
Table of Contents
上一篇講解了如何創立新環境並安裝模組 XGBoost,環境的設定是基礎,一開始出問題的話,後面會有許多奇奇怪怪的 Error,如果還沒看過上一篇的話,可以點這這裡,這一篇我們要對資料做一些處理,完成後再帶入模型裡讓機器去學習,學習後可以去預測未來的報酬,也可以看哪一個因子對預測是最有效果的!
本文使用 Mac OS 並以 Jupyter Notebook 作為編輯器
# basic import numpy as np import pandas as pd
# graphy import matplotlib.pyplot as plt %matplotlib inline
# machine learning from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split import xgboost as xgb
# TEJ import tejapi tejapi.ApiConfig.api_key = "Your Key" tejapi.ApiConfig.ignoretz = True
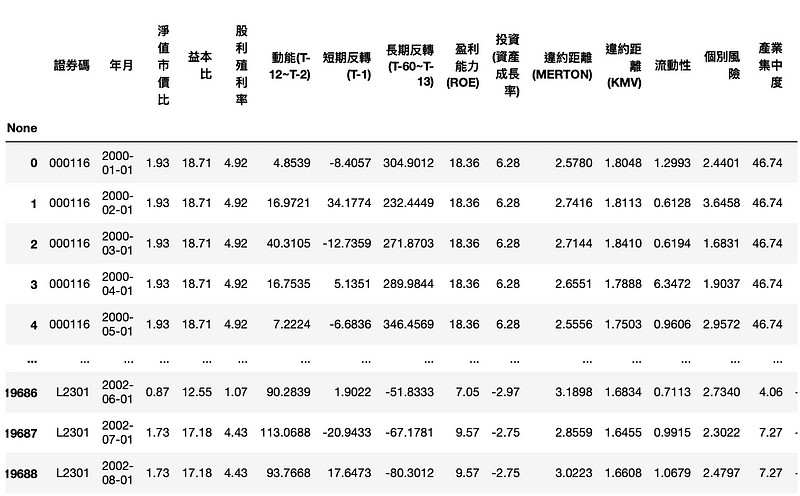
TWN/APRCM ,涵蓋2000年以來各學者衡量因子的指標,資料頻率為月資料TWN/APRCM ,以上市的證券及指數為收錄對象我們會使用 2000~2015的所有上市櫃公司的投資因子,用以預測2016~2017 月報酬率為正或是負。
df = tejapi.get('TWN/AFF_RAW',
mdate={'gte': '2000-01-01', 'lte':'2015-12-31'},
opts={'columns':['coid','mdate','pbr','per',
'div_yid','mom','str','ltr','profit','invest',
'dd_merton','dd_kmv','illiq','idiosyncratic',
'hhi','skew']},
chinese_column_name = True,
paginate = True)
df.isnull().sum(axis=0)

如果有缺失值,直接丟入模型的話,會導致無法計算,不過 XGBoost 模型能處理稀疏矩陣,可以容許有缺失值的存在,不過如果我們能合理的填補缺失值,這有助於我們增強模型的配適度,常見的方法為填補「平均值」、「中位數」,或是直接填上 0,使用的語法是 fillna ,至於要填入什麼的話,可以先對資料做一些 探索式資料分析(Exploratory Data Analysis,EDA),那這會是另一個重點,未來我們再另花篇幅去介紹!
# 處理時間 from datetime import date, timedelta import calendar
將月份都加上一個月
df['年月'] = df['年月'].apply(lambda x: x + timedelta(days=calendar.monthrange(x.year, x.month)[1]))
一般來說機器學習時,對資料做標準化,會提高模型的預測力,但在 XGBoost 卻不需要這一步,大略的解釋為:標準化是處理連續特徵,主要作用是進行數值縮放 ( 減去平均值、除以標準差 )。而數值縮放的目的是解決梯度下降時,等高線會是橢圓導致迭代次數增多的問題。但是上一篇提到 XGBoost是樹模型,是不能進行梯度下降的,因為樹模型是階越的,不可做導數。反而是透過尋找特徵的最優分裂點來完成優化的,由於標準化不會改變分裂點的位置,因此 XGBoost 不需要對資料進行標準化!
df_label = tejapi.get('TWN/APRCM',
mdate={'gte': '2000-01-01', 'lte':'2015-12-31'},
opts = {'columns':['coid','mdate','roi']},
chinese_column_name = True,
paginate = True)
如果是正報酬則設為 1,負報酬則為 0
df_label['報酬率%_月'] = df_label['報酬率%_月'].apply(lambda x: 1 if x>0 else 0)
df_label.rename(columns={'證券代碼':'證券碼'}, inplace=True)
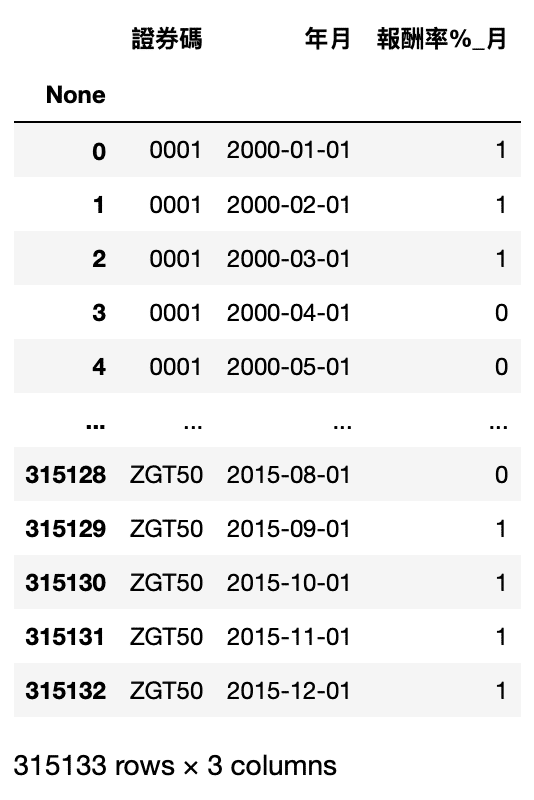
data = pd.merge(df , df_label, on=['證券碼', '年月'])
X, y = data.iloc[:,2:-1],data.iloc[:,-1]
通常在執行機器學習時,我們不會把所有資料都拿去做訓練,因為這樣做的話,我們很難判斷他的學習效果是好還是不好,因此我們會切一部分出來,以下我們拆成 8:2 ,20% 的資料作為模型後續的評估
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
from xgboost import XGBClassifier from sklearn.metrics import accuracy_score
將分類器命為 model,後面那串代表我們已經自行將標籤改成我們要的編碼
model = XGBClassifier(use_label_encoder=False)
開始訓練模型!
model.fit(X_train, y_train)
我們來檢視這模型在測試集的預測準確度
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
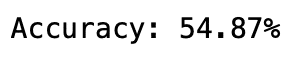
df_pred = tejapi.get('TWN/AFF_RAW',
coid = '2330',
mdate={'gte': '2015-12-01', 'lte':'2017-11-30'},
opts={'columns': 如文章第一段}
chinese_column_name = True,
paginate = True)
df_pred_label = tejapi.get('TWN/APRCM',
coid = comp,
mdate={'gte': '2016-01-01', 'lte':'2017-12-31'},
opts = {'columns':['mdate','roi']},
chinese_column_name = True,
paginate = True)
pred2 = model.predict(df_pred.iloc[:,2:]) df_pred_label['報酬率預測'] = pred2
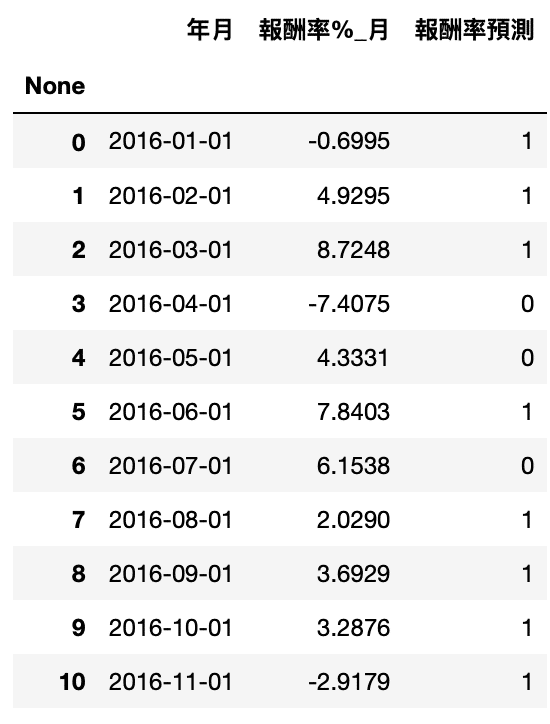
accuracy = accuracy_score(df_pred_label['報酬率%_月'].apply(lambda x: 1 if x>0 else 0), pred2)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
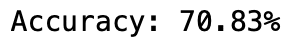
import matplotlib.pyplot as plt import matplotlib.font_manager plt.rcParams['font.sans-serif'] = 'Arial Unicode MS' plt.rcParams['axes.unicode_minus'] = False
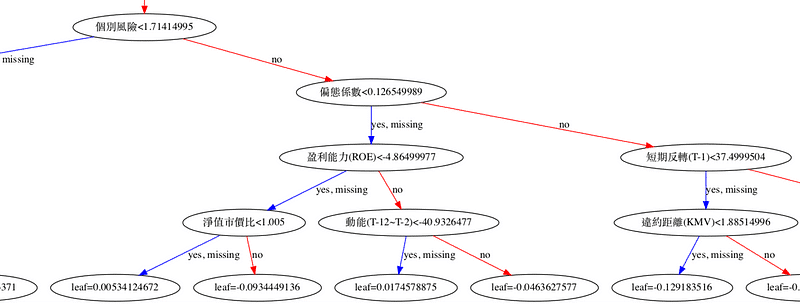
plt.figure(figsize=(30,10)) xgb.plot_tree(model,num_trees=0) plt.rcParams['figure.figsize'] = [1300, 1000] plt.show()
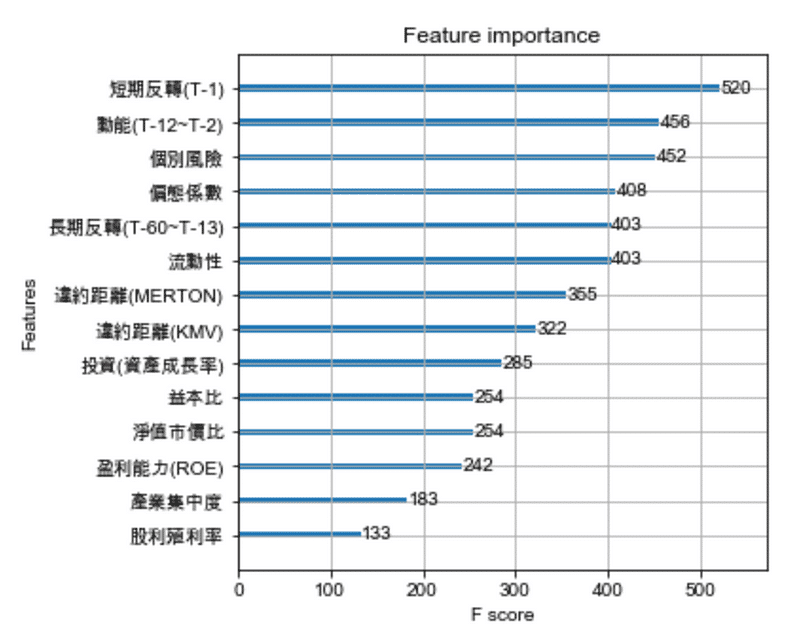
plt.figure(figsize=(10,40)) xgb.plot_importance(model) plt.rcParams['figure.figsize'] = [5, 5] plt.show()
今天的教學其實就是目前機器學習比賽常見的架構了,模型的開發其實都是很複雜的數學,而我們可以理解他的特質和性能來去使用它,並不用去深入了解他的數學計算,除非對這塊很有興趣,關於預測的準確度,其關鍵常在資料的前處理,包括遺失值、偏鋒態、共線性等數據處理,或是從相關論文發現可以組合出有效的特徵。
本篇因為 TEJ 已經整理好相關因子的數據,所以在前處理上相對輕鬆很多,但還是要強調一點是,由於金融上有非常多的不確定性,現在的準確度無法代表未來的準確度,但可以理解的一點是,這些因子都是目前金融正在尋找股價的特徵,不過現實生活有很多數據可以拿來玩,現在趕快把資料丟進 XGBoost 吧!
本文僅供參考之用,並不構成要約、招攬或邀請、誘使、任何不論種類或形式之申述或訂立任何建議及推薦,讀者務請運用個人獨立思考能力,自行作出投資決定,如因相關建議招致損失,概與作者無涉。
