data_price = data_price.drop_duplicates(subset=['公司','年'], keep='last') # 只保留三月底收盤價data['年'] = data['財報年月'].dt.yeardata = data.drop_duplicates(subset=['公司','年'], keep='last') # 只保留年底資料
Step 3. 合併不同資料庫資料
# 合併資料
data = data.merge(code[['TSE產業名','公司']] ,how = 'left' ,on=['公司'])
data = data.merge(data_annouce,how = 'left' ,on=['公司','財報年月'])
data = data.merge(data_price[['公司','年','收盤價(元)']] ,how = 'left' ,on=['公司','年'])將財報發布日與三月底股價資料合併至同一個dataframe中。

Step 1. 準備 DCA所需的財務資料
本文採用 Jones(1991)模型,Jones(1991)研究認為應計項目中,受到經濟環境影響的部分與銷貨有關;折舊性資產毛額與總應計項目中之非裁決性折舊費用有關。同時,因為產業有商業模式的差異;公司有規模的差異,所以我們應該進一步考量產業差異與公司規模。故我們要先整理上述提及的財務資料。
# 計算 DCAdata['Total accrual'] = (data['常續性稅後淨利'] - data['來自營運之現金流量']) * data['DCA 前期資產總額倒數'] # Ydata['DCA 前期資產總額倒數'] = 1 / data.groupby('公司')['資產總額'].shift(1) # X0data['DCA 營業收入差'] = data.groupby('公司')['營業收入淨額'].diff() * data['DCA 前期資產總額倒數'] # X1data['DCA 不動產廠房及設備'] = data['不動產廠房及設備'] * data['DCA 前期資產總額倒數'] # X2data['DCA 營業收入差 - 應收差'] = (data.groupby('公司')['營業收入淨額'].diff() -data.groupby('公司')['應收帳款及票據'].diff()) * data['DCA 前期資產總額倒數'] # X1
透過產業分組迴歸,排除產業差異,同時將相似產業分於同組,避免單一產業家數過少,迴歸產生不可靠的統計數字;透過前期總資產平減,排除公司規模差異。
# 分組相似產業data['產業分組'] =np.select([(data['TSE產業名'].isin(["食品工業","紡織纖維","造紙工業"])) ,(data['TSE產業名'].isin(["塑膠工業","橡膠工業","化學工業","油電燃氣業"])),(data['TSE產業名'].isin(["汽車工業","鋼鐵工業"])),(data['TSE產業名'].isin(["電機機械","電器電纜"])),(data['TSE產業名'].isin(["水泥工業","建材營造","玻璃陶瓷"])),(data['TSE產業名'].isin(["資訊服務業","電子商務","貿易百貨"])),(data['TSE產業名'].isin(["觀光事業","航運業","文化創意業"])),(data['TSE產業名'].isin(["生技醫療"])),(data['TSE產業名'].isin(["光電業"])),(data['TSE產業名'].isin(["半導體"])),(data['TSE產業名'].isin(["電腦及週邊"])),(data['TSE產業名'].isin(["通信網路業"])),(data['TSE產業名'].isin(["電子零組件"])),(data['TSE產業名'].isin(["其他電子業","電子通路業","農業科技","其他"]))],list(range(14)), default = np.nan)
Step 2. 分年與產業計算 DCA
設定資產總額、營業收入與不動產廠房及設備為解釋變數,應計數字為被解釋變數,透過逐年迴歸同產業的財務資料,可獲得每家公司應計數字的迴歸模型觀察值與實際值,而實際值-觀察值的差額便是 DCA,若 DCA大於0,則表示該公司盈餘管理程度大於公司所屬產業。
# 計算 DCAdef regress(data):'''每年不同產業分組跑迴歸,主要用來獲得迴歸係數'''data = data[['Total accrual','DCA 前期資產總額倒數','DCA 營業收入差','DCA 不動產廠房及設備']].dropna()Y = data['Total accrual']X = data[['DCA 前期資產總額倒數','DCA 營業收入差','DCA 不動產廠房及設備']]X = X.rename(columns={"DCA 前期資產總額倒數": "alpha 前期資產總額倒數","DCA 營業收入差": "alpha 營業收入差","DCA 不動產廠房及設備": "alpha 不動產廠房及設備",})try:result = sm.OLS(Y, X).fit()return result.paramsexcept ValueError:passdata = data.merge(data.groupby(['財報年月','產業分組']).apply(regress).reset_index(),how = 'left' ,on = ['財報年月','產業分組'])data['Normal accrual'] = (data['alpha 前期資產總額倒數'] * data['DCA 前期資產總額倒數']+ data['alpha 營業收入差'] * data['DCA 營業收入差 - 應收差']+ data['alpha 不動產廠房及設備'] * data['DCA 不動產廠房及設備'])data['DCA'] = data['Total accrual'] - data['Normal accrual']
Step 3. 益本比分組
將全部公司以益本比 Earnings-Price Ratio來分組,可進一步判斷是否特定益本比範圍內的公司有沒有異常的盈餘管理程度。
# 計算益本比,並以0.0125分組。def cal_EP_label():'''獲得 EP ratio分組下的公司數,num=33,切0.025'''label = np.linspace(-0.2, 0.2, num=33).tolist()label = [ '%.4f' % elem for elem in label ]label.insert(0,-np.inf)label.insert(len(label),np.inf)label = np.array(label, dtype=float)return labeldata['益本比'] = data['每股盈餘'] / data['收盤價(元)']data['益本比分組'] = pd.cut(data['益本比'],bins = cal_EP_label() ,right=True)
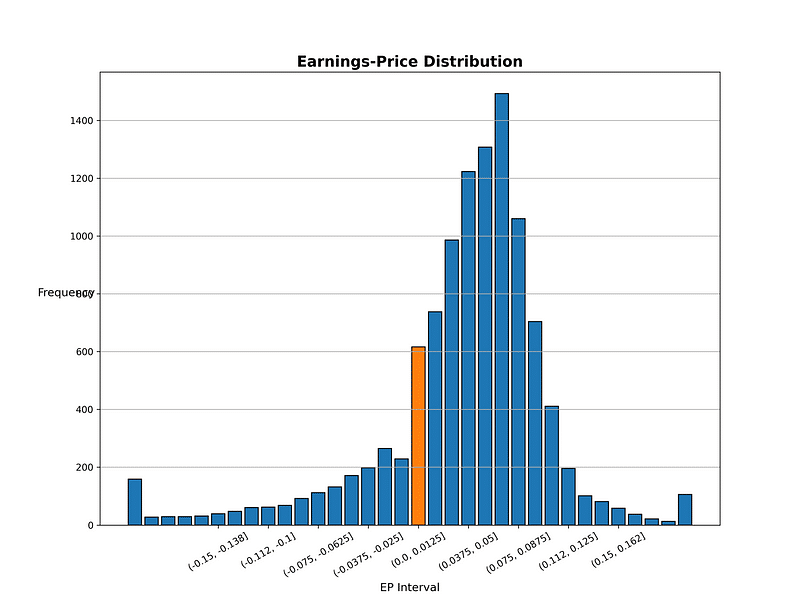
Step 1. 做圖觀察益本比分布狀況
下圖益本比分布落在(-0.0125, 0.0]與(0.0, 0.0125]的公司數有顯著的差異,這是否表明在此益本比範圍內的公司管理層面對盈餘虧損時,存在損失趨避行為,因為虧損不好向股東交代,而操弄盈餘管理,使每股盈餘由負轉正。
#%% 做圖 觀察益本比分組狀況fig = plt.figure(figsize = (12,9))ax = fig.add_subplot()factor = data.groupby(['益本比分組'])['公司'].count().reset_index()['益本比分組'].astype(str)value = data.groupby(['益本比分組'])['公司'].count().reset_index()['公司']ax.bar(factor,value,fill = '#eb3434',edgecolor = 'black')ax.bar('(0.0, 0.0125]',value[17],fill = '#eb344f',edgecolor = 'black')ax.set_title('Earnings-Price Distribution',fontsize=16,fontweight='bold')ax.set_xticks(['(-0.15, -0.138]','(-0.112, -0.1]','(-0.075, -0.0625]','(-0.0375, -0.025]','(0.0, 0.0125]','(0.0375, 0.05]','(0.075, 0.0875]','(0.112, 0.125]','(0.15, 0.162]'])plt.grid(axis='y')plt.xticks(rotation=30)plt.xlabel('EP Interval',fontsize=12)plt.ylabel('Frequency',fontsize=12, rotation=0)plt.show()
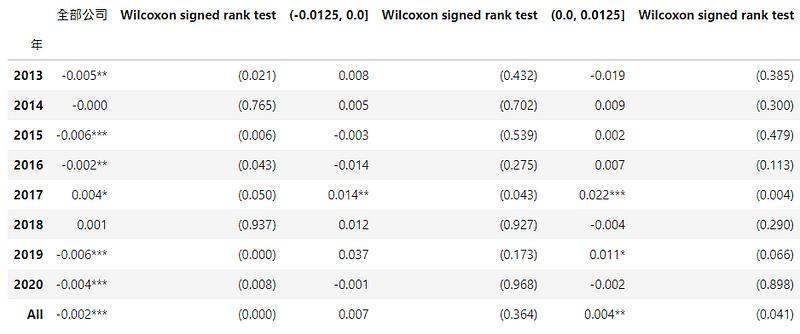
Step 2. 做表觀察益本比分組與盈餘管理程度關係
對益本比分組分別進行威爾卡森符號檢定 (Wilcoxon signed-rank test)的中位數檢定,發現全部公司 DCA的中位數為-0.002,且顯著不為0,而益本比落在(-0.0125, 0.0]與(0.0, 0.0125]範圍的公司,其 DCA 中位數為0.004,且(0.0, 0.0125]顯著不為0,可以得知益本比落在(0.0, 0.0125]的公司普遍存在盈餘管理。
def cal_wilcoxon(group):return pd.DataFrame({'DCA': group.median(),'p-value': wilcoxon(group)[1]}, index = [0])def add_star(df,p_value):'''p-values of the Wilcoxon signed rank test <= 0.01,則係數新增***0.01 < p-values of the Wilcoxon signed rank test <= 0.05,則係數新增**0.1 < p-values of the Wilcoxon signed rank test <= 0.01,則係數新增*'''df = np.select([(p_value <= 0.01),(p_value > 0.01) & (p_value <= 0.05),(p_value > 0.05) & (p_value <= 0.1)],[df.apply(lambda x: '%.3f'%x + '***'),df.apply(lambda x: '%.3f'%x + '**'),df.apply(lambda x: '%.3f'%x + '*')],default = df.apply(lambda x: '%.3f'%x))return dfdef run_data_cal_wilcoxon(df):'''p-values of the Wilcoxon signed rank test for one sample median DCA equal to 0'''finaldf = pd.DataFrame()for data in df:temp = data.dropna(subset=['DCA']).groupby('年')['DCA'].apply(cal_wilcoxon).reset_index(level=1, drop=True)temp.loc['All','DCA'] = data.dropna(subset=['DCA'])['DCA'].median()temp.loc['All','p-value'] = wilcoxon(data.dropna(subset=['DCA'])['DCA'])[1]temp['DCA'] = add_star(temp['DCA'],temp['p-value'])temp['p-value'] = temp['p-value'].apply(lambda x: '(' + '%.3f'%x + ')')finaldf = pd.concat([finaldf, temp], axis=1)return finaldfTable = run_data_cal_wilcoxon([data,data[data['益本比分組'].astype(str).isin(['(-0.025, 0.0]'])],data[data['益本比分組'].astype(str).isin(['(0.0, 0.025]'])]])
在損失趨避行為普遍存在下,人面對損失比對收益更敏感,所以公司管理層面對小虧損時,有極高的誘因透過裁決性應計項目(Discretionary Accruals)來操弄盈餘管理,使每股盈餘由負轉正,來滿足股東與資本市場的期待。
本文透過逐年衡量公司與產業的盈餘管理程度,我們可以一次找出明顯高於產業平均的公司,以及發現益本比落在(-0.0125, 0.0]與(0.0, 0.0125]範圍內的公司存在較高的盈餘管理程度。
