
Table of Contents
隨著高科技產業迅速發展,其股票也常成為市場焦點。然而,高科技股雖具備成長潛力,卻同時伴隨著極高的波動性與投資風險。投資人在追求高報酬的同時,若未妥善評估風險,容易面臨重大虧損。因此,如何有效衡量與控管高科技股的下跌風險,成為投資決策中不可忽視的一環。
在TQuant Lab中,我們使用電子工業當我們股票池再進行篩選,可以針對使用者需求調整自己需要的科技業類別。
以下資料使用欄位皆取自於Tquant Lab資料集
A :每股營業額 : 近12月累計營收_千元/流通在外股數
B : 每股帳面價值 : 股東權益總計_Q / 流通在外股數
C : 過去3年平均稅前盈餘成長率 : 稅前淨利成長率,取序號1的Q欄位,然後用pivot轉為矩陣後直接rolling(12).mean
D : 過去4季每股盈餘 : 每股淨值_TTM
E : 下跌風險值 (DRV) = ( A + 1.5 * B + C * D * 1/3) / 3
偏離值 : ( 股價 – 下跌風險值 ) / 股價
偏離值與風險的關係 : 正數代表具有大跌風險,正數越大風險越大,小於0表示可以投資,負值越大越安全。
import pandas as pd
import numpy as np
import tejapi
import os
import matplotlib.pyplot as plt
import datetime
plt.rcParams['font.family'] = 'Arial'
os.environ['TEJAPI_BASE'] = "YOUR BASE"
os.environ['TEJAPI_KEY'] = "YOUR KEY"
from zipline.sources.TEJ_Api_Data import get_universe
import TejToolAPI
from zipline.data.run_ingest import simple_ingest
from zipline.api import set_slippage, set_commission, set_benchmark, symbol, record, order_target_percent
from zipline.finance import commission, slippage
from zipline import run_algorithm
import pandas as pd
from zipline.pipeline.data import Column, DataSet
from zipline.pipeline.loaders.frame import DataFrameLoader
from zipline.pipeline import Pipeline
from zipline.pipeline.engine import SimplePipelineEngine
from zipline.pipeline.domain import TW_EQUITIES
from zipline.pipeline.factors import CustomFactor
在選擇回測的時間點時,選擇電子工業。在此步驟中,可以檢查股票池是否包含具有不喜歡特性的股票,並根據需求進行適當調整。
pool = get_universe(start = '2018-01-01',
end = '2024-12-31',
mkt_bd_e = ['TSE', 'OTC', 'TIB'], # 已上市之股票
stktp_e = 'Common Stock', # 普通股
main_ind_c = 'M2300 電子工業,OTC23 OTC 電子類') # general industry 可篩掉金融產業
透過 tejapi 獲取稅前淨利成長率,進而去計算上述數據C (過去3年平均稅前盈餘成長率)
data_r404 = tejapi.get('TWN/AINVFQ1', mdate = {'gte':'2015-01-01', 'lte': '2024-12-31'}, coid = pool ,opts = {'columns':['coid','mdate','r404' , 'no' , 'key3']}, chinese_column_name = True,paginate = True)
data_r404 = data_r404[(data_r404['序號'] == '001') & (data_r404['期間別'] == 'Q')]
pivot_data_r404 = data_r404.pivot(index='年/月', columns='公司', values='稅前淨利成長率')
# 確保 index 是 datetime 格式
pivot_data_r404.index = pd.to_datetime(pivot_data_r404.index)
pivot_data_r404 = pivot_data_r404.sort_index()
# 滾動12筆平均
rolling_mean = pivot_data_r404.rolling(window=12, min_periods=12).mean()
# 只保留每年 12 月 1 日
annual_rolling_mean = rolling_mean[rolling_mean.index.strftime('%m-%d') == '12-01']
# 刪除 2015 和 2016 年的 row(只保留 2017-12-01 起的)
annual_rolling_mean = annual_rolling_mean[annual_rolling_mean.index.year >= 2017]
annual_rolling_mean = annual_rolling_mean.dropna(axis=1)
接著透過 TejToolAPI 將其餘資料也一併抓齊,接著就能將資料作合併
columns = ['近12月累計營收_千元', 'Outstanding_Shares_1000_Shares', '股東權益總計', '每股淨值' , '收盤價' , '調整係數']
start_dt = pd.Timestamp('2015-01-01', tz = 'UTC')
end_dt = pd.Timestamp('2024-12-31', tz = "UTC")
data = TejToolAPI.get_history_data(start = start_dt,
end = end_dt,
ticker = pool,
fin_type = ['A' , 'Q' , 'TTM'],
columns = columns,
transfer_to_chinese = True)
# 將 pivot table 攤平為 long format
rolling_long = annual_rolling_mean.copy()
rolling_long = rolling_long.stack().reset_index()
# 重命名欄位
rolling_long.columns = ["年/月", "股票代碼", "過去3年平均稅前盈餘成長率"]
# 建立 year 欄
rolling_long["year"] = rolling_long["年/月"].dt.year
rolling_long = rolling_long.drop(columns=["年/月"]) # 如果不需要年/月就刪掉
# 先從 data 中取出年份
data["year"] = pd.to_datetime(data["日期"]).dt.year
# 合併:依據 股票代碼 和 年份
merged_data = pd.merge(data, rolling_long, how="left", on=["股票代碼", "year"])
有了merged_data就能計算下跌風險值以及偏離值
data = merged_data
data['日期'] = pd.to_datetime(data['日期']) # 確保日期格式正確
data['月份'] = data['日期'].dt.to_period('M') # 轉換成月份 (YYYY-MM)
data['每股營業額'] = data['近12月累計營收_千元'] / data['流通在外股數_千股']#A
data['每股帳面價值'] = data['股東權益總計_Q'] / data['流通在外股數_千股']#B
data['年度'] = data['日期'].dt.year
# 取平均,確保三者都是平等的權重
#C已經完成
data['過去4季每股盈餘'] = data['每股淨值_TTM']#D
# 計算 C × D
data['C_D'] = data['過去3年平均稅前盈餘成長率'] * data['過去4季每股盈餘']
# 若 C × D 為負數,則改為 0
data.loc[data['C_D'] < 0, 'C_D'] = 0
# 計算 E(下跌風險值)
data['下跌風險值'] = (data['每股營業額'] + data['每股帳面價值'] * 1.5 + data['C_D'] * (1/3)) / 3
# 刪除不必要的中間變數
data.drop(columns=['C_D'], inplace=True)
data['偏離值'] = (data['收盤價'] * data['調整係數'] - data['下跌風險值']) / (data['收盤價'] * data['調整係數'])
經過一系列的計算後我們得到偏離值,接著就能把資料匯入,詳細程式碼可以參考相關連結
這段程式碼的架構是透過 Zipline 的 Pipeline 系統,自訂一個名為 Bias_Value 的資料欄位(CustomDataset),將事先處理好的偏離值資料載入後,建立一個選股策略(Pipeline),挑選偏離值為負且最小的前 10 檔股票作為多頭標的,最後透過 SimplePipelineEngine 執行整體流程,回傳指定期間內的選股結果。
from zipline.pipeline.data.dataset import Column, DataSet
from zipline.pipeline.loaders.frame import DataFrameLoader
transform_data = data5.unstack('SID')
transform_data
# 確保索引為 UTC
fixed_transform_data = transform_data.copy()
# 如果索引已經有時區,則用 tz_convert 轉換
if fixed_transform_data.index.tz is not None:
fixed_transform_data.index = fixed_transform_data.index.tz_convert('UTC')
else:
fixed_transform_data.index = fixed_transform_data.index.tz_localize('UTC')
class CustomDataset(DataSet):
Bias_Value = Column(dtype=float)
domain = TW_EQUITIES
# 建立 DataFrameLoader
Custom_loader = {
CustomDataset.Bias_Value: DataFrameLoader(CustomDataset.Bias_Value, fixed_transform_data['偏離值'])
}
from zipline.pipeline.data import EquityPricing
def choose_loader(column):
if column.name in EquityPricing._column_names:
return pricing_loader
elif column.name in CustomDataset._column_names:
return Custom_loader[column]
else:
raise Exception('Column not available')
engine = SimplePipelineEngine(get_loader = choose_loader,
asset_finder = bundle.asset_finder,
default_domain = TW_EQUITIES)
from zipline.pipeline import Pipeline
def compute_signals_debug():
bias = CustomDataset.Bias_Value.latest
return Pipeline(columns={'偏離值(G)': bias})
pipeline_debug = engine.run_pipeline(compute_signals_debug(), start_dt, end_dt)
# 篩選出 `偏離值(G)` 不是 NaN 的行
valid_pipeline_debug = pipeline_debug[pipeline_debug['偏離值(G)'].notna()]
def compute_signals():
# **篩選出負的偏離值**
signals = CustomDataset.Bias_Value.latest
negative_bias_filter = signals < 0 # 只選偏離值為負的
# **選擇最負的前 40 檔**
longs = signals.bottom(40, mask=negative_bias_filter) # 取最小的 40 檔(偏離值最負)
return Pipeline(columns={
'signals': signals, # 直接存偏離值
'longs': longs # 選最負的前 40 檔作為買進標的
})
pipeline_result = engine.run_pipeline(compute_signals(), start_dt, end_dt)
initialize() 函式用於定義交易開始前的每日交易環境,與此例中我們設置:
def initialize(context):
"""
Called once at the start of the algorithm.
"""
context.universe = assets
context.tradeday = tradeday
context.set_benchmark(symbol('IR0001'))
context.longs = []
context.shorts = []
# 交易成本
#set_commission(commission.PerDollar(cost=commission_cost))
set_commission(commission.Custom_TW_Commission())
set_slippage(slippage.TW_Slippage( spread = 1.0,volume_limit=0.8))
# schedule_function
schedule_function(func=rebalance,
date_rule=date_rules.every_day(),
time_rule=time_rules.market_open)
schedule_function(func=record_vars,
date_rule=date_rules.every_day(),
time_rule=time_rules.market_close)
pipeline = compute_signals()
attach_pipeline(pipeline, 'signals')
這段程式碼是 Zipline 策略中的再平衡函數,功能如下:
在指定交易日內執行,取消所有未成交訂單,根據 context.trades 中訊號為 1 的股票作為做多標的。這些股票會等資金分配。同時,賣出不再符合條件的持股,對於新選及續抱的股票則下單調整到新目標權重,完成投資組合的動態調整。
from collections import defaultdict
def rebalance(context, data):
"""
1. 只在 context.tradeday 裡的日期執行
2. 取消所有未成交訂單
3. 從 context.trades 取出 long_candidates(signal == 1)
4. 用偏離值絕對值計算每檔股票的新目標權重
5. 賣掉「失選」的(signal != 1 & 目前持有)
6. 對新進 + 重疊的,每檔都 order_target_percent 到它的新目標權重
"""
today = get_datetime().strftime('%Y-%m-%d')
if today not in context.tradeday:
return
# 2. 取消所有未成交訂單
for asset, orders in get_open_orders().items():
for o in orders:
cancel_order(o)
# 3. 這期要做多的股票
long_candidates = [
stock for stock, signal in context.trades.items()
if signal == 1
]
# 沒有候選股,就全部清空
if not long_candidates:
for pos in context.portfolio.positions.values():
if pos.amount > 0:
order_target_percent(pos.asset, 0)
return
# 4. 計算偏離值絕對值權重
abs_signal = context.output.loc[long_candidates, 'signals'].abs()
total_bias = abs_signal.sum()
target_weights = {
stock: (1 / len(long_candidates))
for stock in long_candidates
}
# 5. 現有持股
held = [
pos.asset for pos in context.portfolio.positions.values()
if pos.amount > 0
]
# 只賣掉「失選」的
dropouts = set(held) - set(long_candidates)
for stock in dropouts:
order_target_percent(stock, 0)
# 6. 新進 + 重疊 的都調整到新目標權重
# order_target_percent 會自動「加減部位到達目標比例」
for stock, w in target_weights.items():
order_target_percent(stock, w)
使用 run_algorithm() 來執行上述設定的動能策略,資料集使用 tquant,初始資金設定為 1,000,000 元。執行過程中,輸出的 results 包含每日績效和交易明細。
在進行繪圖時,為了避免字體錯誤,先進行字體設定:
from zipline import run_algorithm
from zipline.utils.calendar_utils import get_calendar
capital_base = 1e6
calendar_name = 'TEJ'
start_dt = pd.Timestamp(start, tz = 'UTC')
end_dt = pd.Timestamp(end, tz = "UTC")
# Running a Backtest
results = run_algorithm(start=start_dt,
end=end_dt,
initialize=initialize,
before_trading_start=before_trading_start,
capital_base=capital_base,
data_frequency='daily',
analyze=analyze,
bundle=bundle_name,
trading_calendar=get_calendar(calendar_name),
custom_loader=Custom_loader)import pyfolio as pf
from pyfolio.utils import extract_rets_pos_txn_from_zipline
from pyfolio.plotting import (plot_perf_stats,
show_perf_stats,
plot_rolling_beta,
plot_rolling_returns,
plot_rolling_sharpe,
plot_drawdown_periods,
plot_drawdown_underwater)
from pyfolio.tears import *
from pyfolio.timeseries import (perf_stats,
extract_interesting_date_ranges,
sharpe_ratio,
sortino_ratio)
import empyrical
returns, positions, transactions = pf.utils.extract_rets_pos_txn_from_zipline(results)
pf.tears.create_full_tear_sheet(returns,
positions=positions,
benchmark_rets=results['benchmark_return'],
transactions=transactions)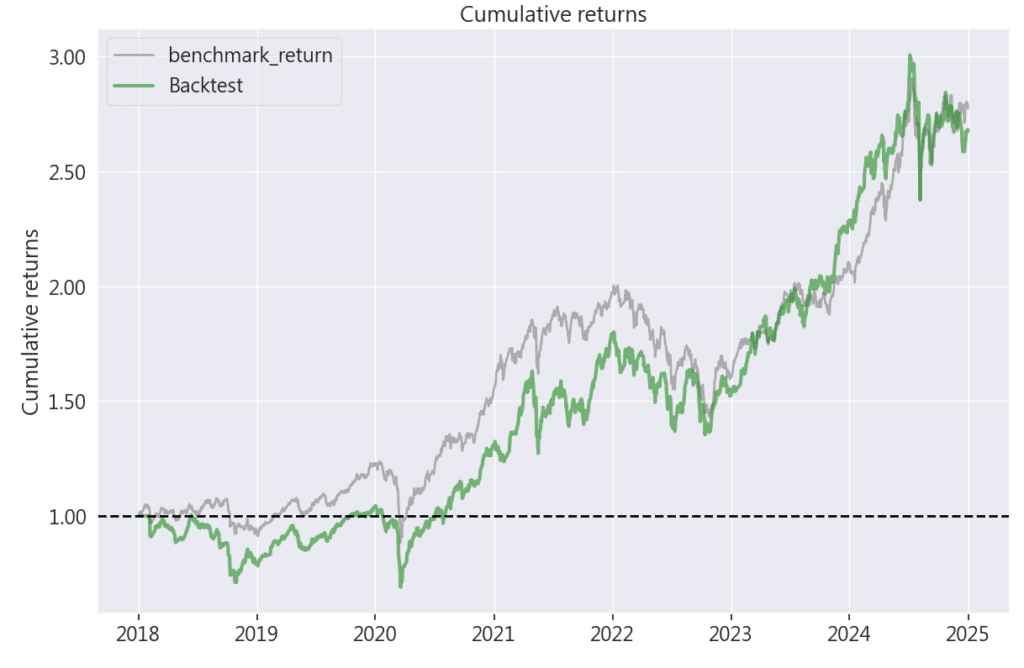
| 績效指標 / 策略 | 大盤(Benchmark) | 麥克莫非投資策略 |
| 年化報酬率 | 16.275% | 15.767% |
| 累積報酬率 | 177.386% | 169.287% |
| 年化波動度 | 17.279% | 19.856% |
| 夏普值 | 0.96 | 0.84 |
| 卡瑪比率 | 0.57 | 0.45 |
| 期間最大回撤 | -28.553% | -35.045% |
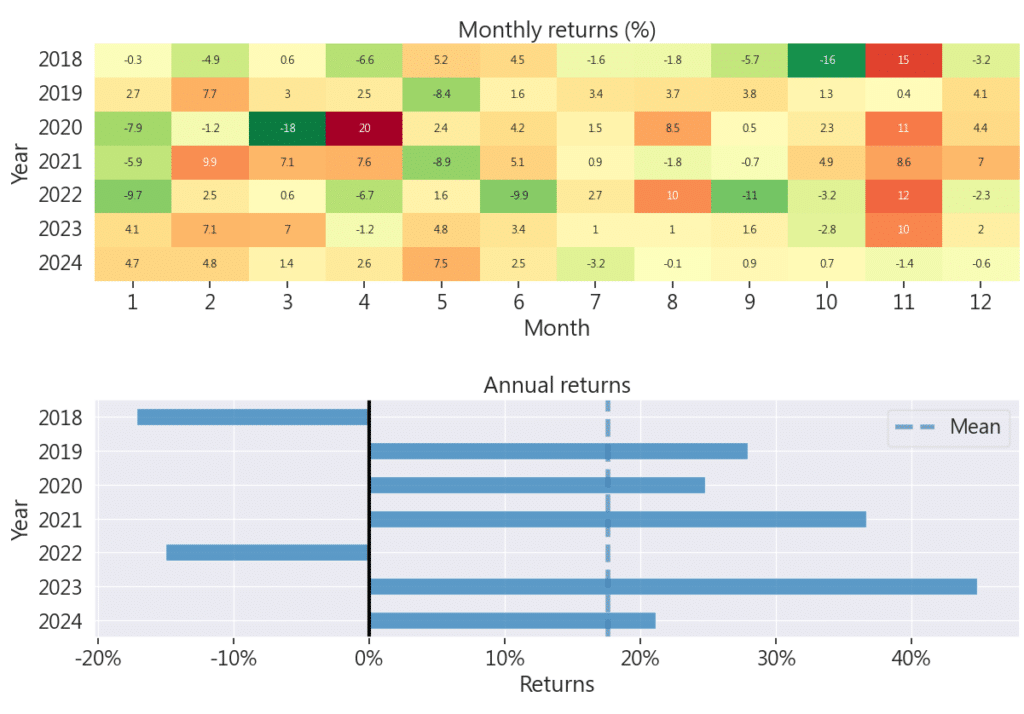
從年化報酬圖顯示策略在多數年度均有不錯表現,尤其在 2023 年年報酬超過 40%,顯示策略在特定市場環境下具備強勁的獲利能力;雖然 2018 與 2022 年出現負報酬,這部分可以視情況設定止盈止損。
本策略聚焦於高科技產業,從中篩選出偏離值最小的前 40 檔個股,偏離值越低代表該股票與基準價格的落差越小,反映其價格相對穩定、下跌風險較低。科技業雖具有高成長潛力,但波動性大、風險高,因此透過此策略能有效辨識出在高風險環境中相對穩健的投資標的。從回測結果來看,策略報酬接近市場,還展現出良好的風險控制能力,但是相對也因為風險的降低,篩選掉了一些飆股的可能性,導致有時大盤在漲反而此策略的選股沒有明顯向上趨勢。
歡迎投資朋友參考,之後也會持續介紹TEJ資料庫來建構各式指標,並回測指標績效,所以歡迎對各種交易回測有興趣的讀者,選購TQuant Lab的相關方案,用高品質的資料庫,建構出適合自己的交易策略。
溫馨提醒,本次分析僅供參考,不代表任何商品或投資上建議。
