
Table of Contents
三一投資管理公司(Trinity Investment Management) 創立於1974年,原本只提供投資機構客戶投資研究建議,自1980年開始為客戶管理投資組合,1999年成為美國最大的共同基金及投資管理集團之一的歐本海默基金公司(Oppenheimer Funds, Inc.)的一員。
至2000年第一季底為止,三一投資管理公司為客戶管理的資產總額達42億美元,其投資哲學以價值導向為主,並認為建立成功的價值型投資組合,只需要以單純而簡化的概念及系統性的設計即可,只是大部份的基金經理人不承認而已。
根據三一公司多年的研究,綜合本益比、股價帳面價值比及股利收益率三項要素建立投資組合,在1980至1994年的15年間,年平均投資報酬率達20.1%,每年戰勝S&P500指數達6.8%;三一投資管理公司的總裁史丹佛凱德伍德(Stanford Calderwood)特別強調股利收益對價值型投資者的重要性,並認為成長型基金經理人所使用的預測性資料,對投資組合的績效表現沒有價值。
本篇文章屬於實戰策略,因此不論是篇幅還是難度上都有一定的程度,但請大家不要慌張,我們在文末都有提供完整程式碼與聯繫方式,若有看不懂或不會的都歡迎詢問我們~
1. 1980至1994年間S&P500指數中,以本益比最低的30%股票為投資組合(每季更新替換),年平均報酬率為17.5%,而同期S&P500指數的報酬率13.3%
2. 1980至1994年間,以股價帳面價值比最低的30%的股票為投資組合(每季更新替換),年平均報酬率為18.1%,高出S&P500指數報酬率4.8%。
3. 以股利收益率最高的30%股票為投資組合,年平均報酬率達18.3%,高出S&P500指數報酬率5%。
1. 將各公司當天的的本益比由低到高進行排序,取最低的前30%公司
2. 將各公司當天的股價帳面價值比由低到高進行排序,取最低的前30%公司
3. 將各公司當天的股利收益率由高到低進行排序,取最高的前30%公司
4. 最後我們取這三個條件的聯集,也就是任一個標準符合即可,而之所以不取交集的原因,是因為這三者同時都要滿足,就是一間本益比偏低、PB比偏低但股利率卻偏高的公司,很有可能有長期經營成長的問題,且高股利率可能是在掩飾股價長期可能走低得市場預期。
那講解完之後,我們就開始進入實做過程吧!!
Let’s Coding!!
import tejapi import pandas as pd import numpy as np tejapi.ApiConfig.api_key = "your key" tejapi.ApiConfig.ignoretz = True import datetime import matplotlib.pyplot as plt from datetime import datetime, timedelta from functools import reduce
首先自 TW50.csv 中擷取台灣50指數成分股資料,但成分股的資料格式為(1101 台泥),而 tejapi.get 函數中 coid 是專門用來控制股票代碼的參數,coid 僅接受數字,程式碼第二行的主要功能在將成分股當中的股票代碼抽離。
接著就是透過TWN/AIM1A以及TWN/APRCM兩個資料庫分別拿到財務資料以及股價資料,並透過pandas裡面的resample函數將日資料更換為季資料。
stk_info = pd.read_csv('TW50.csv',engine='python')
stk_nums = stk_info['成份股'].apply(lambda x: str(x).split(' ')[0])
strategy_cols = ['公司代碼','財報年月','當季季底P/E', '當季季底P/B', '股利殖利率']
## 2008年到2020年 # 撈取財務資料及股價資料 df_foundamental = pd.DataFrame() q_df_stock = pd.DataFrame() df_stock_Qrt = pd.DataFrame()
for stk in stk_nums:
df_foundamental = df_foundamental.append(tejapi.get('TWN/AIM1A'
,coid=stk
,mdate={'gte':'2008-01-01', 'lte':'2020-12-31'}
,paginate=True,chinese_column_name=True
,opts={'pivot':True}
)).reset_index(drop=True)
df_stock = tejapi.get('TWN/APRCM'
,coid=stk
,mdate={'gte':'2008-01-01', 'lte':'2020-12-31'}
,paginate=True,chinese_column_name=True)
q_df_stock = q_df_stock.append(df_stock.resample('Q', on='年月').last().reset_index(drop=True))
這邊我們除了用0050csv之外,我們提供另外一種方法給大家一樣地可以將0050成份股給挑選出來,也就是靠我們神通廣大甚麼都有的TEJ API資料庫啦!我們透過TWN/AIDXS資料庫,可以直接找到0050在當下時間點的成分股有哪些,然後資料經過整理後可以一樣地將ticks找出來。
df_indexcomp = tejapi.get('TWN/AIDXS', coid= 'TWN50',
opts={'columns':['coid', 'mdate', 'key3']},
mdate='gte':'2021/02/25','lte':'2021/02/25'},paginate=True)
df_indexcomp['stk'] =
[df_indexcomp.iloc[i,2].split(' ')[0] for i in range(df_indexcomp.shape[0])]
df_indexcomp['name'] =
[df_indexcomp.iloc[i,2].split(' ')[1] for i in range(df_indexcomp.shape[0])]
ticks = df_indexcomp.stk.unique()

TWN/AIDXS資料庫內容

接下來因為我們要讓兩個資料表進行整併的動作,因此我們要將兩個資料裡面的欄位重新命名以及選擇我們要的資料後透過pandas裡面的merge函數進行合併。
##財務table整理
df_foundamental.rename(columns={'公司代碼':'coid','財報年月':'日期'},inplace=True)
df_foundamental = df_foundamental[['coid','日期','當季季底P/E', '當季季底P/B', '股利殖利率']]
##股價table整理
q_df_stock.rename(columns={'證券代碼':'coid','年月':'日期'},inplace=True)
q_df_stock = q_df_stock[['coid','日期','收盤價(元)_月']]
##股價併財報 new_df = pd.merge(q_df_stock, df_foundamental, on = ['日期', 'coid']) new_df.sort_values(by='日期').reset_index(drop=True)
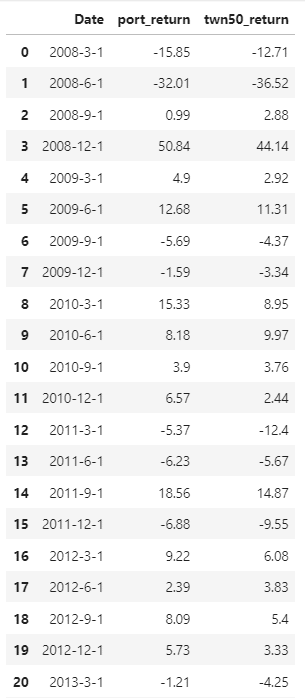
整理完之後,就可以看到以下的資料表,0050成分股從2008年開始到2020年的季資料以及每季的PE、PB以及股利殖利率。
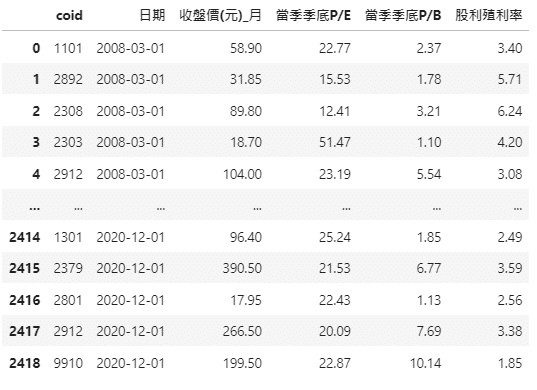
由於我們這邊會需要三個主要的條件,分別是由低到高前30%PE、PB以及由高到低前30%的股利殖利率,因此我們透過先將日期從原先的2008–03–01更換為200803的方式,再使用pandas當中的groupby函數將同為200803的通通放在一塊進行比較,將我們的篩選條件先呈現出來。
##時間資料格式更換 new_df['日期'] = pd.to_datetime(new_df['日期']) new_df['Month'] = new_df['日期'].apply(lambda x:datetime.strftime(x,'%Y%m'))
##將相同組別的資料透過groupby進行條件設置
df_pe_quantile = new_df.groupby('Month')['當季季底P/E'].quantile(0.3).reset_index().rename(columns={'當季季底P/E':'PE月quantile'})
df_pb_quantile = new_df.groupby('Month')['當季季底P/B'].quantile(0.3).reset_index().rename(columns={'當季季底P/B':'PB月quantile'})
df_div_quantile = new_df.groupby('Month')['股利殖利率'].quantile(0.7).reset_index().rename(columns={'股利殖利率':'Div月quantile'})
##多表資料合併 df_merged = reduce(lambda left,right: pd.merge(left,right,on=['Month'],how='outer'), [new_df,df_pe_quantile,df_pb_quantile,df_div_quantile])
整理完之後,可以看到以下資料除了原先的欄位之外,多了我們的篩選條件值。
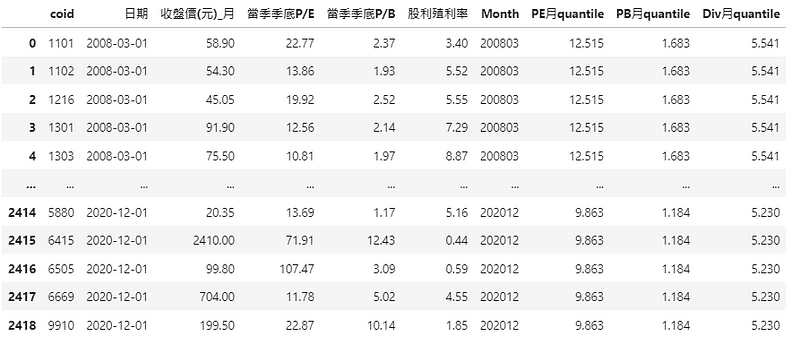
接下來就可以透過pandas當中的欄位條件選擇方法將符合我們上述三個條件的成分股選出來囉!
##條件篩選 df_filter = df_merged[ (df_merged['當季季底P/E'] < df_merged['PE月quantile'])| (df_merged['當季季底P/B'] < df_merged['PB月quantile'])| (df_merged['股利殖利率'] > df_merged['Div月quantile'])] .reset_index(drop =True)
選完後可以明顯看到我們的資料從2419個變成1386個,接近一半的資料量不見了,那我們這邊用兩種方式呈現給大家,一種是按照coid排序,另一種是按照日期排序的表格。
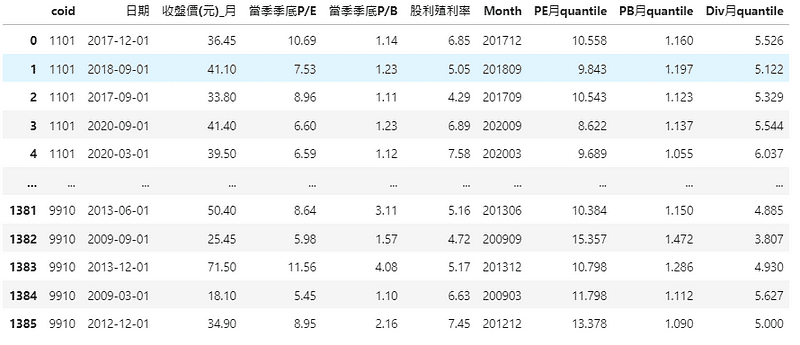
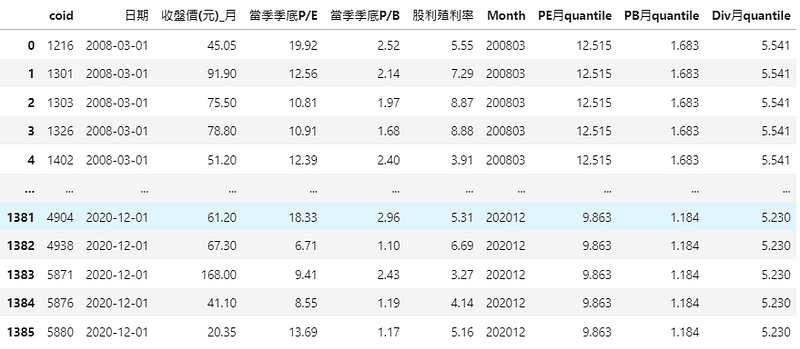
(程式碼以及參數解說部份可以主要參閱【實戰應用(一)】裡面的第四步噢,除了時間軸以及分組之外,剩餘的參數以及邏輯概念皆相似)
由於該策略是會每季更換投資組合以及我們可以透過TEJ裡面TWN/APRCD2資料庫直接找到該公司之當季報酬率,所以我們透過投資組合每一季度一天的報酬率跟0050的季度報酬率進行比較。程式碼如下:
*本次回測忽略交易成本
接著就可以看我們的return圖表拉~
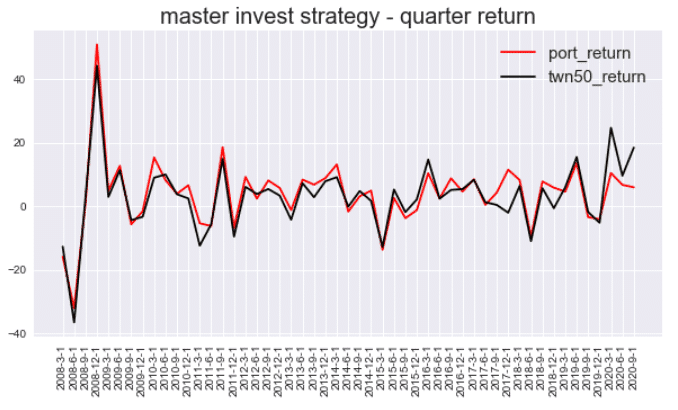
在這一步我們將簡單的將季報酬以及累積報酬率分別以圖形的方式呈現給大家。
##計算單季報酬以及累積報酬 cum_ret = ((return_[['port_return', 'twn50_return']].astype(float)*0.01)+1).cumprod() cum_ret['Date'] = return_['Date'] cum_ret = cum_ret[:len(cum_ret)-1] cum_ret = cum_ret[['Date','port_return','twn50_return']]
quarter_ret = return_[['port_return', 'twn50_return']].astype(float) quarter_ret['Date'] = return_['Date'] quarter_ret = quarter_ret[:len(quarter_ret)-1] quarter_ret = quarter_ret[['Date','port_return','twn50_return']]
每季報酬:
plt.style.use('seaborn')
plt.figure(figsize=(10,5))
plt.xticks(rotation = 90)
plt.title('master invest strategy - quarter return',fontsize = 20)
date = quarter_ret['Date']
plt.plot(date,quarter_ret.port_return,color ='red',label='port_return')
plt.plot(date,quarter_ret.twn50_return,color = 'black',label='twn50_return')
plt.legend(fontsize = 15)
累積報酬:
plt.style.use('seaborn')
plt.figure(figsize=(10,5))
plt.xticks(rotation = 90)
plt.title('master invest strategy - cumulative return',fontsize = 20)
date = cum_ret['Date']
plt.plot(date,cum_ret.port_return,color ='red',label='port_return')
plt.plot(date,cum_ret.twn50_return,color = 'black',label='twn50_return')
plt.legend(fontsize = 15)
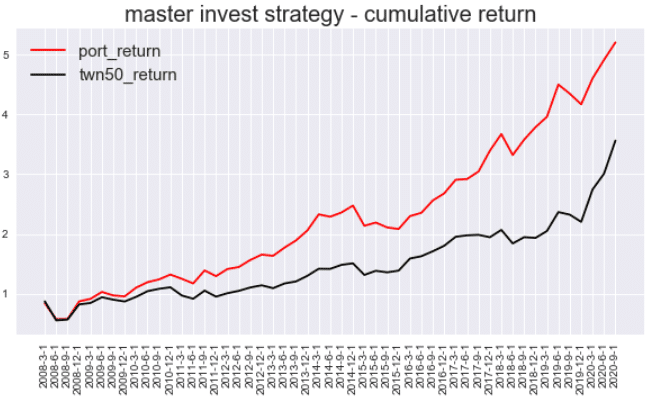
結果可以看到走勢相近,但表現可以說是非常的突出!!
績效/統計指標:
Ratio = pd.DataFrame()
for col in cum_ret.columns[1:]:
##年化報酬率
cagr = (cum_ret[col].values[-1]) ** (4/len(cum_ret)) -1
##年化標準差
std = return_[col][:len(return_)-1].astype(float).std()
##Sharpe Ratio(假設無風險利率為1%)
sharpe_ratio = (cagr-0.01)/(std*0.01)
##最大回撤
roll_max = cum_ret[col].cummax()
monthly_dd =cum_ret[col]/roll_max - 1.0
max_dd = monthly_dd.cummin()
##表格
ratio = np.reshape(np.round(np.array([100*cagr, std, sharpe_ratio, 100*max_dd.values[-1]]),2),(1,4))
Ratio = Ratio.append(pd.DataFrame(index=[col],
columns=['年化報酬率(%)', '年化標準差(%)', '夏普比率', '期間最大回撤(%)'],
data = ratio))
Ratio.T
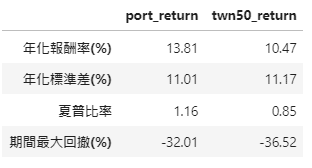
可以看到透過我們三一的價值型選股方式,在每一個指標項目上皆優於0050!!
2020–12月之成分股:
pf = df_filter[df_filter['日期']== '2020-12-01'].reset_index(drop=True)
# 回台灣 50成分股查詢 P1組合的名稱
stk_info['stk_num'] = stk_info['成份股'].apply(lambda x: str(x).split(' ')[0])
stk_info['stk_cname'] = stk_info['成份股'].apply(lambda x: str(x).split(' ')[1])
stk_info['成份股'][stk_info['stk_num'].isin(pf['coid'].tolist())].to_list()

我們透過python分別實作了數個大師策略,除了資料整理之外也對其進行了回測,並透過表格及視覺化的方式呈現了結果。希望大家能滿意我們的產出 ~
但要做出一個成功的回測,要考慮的因素還很多像是資料品質、資料長度、程式是否有BUG、交易成本是否忽略過多、若是使用基本面還會有資料時間軸等等的相關問題。上述這些問題只要有一個地方出錯都會造成回測的失真,如果還依據這個結果將資金丟入市場,最嚴重就是造成虧損,所以一定要再三注意❗️️️️ ❗️️️️
我們之後也會再分享更多量化投資相關的文章,如果讀者們有甚麼想要回測策略都歡迎在下方留言,我們會挑選合適的主題來進行撰寫喔~最後,如果喜歡本篇文章的內容請幫我們點擊下方圖示 ,給予我們更多支持與鼓勵,有任何的問題都歡迎在下方留言/來信,我們會盡快回覆大家
有任何使用上的問題都歡迎與我們聯繫:聯絡資訊

