
Table of Contents
柏頓.墨基爾(Burton G. Malkiel)是普林斯頓大學(Princeton University)華友銀行的講座教授(Chemical Bank Chairman’s Professor of Economic)曾任職於史密斯巴尼(Smith Barney & Co.)投資銀行部門及數家大型投資機構的董事,如先鋒集團(Vanguard Group of Investment Companies),保德信人壽(Prudential Insurance Company of America)等,也曾獲聘為美國總統經濟諮詢委員會的委員,在學術界及投資界,皆是各方敬重的翹楚。柏頓.墨基爾最為人知的是於1973年出版的著作【漫步華爾街】(A Random Walk down Wall Street- Including A life-cycle Guide to Personal Investing),至今仍持續再版,是華爾街影響力量最深遠的名著之一;基本面上,柏頓.墨基爾是隨機漫步理論(Random Walk)的支持者,他認為效率市場假說(EMT)雖然有瑕疵,但大體上是正確的,而傳統的磐石理論(Firm Foundation theory,如價值投資)及空中樓閣理論(Castle-in-the-air theory,如技術分析)並無任何預測未來的能力,成功的基金經理人如鳳毛鱗爪,大部份是靠運氣,因此他認為投資比較像藝術,而非科學,但他在漫步華爾街一書,也提出一些投資者在面對市場時的投資之道,以供投資者遵循。
所以他認為投資人要投資成功,有三種方法,(一)購買指數型基金,(二)尋找傑出的基金經理人請他代打,(三)深思熟慮的自行投資,並且大多數時候他比較傾向第一種,但如果你真的很希望能夠親自參與市場行情的話,他提出了以下操作建議:
基於墨基爾的理念,我們加上了一些針對台股市場的調整完成一下策略,使用的參數如下表

雖然墨基爾認為預期的成長與股利發放是決定股價的重要因素,但他並不認為所謂的分析師市場共識具有足夠的準確度,因此不鼓勵投資人納入模型。

為了捕捉過去與現在的營收與獲利表現,我們使用 近四年營收成長率與稅後淨利成長率相對於產業平均的表現 來衡量企業的持續成長力。具體而言,若公司在過去四年間有至少兩年營收成長高於產業平均,且至少三年淨利成長優於同業,則視為具備穩定成長特質。最後,在符合上述標準的公司中,依照 PER_Position(本益比排序位置)由小到大排列,選取估值相對最低的前 30 檔股票納入投資組合,並每 120 天重新平衡一次,以維持組合的基本面優勢。
#%% Package
import pandas as pd
import numpy as np
import tejapi
import os
import json
import matplotlib.pyplot as plt
import yaml
''' ------------------- 不使用 config.yaml 管理 API KEY 的使用者可以忽略以下程式碼 -------------------'''
notebook_dir = os.path.dirname(os.path.abspath(__file__)) if '__file__' in globals() else os.getcwd()
yaml_path = os.path.join(notebook_dir, '..', 'config.yaml')
yaml_path = os.path.abspath(os.path.join(notebook_dir, '..', 'config.yaml'))
with open(yaml_path, 'r') as tejapi_settings: config = yaml.safe_load(tejapi_settings)
''' ------------------- 不使用 config.yaml 管理 API KEY 的使用者可以忽略以上程式碼 -------------------'''
# ----------------------------------------------------------------------------------------------------
KEY = config['TEJAPI_KEY'] # = "https://api.tej.com.tw"
BAS = config['TEJAPI_BASE'] # = "YOUR_API_KEY
tejapi.ApiConfig.api_key = KEY
tejapi.ApiConfig.api_base = BAS
os.environ['TEJAPI_BASE'] = BAS
os.environ['TEJAPI_KEY'] = KEY
# ----------------------------------------------------------------------------------------------------
from zipline.sources.TEJ_Api_Data import get_universe
import TejToolAPI
from zipline.data.run_ingest import simple_ingest
from zipline.api import set_slippage, set_commission, set_benchmark, symbol, record, order_target_percent
from zipline.finance import commission, slippage
from zipline import run_algorithm
from sklearn.linear_model import LinearRegression
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.family'] = 'Arial'
#%% Note
'''-------------------------------------------------------------------------------------------------------------------------------------
columns |En |Ch
----------------------------------------------------------------------------------------------------------------------------------------
per PER_TWSE 本益比(越小越好)
r401 Sales_Growth_Rate_TTM 營收成長率
r405 Net_Income_Growth_Rate_TTM 稅後淨利成長率
-------------------------------------------------------------------------------------------------------------------------------------'''
# 股票池條件
'''-------------------------------------------------------------------------------------------------------------------------------------
1. Sales_Growth_Rate_TTM ≥ 產業平均值
2. Sales_Growth_goodtimes ≥ 2(過去四年中至少兩年高於產業平均)
3. Net_Income_Growth_Rate_TTM ≥ 產業平均值
4. Net_Income_Growth_Rate_TTM_shift_1y ≥ 產業平均值(前一年度)
5. Net_Income_Growth_goodtimes ≥ 3(過去四年中至少三年高於產業平均)
6. 通過以上五項條件之公司,選取 PER_Position 前 30 小的公司組成投資組合。
-------------------------------------------------------------------------------------------------------------------------------------'''
# 額外設定
'''-------------------------------------------------------------------------------------------------------------------------------------
產業最小公司數:40 (< 40 的產業直接忽略)
再平衡頻率:120 天
-------------------------------------------------------------------------------------------------------------------------------------'''#%% 參數設定
# py ==================================================================================================================
date_start_data = '2015-01-01' # 會需要的資料起始日 (至少要設定比 data_start_pool 還早五年)
date_start_pool = '2020-01-01' # 回測起始日
date_end = '2025-07-18'
re_days = 120
# ---------------------------------------------------------------------------------------------------------------------
start_dt = pd.Timestamp(date_start_data, tz='UTC')
end_dt = pd.Timestamp(date_end, tz='UTC')
#%% 篩選股票池 & 匯入回測資料
# 使用get_universe 篩選股票池
pool = get_universe(
start = date_start_pool,
end = date_end,
mkt_bd_e= ['TSE', 'OTC'],
stktp_e = ['Common Stock-Foreign','Common Stock']
)
pools = pool + ['IR0001', 'IR0043'] # 加入大盤與櫃買指數
# simple_ingest 匯入回測資料
simple_ingest(name = 'tquant' , tickers = pools , start_date = date_start_data , end_date = date_end)
#%% 抓取歷史數據
c_use = [
'coid', 'mkt', 'main_ind_e', 'open_d', 'high_d', 'low_d', 'close_d',
'precls', 'vol', 'amt', 'roi',
'short_ta', 'qfii_pct', 'per', 'r401', 'r405'
]
# 使用 get_history_data 歷史數據
data_dttm = TejToolAPI.get_history_data(
start = start_dt,
end = end_dt,
ticker = pool + ['IR0001'],
fin_type= ['TTM'],
columns = c_use,
transfer_to_chinese = False
)
print(data_dttm.info())
data_dttm = data_dttm.sort_values(['mdate', 'coid'])
#%% 備份歷史數據
# data_dttm -> data_use,資料損毀時可以直接取用
data_use = data_dttm.copy()
data_use.rename(columns={'Industry_Eng':'Industry'}, inplace=True)
data_use
#%% 合併上市櫃公司的產業定義
# Get unique Industry
df_unique = pd.DataFrame(
sorted(data_use['Industry'].astype(str).unique()),
columns=['Industry']
)
df_unique['Industry'] = df_unique['Industry'].astype('object')
df_unique.dropna(inplace=True)
df_unique = df_unique[df_unique.apply(lambda x: x.astype(str).str.strip().ne('').all(), axis=1)]
# Extract 'Indu_Code' and 'Indu_Name'
df_unique[['Indu_Code', 'Indu_Name']] = df_unique['Industry'].str.extract(r'^([A-Z0-9]+)\s+(.+)$')
df_unique['Exch'] = df_unique['Industry'].apply(lambda x: 'TSE' if x.startswith('M') else ('OTC' if x.startswith('OTC') else None))
df_unique.dropna(subset=['Exch'], inplace=True)
# 合併上市與上櫃公司的產業分類
def create_unicode_with_exceptions(row):
industry_code = row['Indu_Code']
industry_name = row['Indu_Name']
if pd.isna(industry_code) or pd.isna(industry_name):
return pd.Series([None, None], index=['Unicode', 'UniIndu'])
exceptions = {
'OTC30': 'U2800',
'OTC32': 'U9900',
'OTC33': 'U1700',
'OTC34': 'U3600',
'OTC89': 'U9900'
}
if industry_code in exceptions:
unicode_val = exceptions[industry_code]
elif industry_code.startswith('OTC'):
number = ''.join(filter(str.isdigit, industry_code))
unicode_val = 'U' + str(int(number) * 100).zfill(4)
else:
number = ''.join(filter(str.isdigit, industry_code))
unicode_val = 'U' + number.zfill(4)
return pd.Series([unicode_val, industry_name], index=['Unicode', 'UniIndu'])
df_unique[['Unicode', 'UniIndu']] = df_unique.apply(create_unicode_with_exceptions, axis=1)
tse_names = df_unique[df_unique['Exch'] == 'TSE'].set_index('Unicode')['Indu_Name']
df_unique['Uniname'] = df_unique['Unicode'].map(tse_names).fillna(df_unique['Indu_Name'])
df_unique.dropna()
# Merge back to data_use
data_use = data_use.merge(df_unique[['Industry', 'Unicode', 'Uniname']], on='Industry', how='left')
data_use.dropna()
print(data_use[['Uniname', 'Unicode']].drop_duplicates())
data_use
#%% 檢視全樣本產業公司數 | 實際運算時每次都會判斷一次
# Note: 由於電子業規模龐大,可考慮使用子產業,這裡用產業示範
import warnings
import matplotlib.pyplot as plt
# 中文字體設定
warnings.filterwarnings("ignore", message="findfont")
plt.rcParams['font.family'] = 'Microsoft JhengHei'
plt.rcParams['axes.unicode_minus'] = False
# 去掉 Industry 是 '其他' 的公司
df = data_use[(data_use['Unicode'] != 'U9900') & data_use['Unicode'].notna()]
# 只保留每間公司 (coid) 的唯一組合
unique_companies = df[['coid', 'Uniname']].drop_duplicates()
# 計算每個產業的公司數占比
industry_company_no = unique_companies['Uniname'].value_counts()
# 去掉公司數小於40的產業 | 僅畫圖時有效,稍後計算要使用 industry_list 再刪一次 data_use
# industry_company_no = industry_company_no[industry_company_no >= 40]
print(industry_company_no)
# 避免前視偏誤,改次再平衡都判斷一次
# # 回傳 list 用來篩選 data_use
# industry_list = industry_company_no.index.tolist() # list of Uniname
# industry_list = df[df['Uniname'].isin(industry_list)]['Unicode'].unique().tolist() #
#%% 計算財務指標
# Data fillter & sort
# data_use = data_use[data_use['Unicode'].isin(industry_list)]
data_use = data_use.sort_values(['coid', 'mdate'])
# Sales_Growth_Rate_TTM
data_use['Sales_Growth_Rate_TTM_shift_1y'] = data_use.groupby('coid')['Sales_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 1))
data_use['Sales_Growth_Rate_TTM_shift_2y'] = data_use.groupby('coid')['Sales_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 2))
data_use['Sales_Growth_Rate_TTM_shift_3y'] = data_use.groupby('coid')['Sales_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 3))
data_use['Sales_Growth_Rate_TTM_shift_4y'] = data_use.groupby('coid')['Sales_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 4))
# Net_Income_Growth_Rate_TTM
data_use['Net_Income_Growth_Rate_TTM_shift_1y'] = data_use.groupby('coid')['Net_Income_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 1))
data_use['Net_Income_Growth_Rate_TTM_shift_2y'] = data_use.groupby('coid')['Net_Income_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 2))
data_use['Net_Income_Growth_Rate_TTM_shift_3y'] = data_use.groupby('coid')['Net_Income_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 3))
data_use['Net_Income_Growth_Rate_TTM_shift_4y'] = data_use.groupby('coid')['Net_Income_Growth_Rate_TTM'].transform(lambda x: x.shift(252 * 4))
# PER_Position
data_use['PER_Position'] = data_use['PER_TWSE'] / data_use.groupby(['mdate', 'Unicode'])['PER_TWSE'].transform('mean')
print(data_use.info())
data_use
#%% 計算選股積分
'''
這段程式會先計算每家公司在過去四年(1y~4y)各年度的營收或淨利成長率是否高於同產業平均,若高於則標記為 1 ,否則 0 ,
最後把四年的結果相加成一個「goodtimes」欄位,用來統計該公司在四年間高於產業平均的次數。
'''
# 計算某指標過去比產業平均高的次數
def cal_goodtimes(data_use, factor):
i = factor
for y in range(1,5):
data_use[f'{i}_good_{y}y'] = np.where(
data_use[f'{i}_Rate_TTM_shift_{y}y'] >=
data_use.groupby(['mdate', 'Unicode'])[f'{i}_Rate_TTM_shift_{y}y'].transform('mean'), 1, 0
)
data_use[f'{i}_goodtimes'] = sum(data_use[f'{i}_good_{y}y'] for y in range(1, 5))
return data_use
data_use = cal_goodtimes(data_use, 'Sales_Growth')
data_use = cal_goodtimes(data_use, 'Net_Income_Growth')
data_use
#%% 建立投資組合
'''
此函數在指定日期內,篩選營收與淨利成長均優於產業平均的公司。
程式先以五組條件建立公司集合:包括營收與淨利當期及前期成長率是否高於產業平均,以及高於平均的次數是否達標。
接著取所有條件的交集公司,再依本益比排序,選出最多30檔股票作為最終名單,並回傳股票清單與各條件通過公司數。
'''
def compute_stock(date, data):
df = data[data['mdate'] == pd.to_datetime(date)].reset_index(drop=True)
''''''
# 篩除產業公司數過少的公司
# 1. 計算當前日期下,每個產業的公司數
industry_counts = df['Uniname'].value_counts()
# 2. 找出公司數大於等於 40 的產業
valid_industries = industry_counts[industry_counts >= 40].index.tolist()
# 3. 從 df 中篩選出屬於這些有效產業的公司
df = df[df['Uniname'].isin(valid_industries)].copy()
# Sales_Growth_Rate_TTM > 0 & 產業平均值
i = 'Sales_Growth'
set_1 = set(df[df[f'{i}_Rate_TTM'] >= df.groupby(['mdate', 'Unicode'])[f'{i}_Rate_TTM'].transform('mean')]['coid'])
set_2 = set(df[df[f'{i}_goodtimes'] >= 2]['coid'])
# Sales_Growth_Rate_TTM > 0 & 產業平均值
i = 'Net_Income_Growth'
set_3 = set(df[df[f'{i}_Rate_TTM'] >= df.groupby(['mdate', 'Unicode'])[f'{i}_Rate_TTM'].transform('mean')]['coid'])
set_4 = set(df[df[f'{i}_good_1y'] == 1]['coid'])
set_5 = set(df[df[f'{i}_goodtimes'] >= 3]['coid'])
passed = set_1 & set_2 & set_3 & set_4 & set_5
top_n = 30 #int(len(passed))
# 篩選出通過條件的股票
filtered_df = df[df['coid'].isin(passed)]
# 排序並取前 top_n 名(例如 PEG 最小)
top_df = filtered_df.sort_values(by='PER_Position').head(top_n)
tickers = list(top_df['coid'])
sets = [
len(set_1), len(set_2), len(set_3),
len(set_4), len(set_5)
]
for i in range(1, 6):
s = locals()[f'set_{i}']
print(f'set {i}: {len(s)}')
return tickers, sets
#%% initialize
back_start = date_start_pool
# back_start = '2020-01-01'
def initialize(context, re = re_days):
set_slippage(slippage.VolumeShareSlippage(volume_limit=1, price_impact=0.01))
set_commission(commission.Custom_TW_Commission())
set_benchmark(symbol('IR0001'))
context.i = 0
context.state = False
context.order_tickers = []
context.last_tickers = []
context.rebalance = re
context.set1 = 0
context.set2 = 0
context.set3 = 0
context.set4 = 0
context.set5 = 0
context.set = 0
context.dic = {}
#%% handle_data
def handle_data_1(context, data):
# 避免前視偏誤,在篩選股票下一交易日下單
if context.state == True:
for i in context.last_tickers:
if i not in context.order_tickers:
order_target_percent(symbol(i), 0)
for i in context.order_tickers:
order_target_percent(symbol(i), 1.0 / len(context.order_tickers))
context.dic[i] = data.current(symbol(i), 'price')
record(p = context.dic)
context.dic = {}
print(f"下單日期:{data.current_dt.date()}, 擇股股票數量:{len(context.order_tickers)}, Leverage: {context.account.leverage}")
context.last_tickers = context.order_tickers.copy()
context.state = False
backtest_date = data.current_dt.date()
if context.i % context.rebalance == 0:
context.state = True
context.order_tickers = compute_stock(date = backtest_date, data = data_use)[0]
context.set = compute_stock(date = backtest_date, data = data_use)[1]
record(tickers = context.order_tickers)
record(Leverage = context.account.leverage)
if context.account.leverage > 1.2:
print(f'{data.current_dt.date()}: Over Leverage, Leverage: {context.account.leverage}')
for i in context.order_tickers:
order_target_percent(symbol(i), 1 / len(context.order_tickers))
context.i += 1
#%% OTC / TSE
codes = ['IR0001', 'IR0043']
co = ['coid','Industry', 'mkt','close_d']
data_index = TejToolAPI.get_history_data(start = start_dt,
end = end_dt,
ticker = codes,
columns = co,
transfer_to_chinese = False)
# 篩選時間
data_index = data_index[data_index['mdate'] >= back_start]
# 分別取出 TSE 與 OTC 並標準化
tse = data_index[data_index['coid'] == 'IR0001'][['mdate', 'Close']].copy()
otc = data_index[data_index['coid'] == 'IR0043'][['mdate', 'Close']].copy()
tse.rename(columns={'Close': 'TSE_Close'}, inplace=True)
otc.rename(columns={'Close': 'OTC_Close'}, inplace=True)
# 合併(on mdate)
merged = pd.merge(tse, otc, on='mdate', how='inner')
# 標準化:以首日為基準
merged['TSE_norm'] = merged['TSE_Close'] / merged['TSE_Close'].iloc[0] * 100
merged['OTC_norm'] = merged['OTC_Close'] / merged['OTC_Close'].iloc[0] * 100
# 計算風險偏好比(OTC / TSE)
merged['OTC_TSE_ratio'] = merged['OTC_norm'] / merged['TSE_norm']
#%% analyze
def analyze(context, perf):
plt.style.use('ggplot')
# 第一張圖:策略績效與報酬
fig1, axes1 = plt.subplots(nrows=3, ncols=1, figsize=(18, 15), sharex=False)
axes1[0].plot(perf.index, perf['algorithm_period_return'], label='Strategy')
axes1[0].plot(merged['mdate'], (merged['TSE_norm'] / merged['TSE_norm'].iloc[0])-1, label='Benchmark [TSE]')
axes1[0].plot(merged['mdate'], (merged['OTC_norm'] / merged['OTC_norm'].iloc[0])-1, label='Benchmark [OTC]')
axes1[0].set_title("Backtest Results")
axes1[0].legend()
# 第二張圖:策略超額報酬
axes1[1].bar(
perf.index,
perf['algorithm_period_return'] - perf['benchmark_period_return'],
label='Excess return',
color='#988ED5',
alpha = 1.0
)
axes1[1].set_title('Excess Return with TSE Index')
axes1[1].legend()
# 第三張圖:風險偏好比(OTC / TSE)
axes1[2].plot(merged['mdate'], merged['OTC_TSE_ratio'], label='OTC / TSE')
axes1[2].set_title('Risk Appetite Ratio (OTC / TSE)')
axes1[2].axhline(1.0, color='gray', linestyle='--', linewidth=1)
axes1[2].legend()
axes1[2].grid(True)
plt.tight_layout()
plt.show()
#%% run_algorithm
results = run_algorithm(
start = pd.Timestamp(date_start_pool, tz = 'utc'),
end = pd.Timestamp(date_end, tz = 'utc'),
initialize = initialize,
handle_data = handle_data_1,
analyze = analyze,
bundle = 'tquant',
capital_base = 1e5
)
# py ==================================================================================================================
#%% 計算投組績效
import pyfolio
from pyfolio.utils import extract_rets_pos_txn_from_zipline
import warnings
warnings.filterwarnings("ignore", message="findfont")
# plt.rcParams['font.sans-serif'] = ['Arial'] #, 'Noto Sans CJK TC', 'SimHei']
plt.rcParams['axes.unicode_minus'] = False
returns, positions, transactions = extract_rets_pos_txn_from_zipline(results)
benchmark_rets = results.benchmark_return
pyfolio.tears.create_full_tear_sheet(
returns = returns,
positions = positions,
transactions = transactions,
benchmark_rets = benchmark_rets
)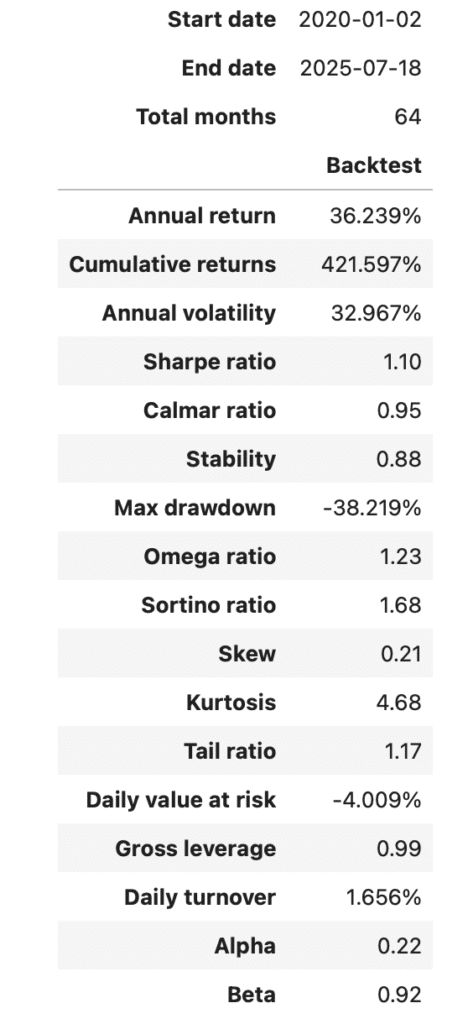
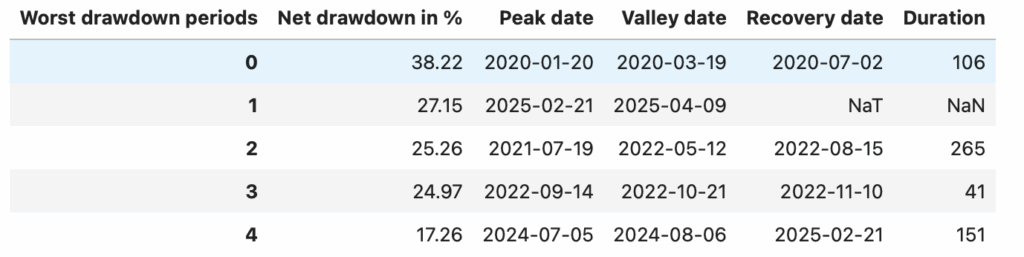
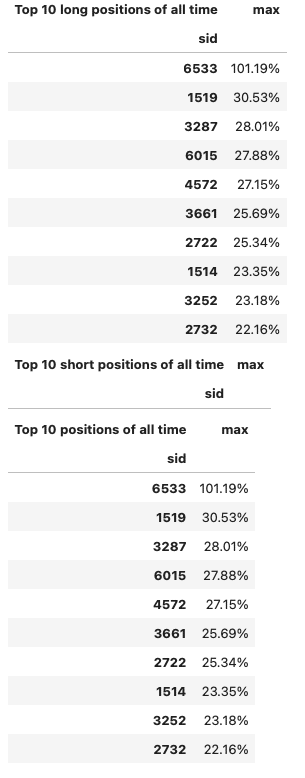
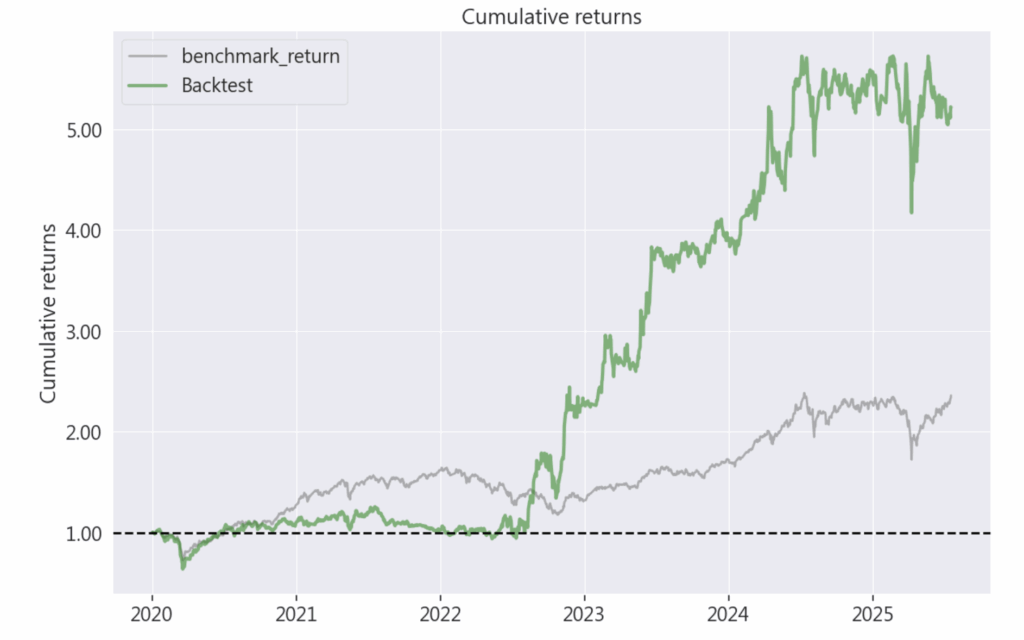
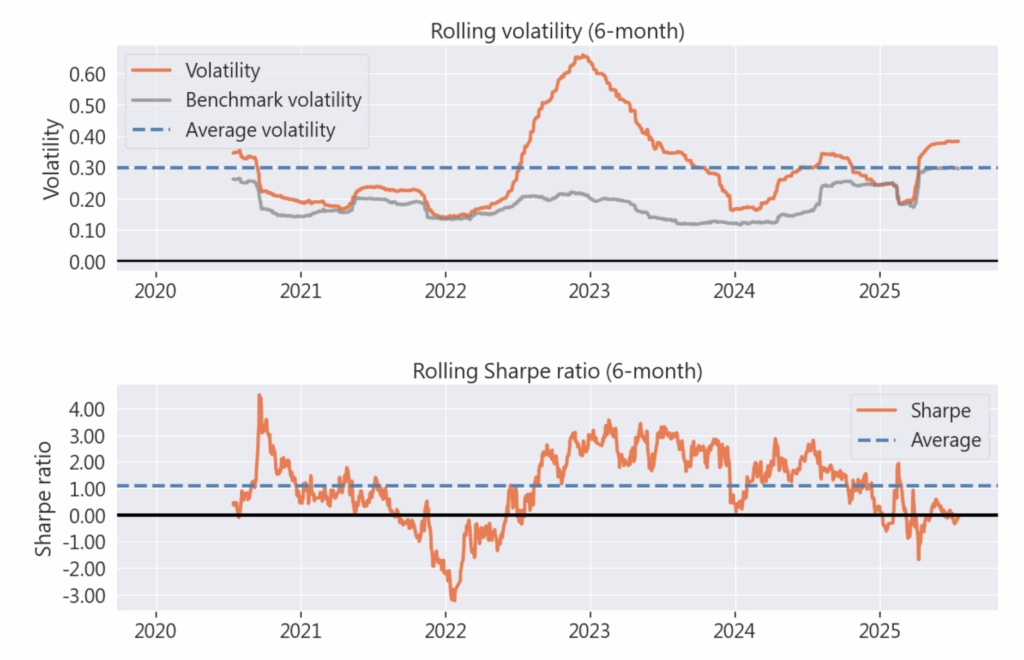
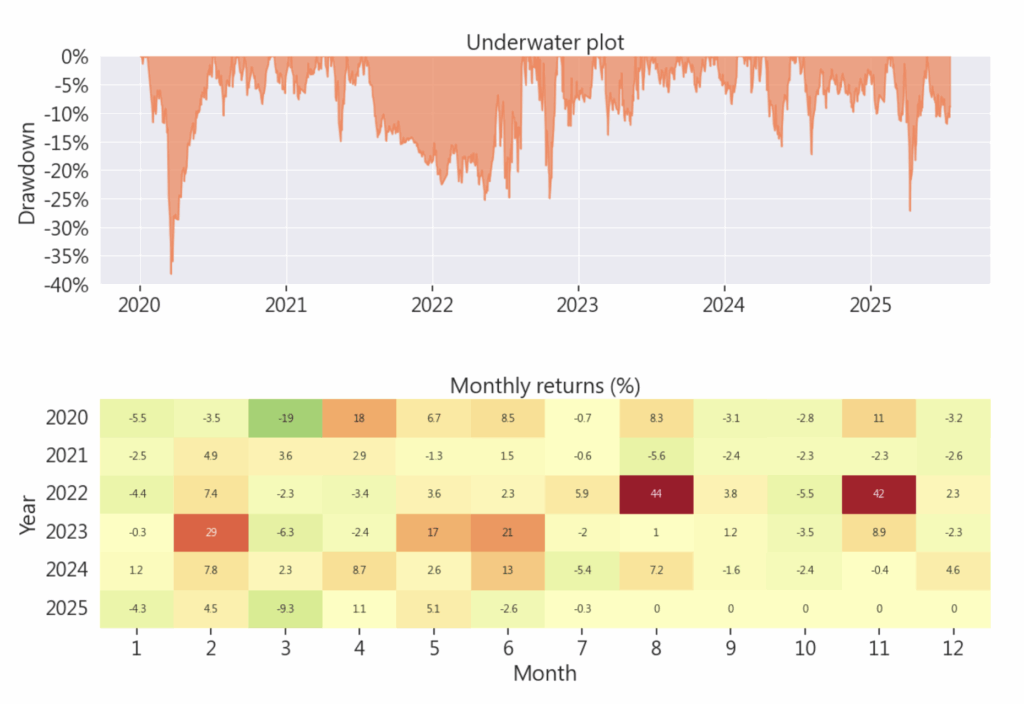
歡迎投資朋友參考,之後也會持續介紹使用 TEJ 資料庫來建構各式指標,並回測指標績效,所以歡迎對各種交易回測有興趣的讀者,選購 TQuant Lab 的相關方案,用高品質的資料庫,建構出適合自己的交易策略。
溫馨提醒,本次分析僅供參考,不代表任何商品或投資上的建議。
TEJ 知識金融學院正式上線—《TQuantLab 量化投資入門》課程強勢推出!
這門課程結合 TEJ 實證資料與專業量化方法,帶你從零開始掌握量化投資的核心概念,
協助金融從業人員、投資研究人員以及想強化投資邏輯的你,快速建立系統化分析能力!
