Exploiting the Logit & Probit regression model to analyze the chances of a company’s bankruptcy.

Table of Contents
Predicting the future is what every investor wants to pursue, whether it is for the future market or the future of the companies and the industries. Still, there is always uncertainty and randomness in predicting the future, so we can only use the past historical data and existing company indicators to put it into statistics for verification. This article and the previous article [quantitative analysis (3)] predict the market?! The content might be similar. Still, the difference is that this article predicts the future of the companies and compares them with the three statistical methods.
Using different indicators, ROA, CR, DR, ATTNVR, CFAT, RSize, Sigma, ExRET, the verification found that some indicators had explanatory and incorporated regression models to explain the probability of crises.
The regression variables in this article refer to the relevant papers of the two authors
1. Altman z-score model (1968)
2. Shumway (2001)
This article uses Spyder as the editor
###Three Treasures of Quantify、Kit tools
import pandas as pd
import numpy as np
import tejapi
import statsmodels.formula.api as smf
import datetime as dt
from dateutil.relativedelta import *tejapi.ApiConfig.api_key = "YOUR_KEY"
tejapi.ApiConfig.ignoretz = True
###Ignores time zone in the time field
Company basic information details column description:
Targets: listed company, over-the-counter (OTC) company, emerging stock company, public company
The database code is (TWN/AIND), and its column is “Crisis Day, Crisis Event Category.”
df1 = tejapi.get('TWN/AIND',
chinese_column_name = True,
paginate = True,
opts={'columns':['coid','mdate', 'dflt_d','fail_fg']})
###use TEJ API to retrieve the required information
First of all, the obtained information is classified. The pre-listing companies are excluded since we measure the “probability of crisis event occurrence.” Hence, we define the crisis event situation as 1, and start processing the data. We should reset the event date to facilitate the subsequent merger with the financial report information.
df2 = df1[df1['危機事件類別'] != '']
#Filter out those with default eventsdf2['年/月'] = df2[['危機發生日']].applymap(lambda x: x.strftime('%Y-%m')).astype('datetime64')
#Change the date to the beginning of the month.df2['月'] = df2['年/月'].dt.month
#take out the monthdf2.reset_index(inplace = True)for i in range(len(df2.index)):
if df2['月'][i] == 1 or df2['月'][i] == 4 or df2['月'][i] == 7 or df2['月'][i] == 10:
df2['年/月'][i] = df2['年/月'][i]+ relativedelta(months = +2)
if df2['月'][i] == 2 or df2['月'][i] == 5 or df2['月'][i] == 8 or df2['月'][i] == 11:
df2['年/月'][i] = df2['年/月'][i]+ relativedelta(months = +1)#In order to match the financial report information later, we need to deal with the date first.df2['Y'] = 1 #Set all crisis event categories to 1
df2.rename(columns= {'公司簡稱':'公司'}, inplace=True)
Then fish out the open-ended data of the whole market ledger account and select the required variables (ledger accounts), including:
X1 = working capital(R678)/total asset (0010)
X2 = retained earnings (2341)/ total asset
X3 = EBIT (2402)/total asset
X4 = market value (MV)/ total debt (1000)
X5 = revenue/ total asset (R607)
X6 = ROA (R11V)
X7 = debt ratio (R505)
TEJ ledger account details and codes
Since the ratio of data retrieved at a time is limited ( paginate = True, up to 1 million fetches per salvage ), we need to fish in segments and merge them into the same Dataframe.
###Each Dataframe has about 300,000 data and so on.a1 = tejapi.get('TWN/AIFIN', #從TEJ api撈取所需要的資料
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2008-01-01', 'lt':'2011-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])a2 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2011-01-01', 'lt':'2014-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])a3 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2014-01-01', 'lt':'2017-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])a4 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2017-01-01', 'lt':'2020-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])a5 = tejapi.get('TWN/AIFIN',
chinese_column_name = True,
paginate = True,
mdate = {'gt':'2020-01-01'},
acc_code = ['R678', '0010','2341','2402','MV','1000', 'R607','R11V', 'R505'])###Consolidated data
acc = pd.concat([a1,a2,a3,a4,a5])
Converting the account values and putting them into colons is conducive to calculating the ledger accounts into the required variables. The calculation logic comes from the references and sets the company with no crisis after the merger to 0, and there is still a special value to be deleted.
acc1 = acc.pivot_table(values='數值', index=['公司','年/月'], columns='會計科目')
acc1['X1'] = (acc1['R678']/acc1['0010'])*100
acc1['X2'] = (acc1['2341']/acc1['0010'])*100
acc1['X3'] = (acc1['2402']/acc1['0010'])*100
acc1['X4'] = (acc1['MV']/acc1['1000'])*100
acc1 = acc1.rename(columns = {'R607':'X5', 'R11V':'X6', 'R505':'X7'})
acc2 = acc1[['X1','X2','X3','X4','X5','X6','X7']]acc2.reset_index(inplace=True)
df3 = pd.merge(acc2, df2[['公司','年/月','Y']], how='outer')
df3['Y'] = df3['Y'].replace(np.nan, 0)
#Set no crisis to 0df3 = df3.dropna()
df3['X4'] = df3['X4'].drop([59690,59688])
#remove the infinite valuedf3 = df3.rename(columns = {'狀況':'Y'})
Then bring in the variables to test their explanatory forces in three models, and we can find:
The variables X1 are not significant in the Logit model, while X2, 5, and 6 are significant in all three models, and the predicted results are intuitively consistent with us. Taking ROA as an example, the higher the ROA, the better the company’s ability to use assets to profit, and the lower the probability of failure, which is negative and in line with expectations.
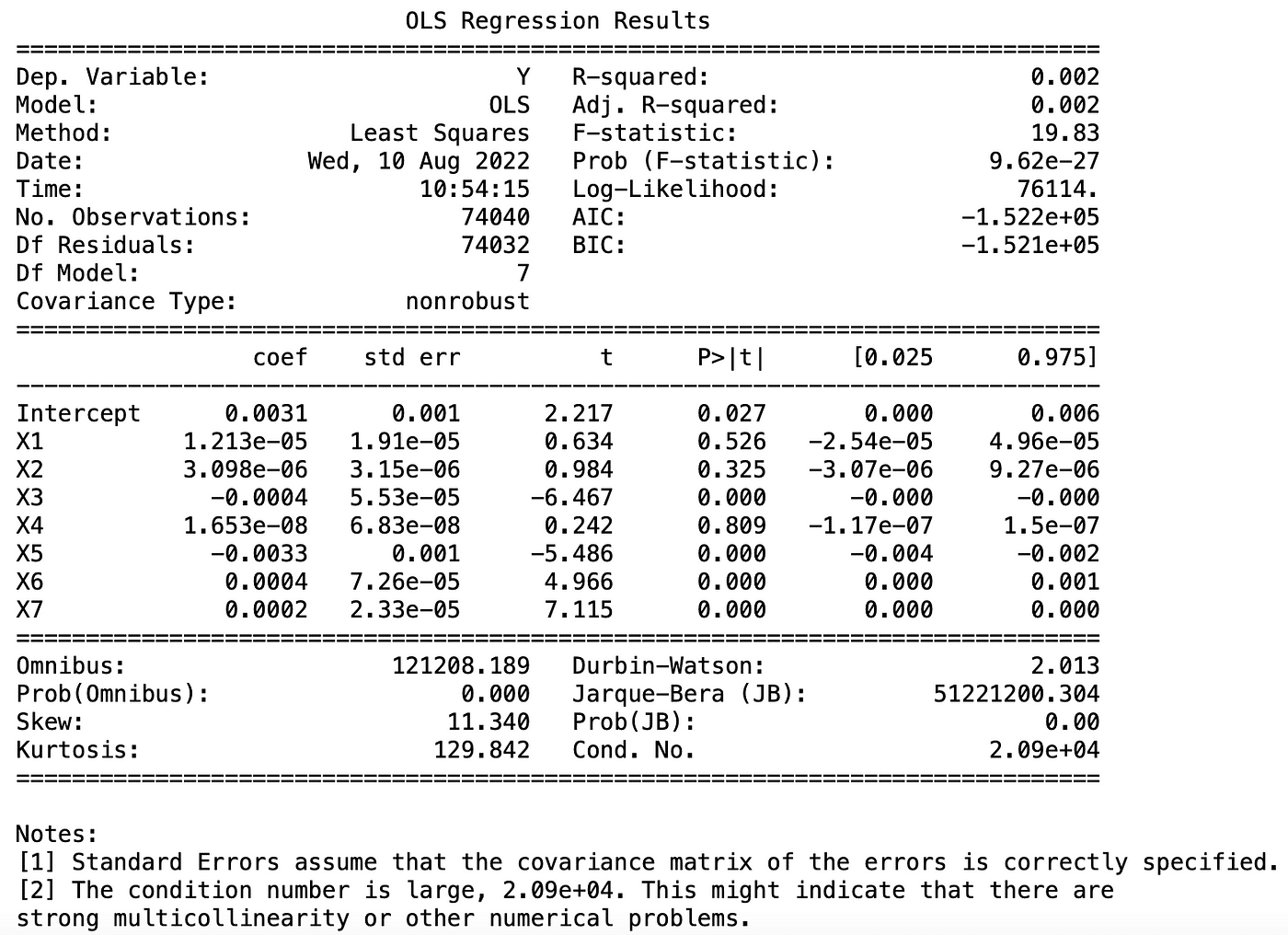
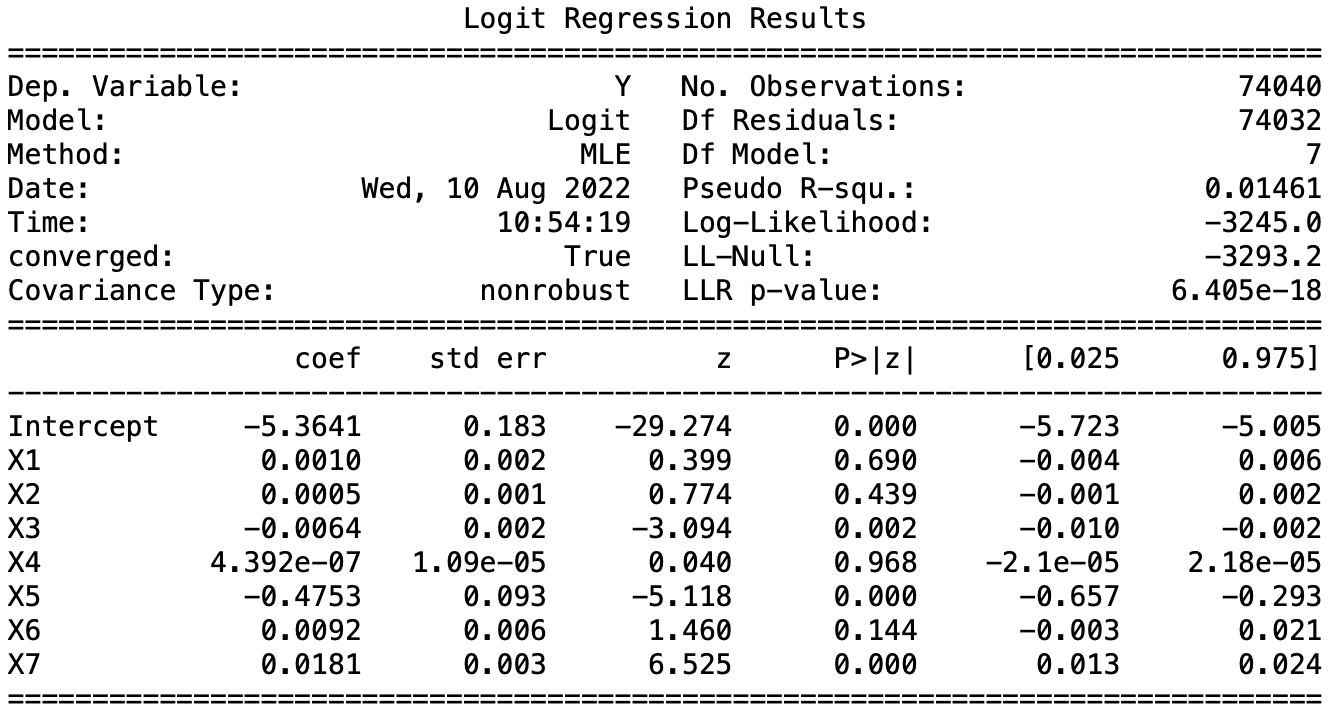
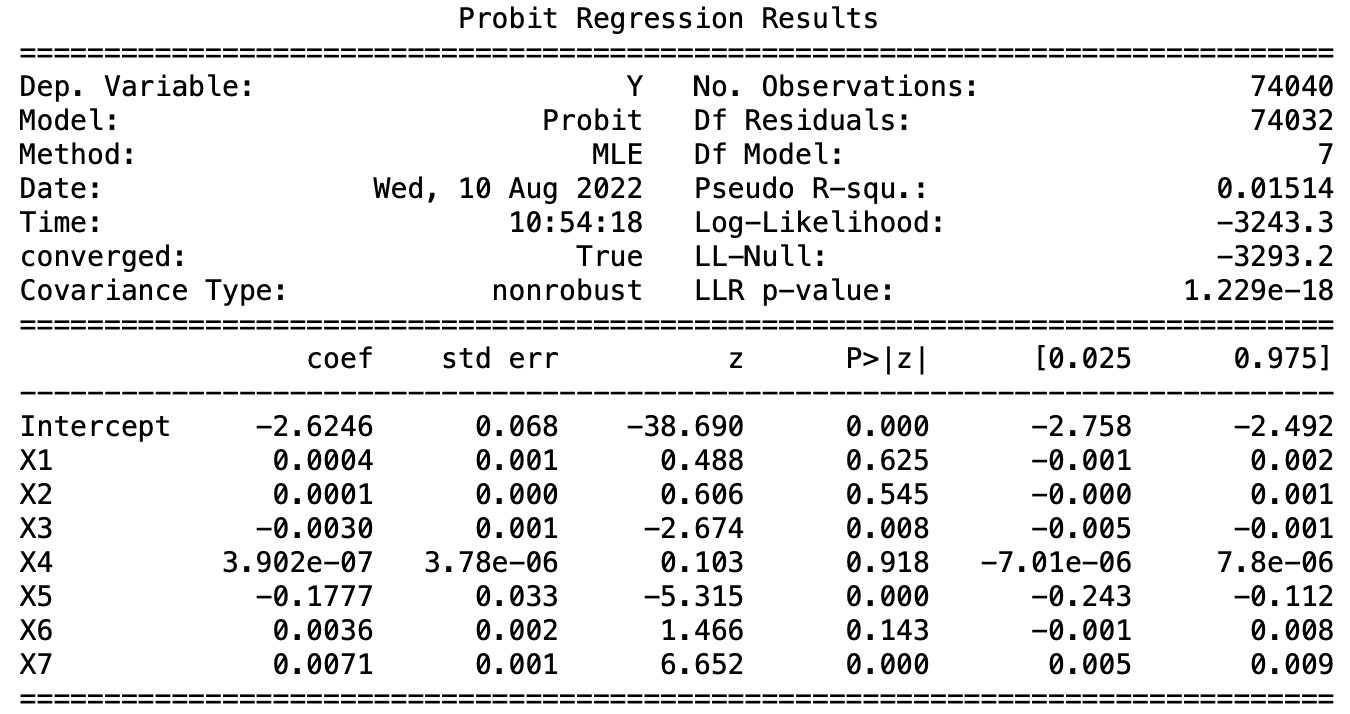
Then bringing the rapid performance data of individual companies into the regression model to obtain the probability of the company’s crisis, we listed 2330 TSMC, 2454 MediaTek, the next market 1592 Enterex KY, 2475 CPT.

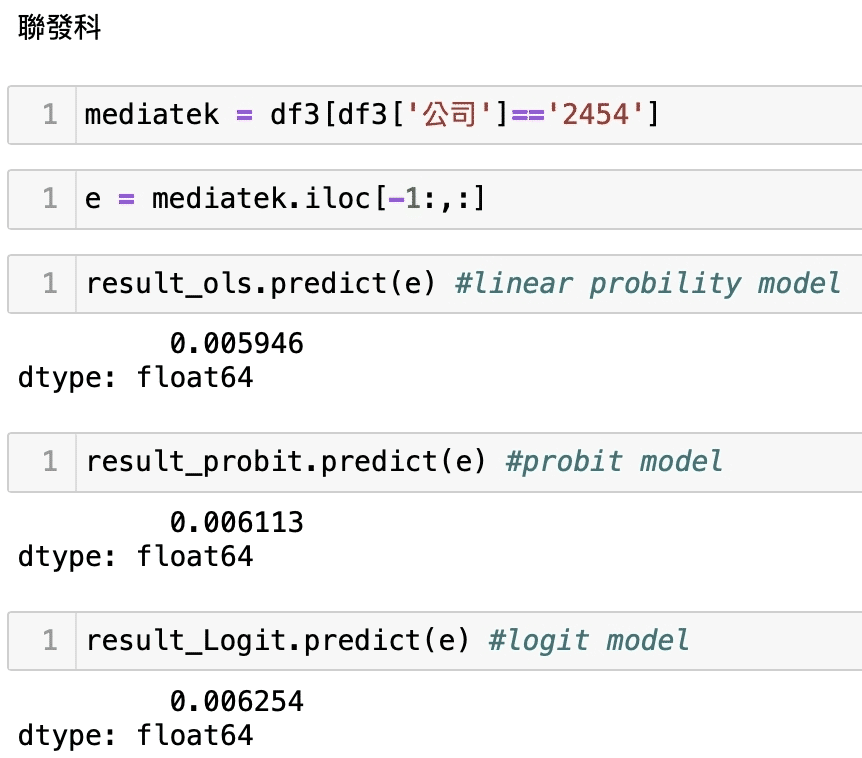
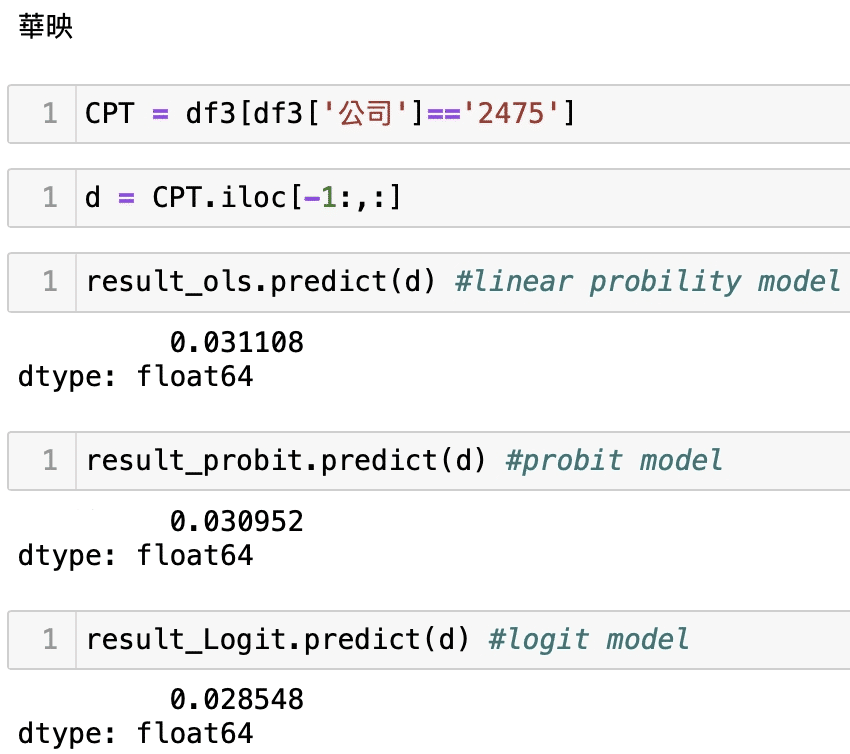
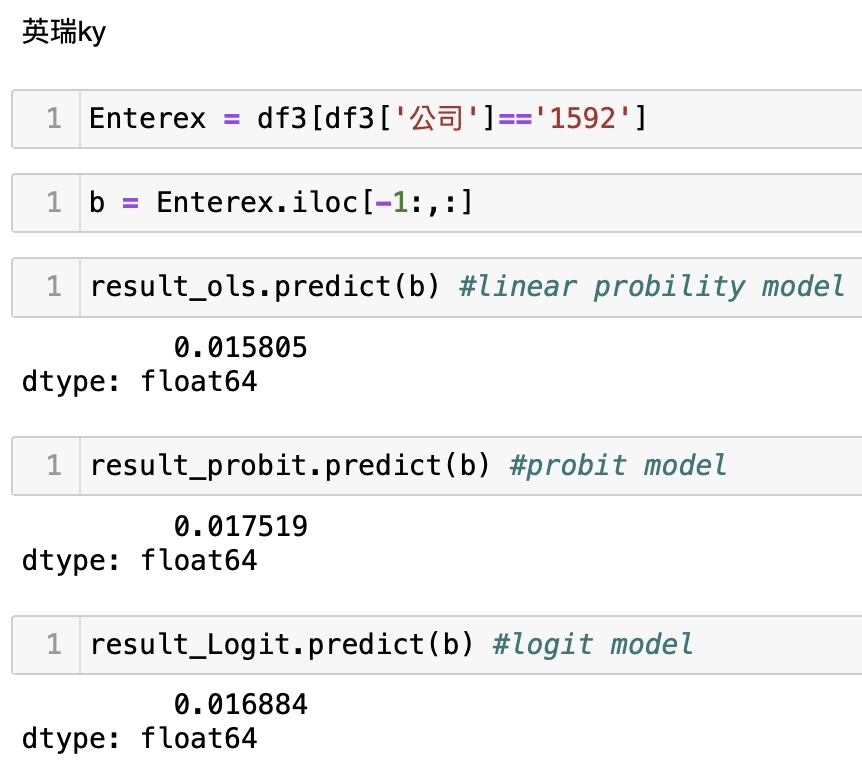
We can find that the crisis event of 2330 TSMC and 2454 MediaTek are extremely low. Assuming that he can be compared to see the LPM model (OLS), the crisis probability of 1592 Enterex KY and 2475 CPT are at least three times more than that of 2330 TSMC and 2454 MediaTek. Intuitively speaking, 2330 TSMC and 2454 MediaTek get better market value size; their company’s constitution must be better than other companies. This forecast does not represent absolute. We only use the relevant accounting data to show the state to make a regression verification but still have a certain reference and explanatory power, which also means there is uncertainty in the stock market. If there is a signal that seems to be a crisis, it should always be concerned and pay attention to the assessment of its own risk; therefore, welcome to continue to pay attention to this platform. We will have more articles to share with you later. In addition, all the readers and investors are welcome to buy the solution in the TEJ E Shop. Try to see the holdings in their hands and the possibility and comparison of the occurrence of the crisis. I believe the reader has a complete database so that you can grasp the stock market’s uncertainty.
