使用LSTM深度學習模型優化交易訊號,並進行歷史回測

Table of Contents
文章難度:★★★☆☆
閱讀建議:本文使用RNN架構進行時間序列預測,需要對時間序列或是深度學習有基礎瞭解,可以參考前篇LSTM預測股價的文章【資料科學】LSTM,有助於對本文有更深入的了解。
上篇我們選用了 LSTM 模型來進行股價走勢的預測,使用前10天的開盤價、最高價、最低價、收盤價、成交量,預測隔天的收盤價,發現模型表現不是很好,僅僅以昨天的股價來對明天股價進行預測,因此我們更改個做法,想藉由模型來幫我們判斷賣賣點,進行交易策略。這次我們更增加了更多特徵指標,希望能有更好的結果。
我們新增了八種特徵指標,四種為技術指標,四種為總經指標,希望能用這兩個面向的特徵值提升我們的預測結果。
技術指標:
KD:隨機指標,表示目前價格相對過去一段期間的高低變化。
RSI:股價強弱指標,表示買賣盤雙方力道的強弱。
MACD:長期與短期移動平均線收斂或發散指標。
MOM:主要是用來觀察價格走勢的變化幅度,以及行情的趨動方向。總經指標:
台灣景氣對策信號:代表經濟活動且能反映景氣變化的重要總體經濟變數。
VIX指數:表示市場波動度外,也是市場情緒恐慌指標。
領先指標:提前反應景氣的經濟指標,用來預測未來景氣走向。
台股平均本益比:以上市公司取平均,可看出整體投資人對整個市場的看法是樂觀還是悲觀。
本文使用Windows OS並以Jupyter作為編輯器
import tejapi
import pandas as pd
tejapi.ApiConfig.api_key = "Your Key"
tejapi.ApiConfig.ignoretz = True
0050調整股價(日) — 除權息調整(TWN/APRCD1)
台股平均本益比 — 總體經濟(GLOBAL/ANMAR)
台灣景氣對策訊號– 總體經濟(GLOBAL/ANMAR)
領先指標 — 總體經濟(GLOBAL/ANMAR)
芝加哥VIX指數 — 國際股價指數(GLOBAL/GIDX)
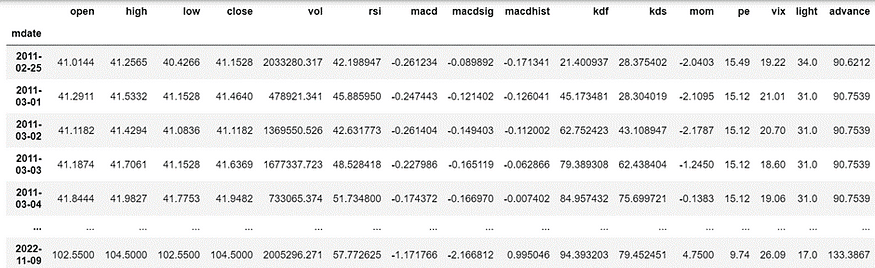
0050除權息調整股價與其開盤價、收盤價、最高價、最低價、成交量,資料期間2011年1月至2022年11月。
coid = "0050"
mdate = {'gte':'2011-01-01', 'lte':'2022-11-15'}
data = tejapi.get('TWN/APRCD1',
coid = coid,
mdate = {'gte':'2011-01-01', 'lte':'2022-11-15'},
paginate=True)
#開高低收、成交量
data = data[["coid","mdate","open_adj","high_adj","low_adj","close_adj","amount"]]
data = data.rename(columns={"coid":"coid","mdate":"mdate","open_adj":"open",
"high_adj":"high","low_adj":"low","close_adj":"close","amount":"vol"})
技術指標(KD、RSI、MACD、MOM)
from talib import abstract
data["rsi"] = abstract.RSI(data,timeperiod=14)
data[["macd","macdsig","macdhist"]] = abstract.MACD(data)
data[["kdf","kds"]] = abstract.STOCH(data)
data["mom"] = abstract.MOM(data,timeperiod=15)
data.set_index(data["mdate"],inplace = True)
總經指標(台股平均本益比、台灣景氣對策訊號、領先指標、芝加哥VIX指數)
data1 = tejapi.get('GLOBAL/ANMAR',
mdate = mdate,
coid = "SA15",
paginate=True)
data1.set_index(data1["mdate"],inplace = True)
data1 = data1.resample('D').ffill()
data = pd.merge(data,data1["val"],how='left', left_index=True, right_index=True)
data.rename({"val":"pe"}, axis=1, inplace=True)
#芝加哥VIX指數
data2 = tejapi.get('GLOBAL/GIDX',
coid = "SB82",
mdate = mdate,
paginate=True)
data2.set_index(data2["mdate"],inplace = True)
data = pd.merge(data,data2["val"],how='left', left_index=True, right_index=True)
data.rename({"val":"vix"}, axis=1, inplace=True)
#景氣對策訊號
data3 = tejapi.get('GLOBAL/ANMAR',
coid = "EA1101",
mdate = mdate,
paginate=True)
data3.set_index(data3["mdate"],inplace = True)
data3 = data3.resample('D').ffill()
data = pd.merge(data,data3["val"],how='left', left_index=True, right_index=True)
data.rename({"val":"light"}, axis=1, inplace=True)
#領先指標
data4 = tejapi.get('GLOBAL/ANMAR',
coid = "EB0101",
mdate = mdate,
paginate=True)
data4.set_index(data4["mdate"],inplace = True)
data4 = data4.resample('D').ffill()
data = pd.merge(data,data4["val"],how='left', left_index=True, right_index=True)
data.rename({"val":"advance"}, axis=1, inplace=True)
刪除空值與無用欄位
data.set_index(data["mdate"],inplace=True)
data = data.fillna(method="pad",axis=0)
data = data.dropna(axis=0)
del data["coid"]
del data["mdate"]
data
我們選用移動平均結合動能指標來定義趨勢,簡單運用MA10 > MA20 且 RSI10 >RSI 20時,判斷為上升趨勢。
data["short_mom"] = data["rsi"].rolling(window=10,min_periods=1,center=False).mean()
data["long_mom"] = data["rsi"].rolling(window=20,min_periods=1,center=False).mean()
data["short_mov"] = data["close"].rolling(window=10,min_periods=1,center=False).mean()
data["long_mov"] = data["close"].rolling(window=20,min_periods=1,center=False).mean()
標記Labels
上升趨勢標的為1,反之標記為0
import numpy as np
data['label'] = np.where(data.short_mov > data.long_mov, 1, 0)
data = data.drop(columns=["short_mov"])
data = data.drop(columns=["long_mov"])
data = data.drop(columns=["short_mom"])
data = data.drop(columns=["long_mom"])
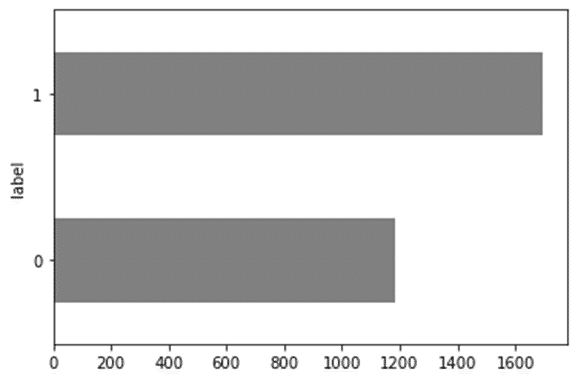
觀察資料分佈情形
可見資料分布不無過度不均,但由於大盤整體趨勢向上,上升趨勢較多為正常現象。
資料標準化
X = data.drop('label', axis = 1)
from sklearn.preprocessing import StandardScaler
X[X.columns] = StandardScaler().fit_transform(X[X.columns])
y = pd.DataFrame({"label":data.label})
切割成學習樣本以及測試樣本,比例為7:3
訓練資料時間範圍為2011.02.25–2019.05.08
測試資料時間範圍為2019.05.09–2022.11.15
import numpy as np
split = int(len(data)*0.7)
train_X = X.iloc[:split,:].copy()
test_X = X.iloc[split:].copy()
train_y = y.iloc[:split,:].copy()
test_y = y.iloc[split:].copy()
X_train, y_train, X_test, y_test = np.array(train_X), np.array(train_y), np.array(test_X), np.array(test_y)
將資料維度改成三維符合接下來模型所需
X_train = np.reshape(X_train, (X_train.shape[0],1,16))
y_train = np.reshape(y_train, (y_train.shape[0],1,1))
X_test = np.reshape(X_test, (X_test.shape[0],1,16))
y_test = np.reshape(y_test, (X_test.shape[0],1,1))
加入模型
加入四層LSTM 層,並以 Dropout 防止過擬
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import BatchNormalization
regressor = Sequential()
regressor.add(LSTM(units = 32, return_sequences = True, input_shape = (X_train.shape[1], X_train.shape[2])))
regressor.add(BatchNormalization())
regressor.add(Dropout(0.35))
regressor.add(LSTM(units = 32, return_sequences = True))
regressor.add(Dropout(0.35))
regressor.add(LSTM(units = 32, return_sequences = True))
regressor.add(Dropout(0.35))
regressor.add(LSTM(units = 32))
regressor.add(Dropout(0.35))
regressor.add(Dense(units = 1,activation="sigmoid"))
regressor.compile(optimizer = 'adam', loss="binary_crossentropy",metrics=["accuracy"])
regressor.summary()


將epochs 設定為100次。
train_history = regressor.fit(X_train,y_train,
batch_size=200,
epochs=100,verbose=2,
validation_split=0.2)

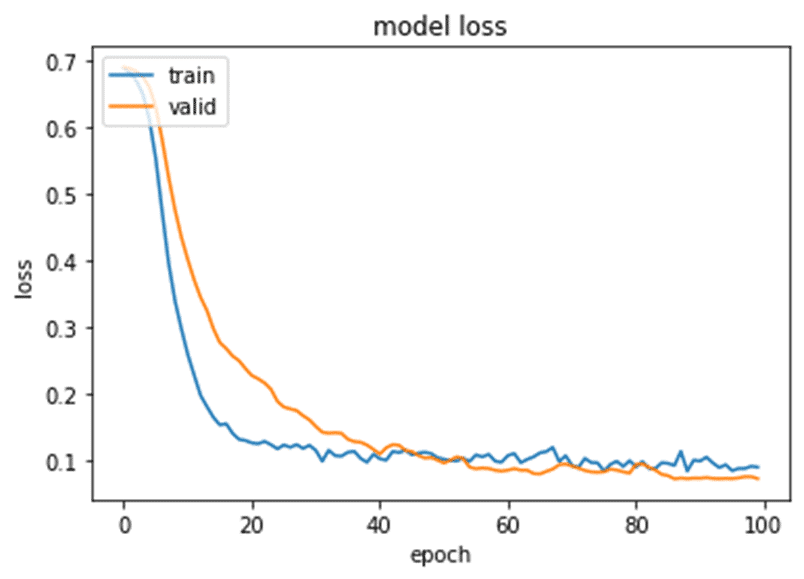
藉Model loss 圖可看出訓練過程中兩條線有收斂情形,顯示模型無過擬合。
import matplotlib.pyplot as plt
loss = train_history.history["loss"]
var_loss = train_history.history["val_loss"]
plt.plot(loss,label="loss")
plt.plot(var_loss,label="val_loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.title("model loss")
plt.legend(["train","valid"],loc = "upper left")
可看出不同特徵值的重要程度為何。顯示MACD、台股平均本益比及RSI為重要特徵值。
from tqdm.notebook import tqdm
results = []
print(' Computing LSTM feature importance...')
# COMPUTE BASELINE (NO SHUFFLE)
oof_preds = regressor.predict(X_test, verbose=0).squeeze()
baseline_mae = np.mean(np.abs(oof_preds-y_test))
results.append({'feature':'BASELINE','mae':baseline_mae})
for k in tqdm(range(len(list(test_X.columns)))):
# SHUFFLE FEATURE K
save_col = X_test[:,:,k].copy()
np.random.shuffle(X_test[:,:,k])
# COMPUTE OOF MAE WITH FEATURE K SHUFFLED
oof_preds = regressor.predict(X_test, verbose=0).squeeze()
mae = np.mean(np.abs( oof_preds-y_test ))
results.append({'feature':test_X.columns[k],'mae':mae})
X_test[:,:,k] = save_col

測試集準確率高達 95.49%,顯示LSTM 模型能不錯的執行我們的策略。
regressor.evaluate(X_test, y_test,verbose=1)
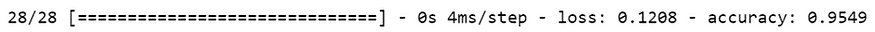
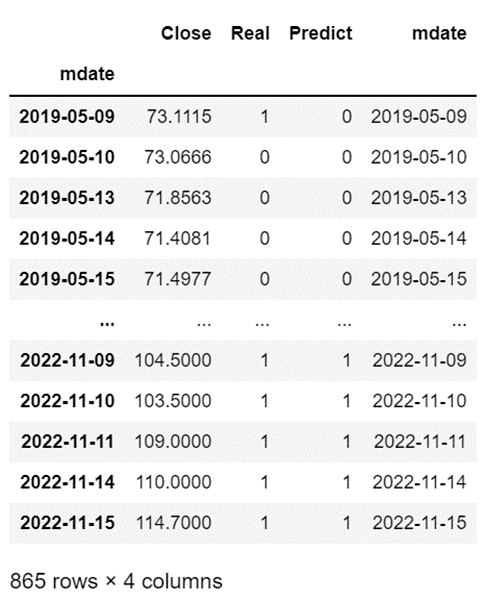
將真實 (Real) Label與模型預測 (Predict) Label進行對照
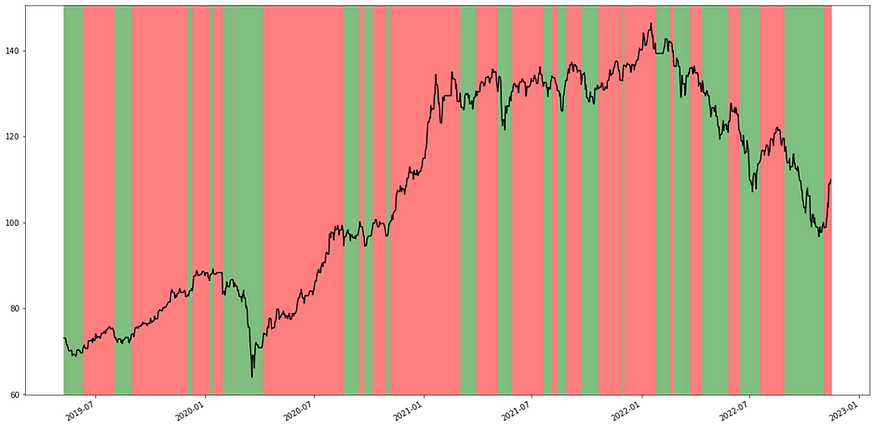
LSTM策略預測趨勢表示圖,紅色代表上升趨勢,綠色代表下降趨勢。
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import datetime as dt
df = result.copy()
df = df.resample('D').ffill()
t = mdates.drange(df.index[0], df.index[-1], dt.timedelta(hours = 24))
y = np.array(df.Close[:-1])
fig, ax = plt.subplots()
ax.plot_date(t, y, 'b-', color = 'black')
for i in range(len(df)):
if df.Predict[i] == 1:
ax.axvspan(
mdates.datestr2num(df.index[i].strftime('%Y-%m-%d')) - 0.5,
mdates.datestr2num(df.index[i].strftime('%Y-%m-%d')) + 0.5,
facecolor = 'red', edgecolor = 'none', alpha = 0.5
)
else:
ax.axvspan(
mdates.datestr2num(df.index[i].strftime('%Y-%m-%d')) - 0.5,
mdates.datestr2num(df.index[i].strftime('%Y-%m-%d')) + 0.5,
facecolor = 'green', edgecolor = 'none', alpha = 0.5
)
fig.autofmt_xdate()
fig.set_size_inches(20,10.5)
當趨勢訊號為上升時買入一部位並持有,當趨勢訊號為下降時賣出原部位,並反手做空一部位並持有,直到下次訊號為上升趨勢時平倉。
*註:本策略不考慮手續費,且均為全部資金進場與出場。
test_data = data.iloc[split:].copy()
backtest = pd.DataFrame(index=result.index)
backtest["r_signal"] = list(test_data["label"])
backtest["p_signal"] = list(result["Predict"])
backtest["m_return"] = list(test_data["close"].pct_change())
backtest["r_signal"] = backtest["r_signal"].replace(0,-1)
backtest["p_signal"] = backtest["p_signal"].replace(0,-1)
backtest["a_return"] = backtest["m_return"]*backtest["r_signal"].shift(1)
backtest["s_return"] = backtest["m_return"]*backtest["p_signal"].shift(1)
backtest[["m_return","s_return","a_return"]].cumsum().hist()
backtest[["m_return","s_return","a_return"]].cumsum().plot()

LSTM 策略累積報酬為82.6%
實際策略(MA+MOM)累積報酬為71.3%
大盤Buy and Hold累積報酬為52%
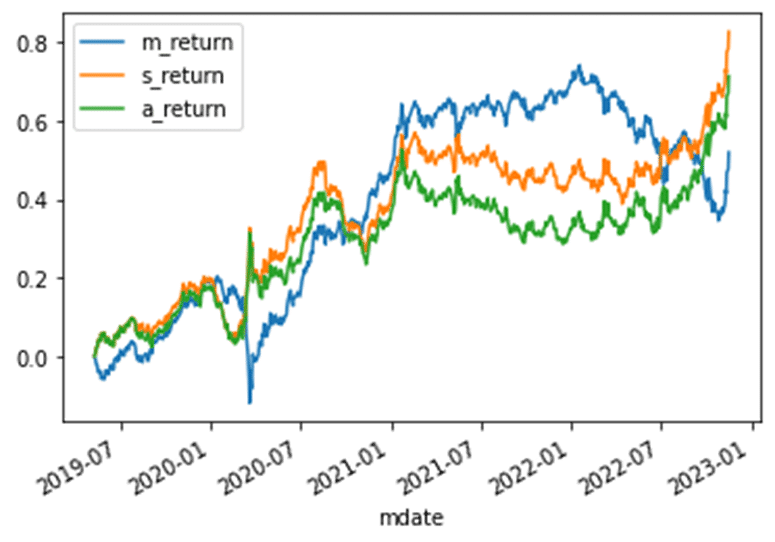
此次主要的重點在於 LSTM 是否可以依照我們設定的原策略,正確的判斷出買賣點。結果是肯定的,並擁有 95.49% 的高準確率,回測結果累積報酬 82.6% 甚至是贏過原策略並顯著打敗大盤的52%,我們認為打敗原策略的原因在於在盤整期間 LSTM 產生了較少的交易訊號,避免了原策略盤整期間容易上下刷洗,導致交易績效下降的情形。
最後,還是要再次提醒本文所提及之標的僅供說明使用,不代表任何金融商品之推薦或建議。因此,若讀者對於建置策略、績效回測、研究實證等相關議題有興趣,歡迎選購 TEJ E Shop中的方案,具有齊全的資料庫,就能輕易的完成各種檢定。
