
Photo from Pexels by Markus Spiske
Table of Contents
在金融市場中,技術分析一直是投資人用來判斷市場趨勢與制定交易策略的重要指標。其中,一目均衡表(Ichimoku Kinko Hyo) 透過五條均線與雲層結構,分析股票的支撐、阻力與趨勢變化,幫助交易者快速辨識多空方向。然而,傳統的 Ichimoku 策略主要依賴固定參數(9-26-52)與視覺判讀,無法靈活適應不同市場環境,且在震盪行情中容易產生虛假信號,導致錯誤交易與資本回撤。
隨著機器學習技術的發展,XGBoost(Extreme Gradient Boosting)已經成為量化交易領域中最受歡迎的訓練模型之一。它透過梯度提升決策樹(GBDT)學習不同數據間的高維關係,並優化交易信號的篩選與決策邏輯。因此,相比於單純依賴技術指標,XGBoost 能綜合不同市場變數,如價格動能、成交量變化與市場情緒等,找出不同資料與未來股票報酬間的關聯度,從而提高交易策略的準確度與穩定性。
策略簡介
Ichimoku Cloud 是由日本記者(細田悟一)所發明,通過觀察下列五條線的線型變化,來進行投資策略的判斷:
def ichimoku_cloud(df):
high_9 = df['最高價'].rolling(window = 9).max()
low_9 = df['最低價'].rolling(window = 9).min()
df['Tenkan_sen'] = (high_9 + low_9) / 2
high_26 = df['最高價'].rolling(window = 26).max()
low_26 = df['最低價'].rolling(window = 26).min()
df['Kijun_sen'] = (high_26 + low_26) / 2
df['Senkou_Span_A'] = ((df['Tenkan_sen'] + df['Kijun_sen']) / 2).shift(26)
high_52 = df['最高價'].rolling(window = 52).max()
low_52 = df['最低價'].rolling(window = 52).min()
df['Senkou_Span_B'] = ((high_52 + low_52) / 2).shift(26)
df['Chikou_Span'] = df['收盤價'].shift(-26)
df['Cloud'] = np.where(
df['Senkou_Span_A'] < df['Senkou_Span_B'],
'red',
'green')
return df
# 先產生原始信號
conditions = [
(df['收盤價'] > df['Senkou_Span_B']) & (df['Cloud'] == 'red') & (df['Tenkan_sen'] > df['Kijun_sen'] * 0.01),
(df['收盤價'] < df['Senkou_Span_B']) & (df['Cloud'] == 'green') & (df['Tenkan_sen'] < df['Kijun_sen'] * 0.99)
]
choices = ['Buy', 'Sell']
df['RawSignal'] = np.select(conditions, choices, default=np.nan)
# 只保留信號變化的那一刻,連續相同的信號僅保留第一筆
df['Signal'] = df['RawSignal'].where(df['RawSignal'] != df['RawSignal'].shift())
df['Signal'] = np.where(df['Signal'].isin(['Buy', 'Sell']), df['Signal'], 'Hold')
df['Buy_Point'] = np.where(df['Signal'] == 'Buy', df['收盤價'], np.nan)
df['Sell_Point'] = np.where(df['Signal'] == 'Sell', df['收盤價'], np.nan)
tab10 = [
"#1f77b4", # C0 - 藍色
"#ff7f0e", # C1 - 橙色
"#2ca02c", # C2 - 綠色
"#d62728", # C3 - 紅色
"#9467bd", # C4 - 紫色
"#8c564b", # C5 - 棕色
"#e377c2", # C6 - 粉色
"#7f7f7f", # C7 - 灰色
"#bcbd22", # C8 - 黃綠色
"#17becf" # C9 - 青色
]
split_index = int(len(df) * 0.8)
data = df.iloc[split_index:].copy()
data = data.set_index('日期', drop = False)
plt.figure(figsize = (16,8))
plt.style.use("default")
plt.plot(data.index, data['收盤價'], color=tab10[0], label='Price')
plt.plot(data.index, data['Tenkan_sen'], color=tab10[1], label='Tenkan_sen')
plt.plot(data.index, data['Kijun_sen'], color=tab10[2], label='Kijun_sen')
plt.fill_between(data.index, data['Senkou_Span_A'], data['Senkou_Span_B'],
where=data['Senkou_Span_A'] >= data['Senkou_Span_B'],
facecolor='lightgreen', alpha=0.5, label='Bullish_Cloud')
plt.fill_between(data.index, data['Senkou_Span_A'], data['Senkou_Span_B'],
where=data['Senkou_Span_A'] < data['Senkou_Span_B'],
facecolor='lightcoral', alpha=0.5, label='Bearish_Cloud')
# 利用 scatter 畫出買入點 (用向上三角形表示)
plt.scatter(data.index, data['Buy_Point'], marker='^', color='green', s=50, label='Buy')
# 利用 scatter 畫出賣出點 (用向下三角形表示)
plt.scatter(data.index, data['Sell_Point'], marker='v', color='red', s=50, label='Sell')
plt.title(f'{pool}Ichimoku_Cloud')
plt.legend()
plt.show()一目均衡表計算公式以及程式碼展示
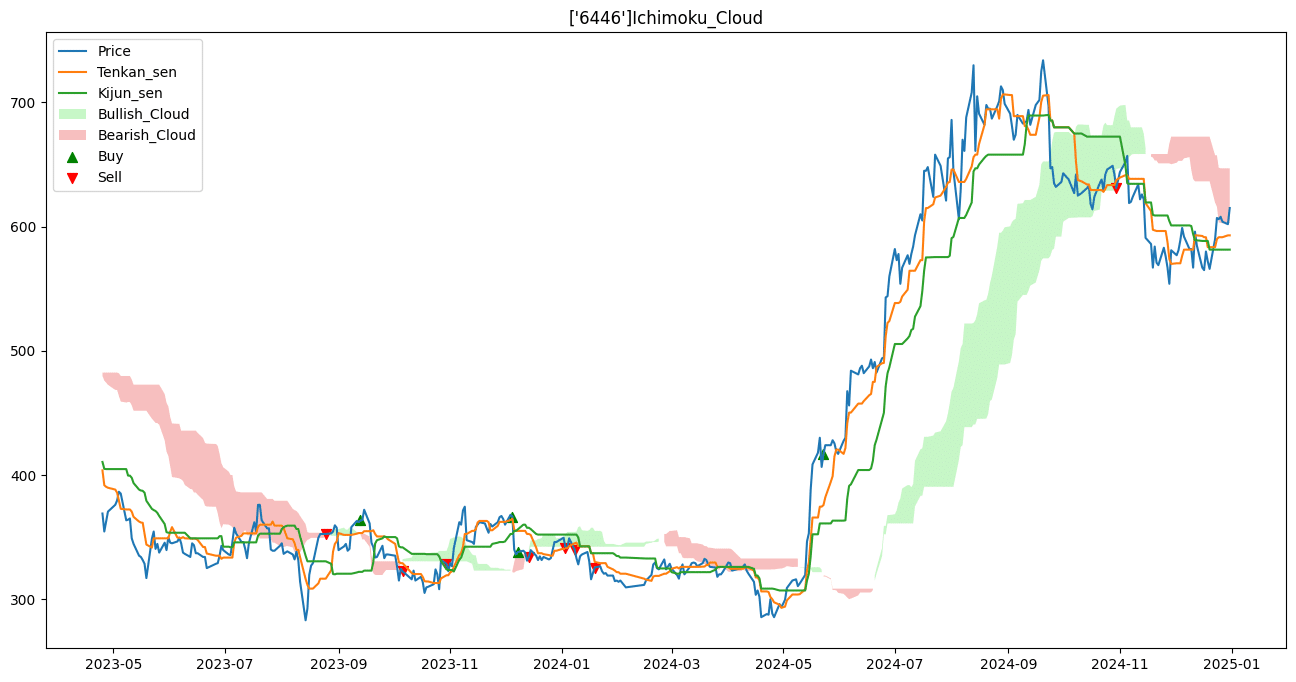
一目均衡表中有所謂的三役好轉與三役逆轉的判讀方法。三役好轉代表買進的訊號,三役逆轉則是賣出的訊號。通常在股價盤整區間外,若滿足三役好轉會有較強烈的上升趨勢,反之亦然。本文會根據三役好轉微調後進行買進訊號的產生。
三役好轉的條件:
三役逆轉的條件:
若出現三役好轉則設定為技術指標的買入信號,反之出現三役逆轉則為技術指標的賣出信號,後續會與機器學習模型的判斷信號做綜合信號判斷。
一目均衡表策略文章可以參考:點我進入
XGBoost(eXtreme Gradient Boosting) 是一種基於 梯度提升決策樹(GBDT) 的機器學習演算法。它透過多棵弱決策樹(Decision Tree)逐步學習數據中的模式,最終形成一個強大的預測模型。XGBoost 以其高效能、可解釋性及優秀的泛化能力,在許多金融與量化交易領域中被廣泛應用。
本文會使用一目均衡表的資料以及基本的開高低收量等交易資料來訓練XGBoost模型,使模型能夠學習有效的投資信號,並期望能提升投資效能。首先,將資料分成訓練集以及測試集,訓練集為整體資料的80%測試集為20%。預測的目標是交易信號(設定為未來五天的漲幅若超過3%為買入信號,反之為賣出信號)。通過訓練模型,讓模型學習不同線型之間的數值與未來漲跌情況的關係,期望模型能夠找到資料中隱藏的規律,進而提升投資績效。
本文主要以單支股票 6446 藥華藥 為交易標的,進行資金比例的調整,期望能通過進出場的操作超越買入持有策略,達到更佳的績效結果。
本文主要分為五種交易邏輯,分別是 買入持有策略(作為其他策略的Benchmark)、一般策略(純粹一目均衡表策略)、以技術指標為主的混合策略、以機器學習模型為主的混合策略、機器學習模型策略。
根據上述的說明,從技術指標(一目均衡表)以及機器學習分別可以得到回測期間的買賣信號(有兩組信號)。
一般策略(純粹一目均衡表策略):根據技術指標(一目均衡表策略)進行買賣。第一次出現買進信號則買入50%的資金部位(為了不讓現金水位維持在低點,稀釋策略整體報酬率),之後每次出現買進信號就加倉20%的部位,反之就減倉20%的部位(通過後續信號來調整部位的大小)。同時在交易邏輯中設定了槓桿的使用限制(槓桿限制為100%),讓策略不要超出本金的部位(不開槓桿)以及不能做空股票。
機器學習模型策略:根據XGBoost 模型的輸出結果進行投資策略的買賣。下單的部位邏輯同一般策略(純粹一目均衡表策略)。
技術指標為主的混合策略:第一次出現技術指標的買進訊號則買入50%的資金部位(為了不讓現金水位維持在低點,稀釋策略整體報酬率)。之後每次下單邏輯都要進行雙重信號判斷,若技術指標信號出現買進,同時機器學習信號也出現買進則加倉30%的資金部位(兩種信號都出現買進,加強了投資人的信心,所以加倉較多的部位),若技術指標信號出現買進,但機器學習信號並未出現買進,則只加倉10%(投資人信心不足)。同樣在槓桿設定上不能開槓桿以及做空股票。
機器學習模型為主的混合策略:下單部位邏輯類似於 技術指標為主的混合策略,只是信號判定改成以機器學習信號為主。
def initialize(context, pools = pools):
set_slippage(slippage.VolumeShareSlippage(volume_limit=1, price_impact=0.01))
set_commission(commission.Custom_TW_Commission())
set_benchmark(symbol(pools[0]))
context.i = 0
context.state = np.nan
context.mix_state = np.nan
context.pools = pools
#set_long_only(on_error='log')
#set_max_leverage(1.5)
def handle_data_raw(context, data, api_data = df_test):
context.i += 1
backtest_date = data.current_dt.date()
today_data = api_data[api_data['日期'] == pd.Timestamp(backtest_date)]
context.state = today_data['Signal'].iloc[0]
portfolio_value = context.portfolio.portfolio_value
position_value = context.portfolio.positions_value
current_allocation = position_value / portfolio_value
print(f'回測股票{pool[0]},使用一般策略,回測日期:{backtest_date}, 持倉比例:{current_allocation:.2f}')
if context.state == "Buy":
if current_allocation == 0:
order_target_percent(symbol(pool[0]), 0.5)
elif current_allocation >= 0.95:
order_target_percent(symbol(pool[0]), 1.0)
elif current_allocation <= 0.95:
order_target_percent(symbol(pool[0]), min(current_allocation + 0.2, 1))
if context.state =="Sell":
if current_allocation <= 0.05:
order_target_percent(symbol(pool[0]), 0)
else:
order_target_percent(symbol(pool[0]), max(current_allocation - 0.2, -1))
if context.state == np.nan:
if current_allocation > 1.0:
order_target_percent(symbol(pool[0]), 1.0)
if current_allocation < 0:
order_target_percent(symbol(pool[0]), 0)
def handle_data_mix(context, data, api_data = df_test):
context.i += 1
backtest_date = data.current_dt.date()
today_data = api_data[api_data['日期'] == pd.Timestamp(backtest_date)]
context.state = today_data['Signal'].iloc[0]
context.mix_state = today_data['Predicted_Signal'].iloc[0]
portfolio_value = context.portfolio.portfolio_value
position_value = context.portfolio.positions_value
current_allocation = position_value / portfolio_value
print(f'回測股票{pool[0]},使用混合策略(技術指標為主),回測日期:{backtest_date}, 持倉比例:{current_allocation:.2f}')
if context.state == "Buy":
if current_allocation == 0:
order_target_percent(symbol(pool[0]), 0.5)
elif current_allocation >= 0.95:
order_target_percent(symbol(pool[0]), 1.0)
elif context.mix_state == 1:
order_target_percent(symbol(pool[0]), min(current_allocation + 0.3, 1.0))
else:
order_target_percent(symbol(pool[0]), min(current_allocation + 0.1, 1.0))
if context.state =="Sell":
if current_allocation <= 0.05:
order_target_percent(symbol(pool[0]), 0)
elif context.mix_state == 2:
order_target_percent(symbol(pool[0]), max(current_allocation - 0.3, 0))
else:
order_target_percent(symbol(pool[0]), max(current_allocation - 0.1, 0))
if context.state == np.nan:
if current_allocation > 1.0:
order_target_percent(symbol(pool[0]), 1.0)
if current_allocation < 0:
order_target_percent(symbol(pool[0]), 0)
def handle_data_ml(context, data, api_data = df_test):
context.i += 1
backtest_date = data.current_dt.date()
today_data = api_data[api_data['日期'] == pd.Timestamp(backtest_date)]
context.mix_state = today_data['Predicted_Signal'].iloc[0]
portfolio_value = context.portfolio.portfolio_value
position_value = context.portfolio.positions_value
current_allocation = position_value / portfolio_value
print(f'回測股票{pool[0]},使用機器學習策略 XGBoost,回測日期:{backtest_date}, 持倉比例:{current_allocation:.2f}')
if context.mix_state == 1:
if current_allocation == 0:
order_target_percent(symbol(pool[0]), 0.5)
if current_allocation > 0.95:
order_target_percent(symbol(pool[0]), 1.0)
if current_allocation <= 0.95:
order_target_percent(symbol(pool[0]), min(current_allocation + 0.2, 1.0)) # 增加部位但不超過 100%
if context.mix_state == 2:
if current_allocation <= 0.05:
order_target_percent(symbol(pool[0]), 0)
else:
order_target_percent(symbol(pool[0]), max(current_allocation - 0.2, -1.0)) # 限制最大空頭部位為 -100%
if context.mix_state == 0:
if current_allocation >= 1.0:
order_target_percent(symbol(pool[0]), 1.0)
if current_allocation <= 0:
order_target_percent(symbol(pool[0]), 0)
def handle_data_mix_2(context, data, api_data = df_test):
context.i += 1
backtest_date = data.current_dt.date()
today_data = api_data[api_data['日期'] == pd.Timestamp(backtest_date)]
context.state = today_data['Signal'].iloc[0]
context.mix_state = today_data['Predicted_Signal'].iloc[0]
portfolio_value = context.portfolio.portfolio_value
position_value = context.portfolio.positions_value
current_allocation = position_value / portfolio_value
print(f'回測股票{pool[0]},使用混合策略(機器學習為主體),回測日期:{backtest_date}, 持倉比例:{current_allocation:.2f}')
if context.mix_state == 1:
if current_allocation == 0:
order_target_percent(symbol(pool[0]), 0.5)
elif current_allocation >= 0.95:
order_target_percent(symbol(pool[0]), 1.0)
elif context.state == 'Buy':
order_target_percent(symbol(pool[0]), min(current_allocation + 0.3, 1.0))
else:
order_target_percent(symbol(pool[0]), min(current_allocation + 0.1, 1.0))
if context.mix_state == 2:
if current_allocation <= 0.05:
order_target_percent(symbol(pool[0]), 0)
elif context.state == 'Sell':
order_target_percent(symbol(pool[0]), max(current_allocation - 0.3, 0))
else:
order_target_percent(symbol(pool[0]), max(current_allocation - 0.1, 0))
if context.mix_state == 0:
if current_allocation >= 1.0:
order_target_percent(symbol(pool[0]), 1.0)
if current_allocation < 0:
order_target_percent(symbol(pool[0]), -1.0)
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import classification_report
data_ml = df[:].copy()
# 設定交易信號:如果未來 5 天內價格上漲 3%,則標記為 'Buy'
data_ml['Target'] = np.where(data_ml['收盤價'].shift(-5) > data_ml['收盤價'] * 1.03, 'Buy',
np.where(data_ml['收盤價'].shift(-5) < data_ml['收盤價'] * 0.97, 'Sell', 'Hold'))
# 把 'Buy'、'Sell'、'Hold' 轉成數字(0, 1, 2)
data_ml['Target'] = data_ml['Target'].map({'Buy': 1, 'Sell': 2, 'Hold': 0})
# 1. 資料讀取與前處理
data_ml = data_ml.set_index('日期', drop = False)
# 若想預測隔天收盤價,可以將目標設為收盤價向前平移一個交易日
data_ml['目標收盤價'] = data_ml['收盤價'].shift(-1)
# 2. 特徵與目標設定
# 這裡僅用最基本的價格與成交量作為特徵,你也可以加入其他技術指標(例如 MA、RSI 等)
features = ['開盤價', '最高價', '最低價', '收盤價', '成交量_千股']
features2 = ['Tenkan_sen','Kijun_sen', 'Senkou_Span_A', 'Senkou_Span_B','Chikou_Span', '收盤價', '成交量_千股','開盤價', '最高價', '最低價']
X = data_ml[features2]
y = data_ml['Target']
# 3. 資料切分(依時間順序切分,不建議隨機切分)
# 切分時間點為 2021-03-04
split_index = int(len(data_ml) * 0.8)
X_train, X_test = X.iloc[52:split_index], X.iloc[split_index:-1]
y_train, y_test = y.iloc[52:split_index], y.iloc[split_index:-1]
dates_test = data_ml['日期'].iloc[split_index:-1] # 用於後續繪圖
model = xgb.XGBClassifier(
n_estimators=500, # 樹的數量
max_depth=5, # 控制樹的深度,防止過擬合
learning_rate=0.05, # 設定學習率
subsample=0.8, # 使用 80% 數據訓練每棵樹,提高泛化能力
colsample_bytree=0.8, # 降低過擬合風險
random_state=42,
use_label_encoder=False, # 避免 warning
eval_metric="mlogloss" # 適合多類別分類
)
# 訓練 XGBoost 模型
model.fit(X_train, y_train)
# 進行預測
y_pred = model.predict(X_test)
import matplotlib.pyplot as plt
import matplotlib
import matplotlib.font_manager as fm
!wget -O MicrosoftJhengHei.ttf https://github.com/a7532ariel/ms-web/raw/master/Microsoft-JhengHei.ttf
!wget -O ArialUnicodeMS.ttf https://github.com/texttechnologylab/DHd2019BoA/raw/master/fonts/Arial%20Unicode%20MS.TTF
fm.fontManager.addfont('MicrosoftJhengHei.ttf')
matplotlib.rc('font', family='Microsoft Jheng Hei')
matplotlib.font_manager.fontManager.addfont('ArialUnicodeMS.ttf')
matplotlib.rc('font', family='Arial Unicode MS')
# 產生分類報告
print(classification_report(y_test, y_pred))
# 繪製特徵重要性圖
xgb.plot_importance(model)
plt.show()
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# 計算混淆矩陣
cm = confusion_matrix(y_test, y_pred)
# 顯示混淆矩陣
disp = ConfusionMatrixDisplay(confusion_matrix=cm)
disp.plot()
plt.show()
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
df_test = df.iloc[split_index:-1].copy() # 取得測試集的對應資料
df_test['日期'] = pd.to_datetime(df_test['日期'])
df_test = df_test.set_index('日期', drop = False)
df_test['Predicted_Signal'] = y_pred # 新增預測結果
df_test['Predicted_Signal'].plot(figsize = (12, 8))
df_test['Predicted_Signal'].value_counts()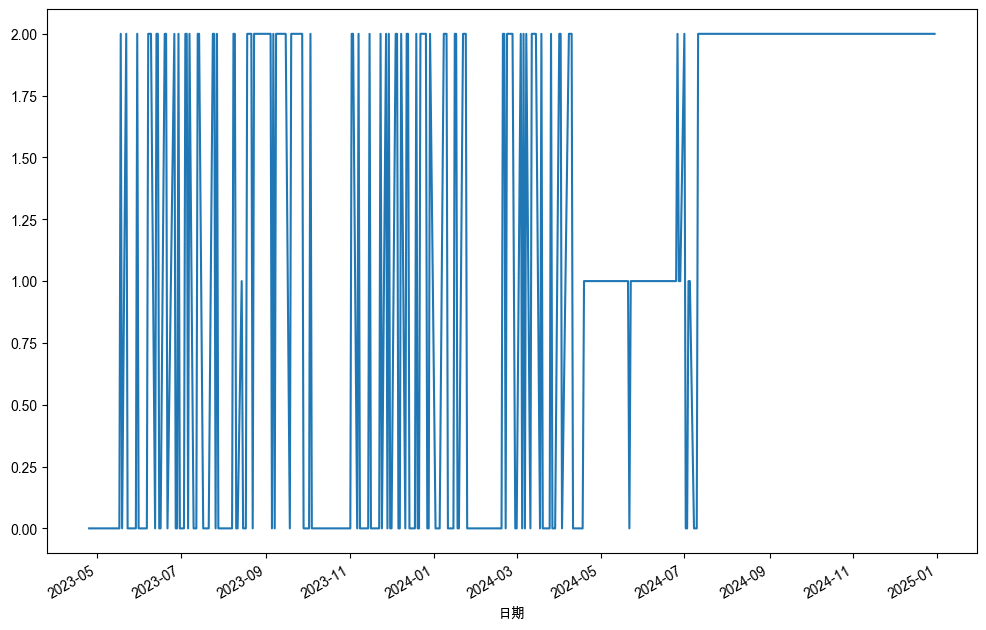
從圖表可以得出,機器學習模型的信號產生容易出現反覆不定的現象,因此初步預測完全按照機器學習模型的信號下單會容易付出較高的交易成本。而其中可以看到2024-09之後的預測信號皆為 Sell 賣出信號,關於這個現象我會在後續做討論。
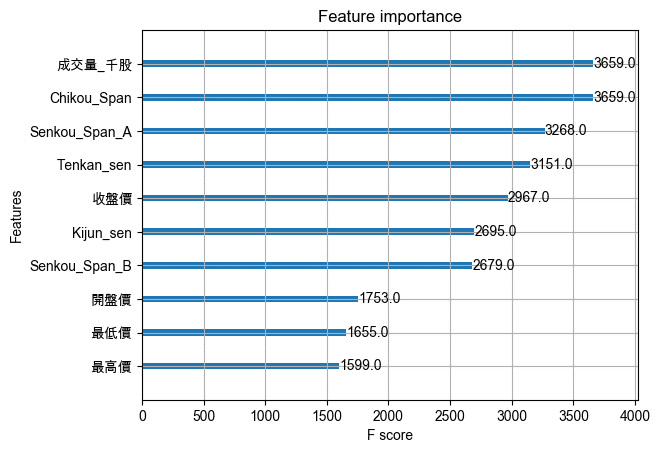
此圖為XGBoost 模型在訓練時,用得的資料次數,被使用的次數越多被認為是越重要的資料特徵。從結果來看,排在靠前的資料特徵主要都是技術指標的資料,表示相比於只使用基本的開高低收量資料,新增這些資料特徵有助於模型的預測效能提升。
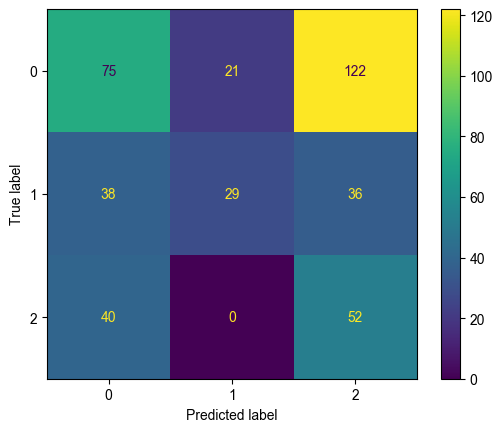
此圖為XGBoost 圖表的預測方格圖,X軸為模型預測的信號 Y軸為測試集中實際的信號,數值表示被分到這些類別的次數。圖中比較重要的格子是(Predicted Lable = 1, True Label = 2,簡稱(1, 2))(Predicted Label = 2, True Label = 1,簡稱(2, 1))這兩格,這兩格表示預測值與實際值完全相反的情況。先從(1, 2)這格開始,這格表示實際是需要賣出但被模型預測為買進的狀況,數值顯示這種情況出現次數為 0 次,所以模型較不會出現這種誤判情形。另外一格則為(2, 1),表示為實際需要買入但模型預測要賣出,這種情況出現了 36 次,但是在交易邏輯上有限制不能賣空,因此即便是預測錯誤而沒跟到漲幅,頂多只會是減少倉位或是不持倉,並不會造成虧損。
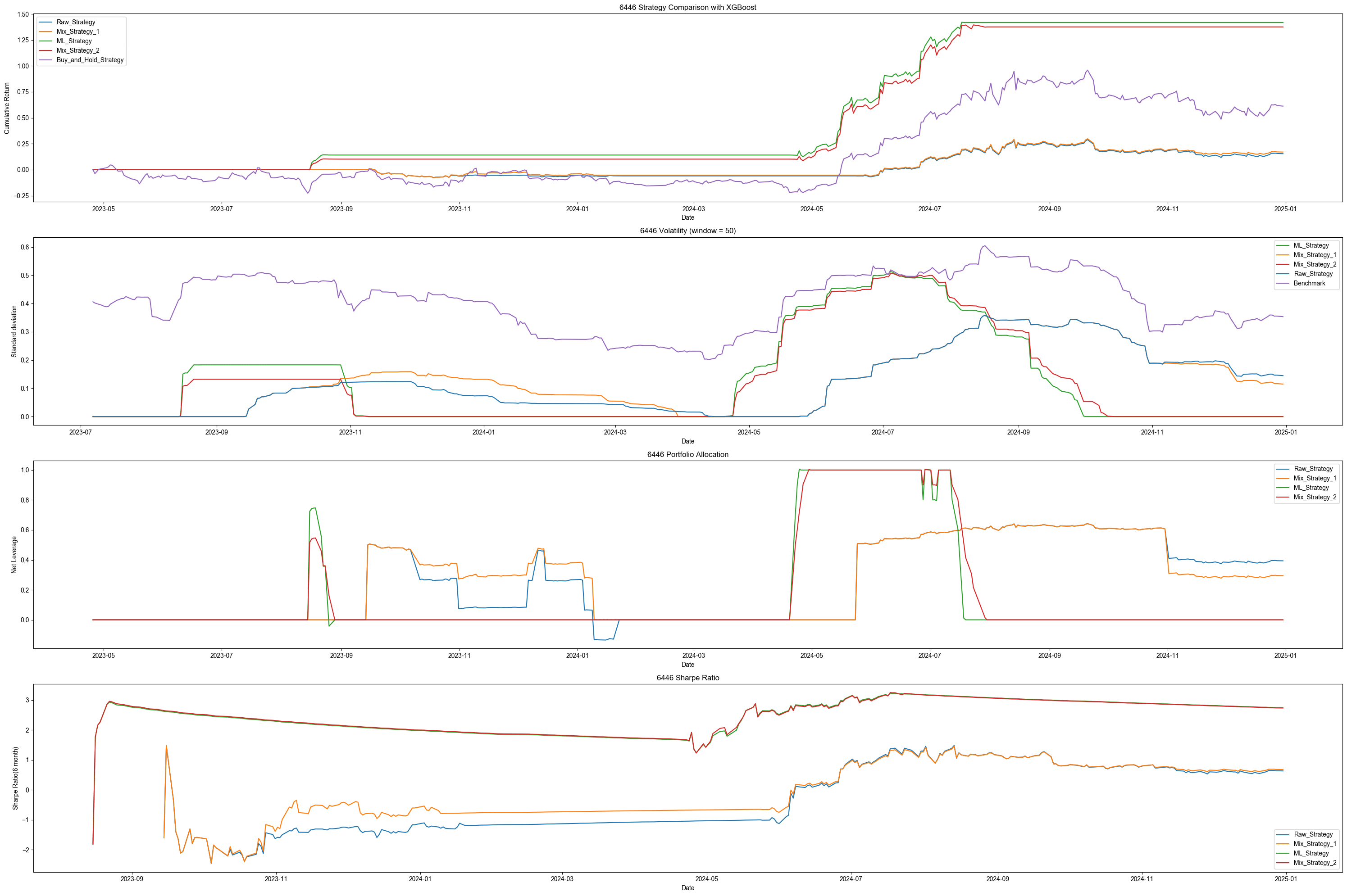
第一張圖表為累積報酬率圖表,從最終的累積報酬率來看 Benchmark (Buy and Hold Strategy)的累積報酬率為 61.24%, 而純粹技術指標策略(Raw Strategy)的累積報酬率為 15.44% ,明顯贏不了買入持有策略。
再來觀察剩餘的策略,首先是以技術指標為主的混合策略(Mix Strategy 1)的累積報酬率為17%,略微優於 Raw Strategy 。因此我認為這個策略因為機器學習的算法強化了下單的信心從而提升了些微的報酬率,顯示出機器學習算法在策略的優化確實產生作用。
最後兩個策略,分別是機器學習策略(ML Startegy)以及以機器學習為主的混合策略,可以看得出來機器學習產生的買賣信號相比於技術指標來得出色很多,反映在報酬率的數值上,分別是141.81%以及137.52%。顯示出XGBoost 算法對於該股票的價格資料有很好的訓練結果,使得投資績效大幅超越 Benchmark。
接著我們觀察資金使用比率(第三張圖),因為我們在下單條件中間入了槓桿限制的條件,所以四種策略都沒有出現使用槓桿的情形。值得注意的是該股票在2024-04 至2024-07的這段期間是股價上升期,而機器學習為主的兩種策略,他們建倉的時間點相對於技術指標為主的兩個策略來得更早,這會是機器學習算法能夠更早預測未來漲幅的證據之一,為策略的有效性提供可信度。
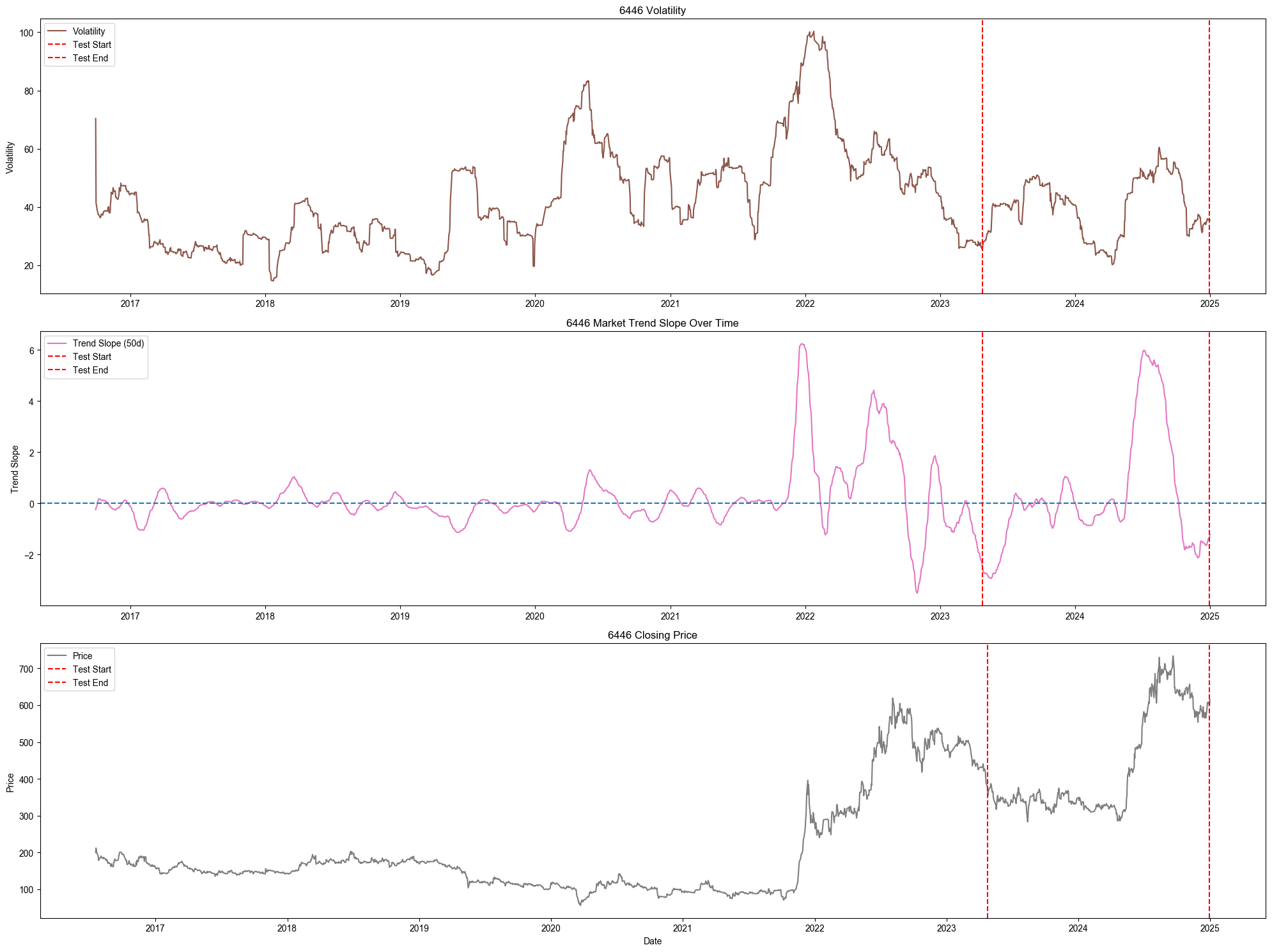
此圖為 6446 個股的交易資料,包含回測期間以及訓練模型期間。第一圖是股票的移動波動度能夠查看股票的波動情形。從波動度圖來看,測試集的波動度和訓練及的波動度並沒有太大的結構變化。從第二張圖 50 日均線斜率 (Trend Slope)觀察,短期趨勢的數值也沒有突破訓練集的最高點過多,而是在一定的區間做震盪。但是從第三張圖 (價格圖)來觀察,股價在測試集中突破了訓練集的最高價,這會使得測試集出現機器學習模型沒有在訓練集中學習過的狀況,進而做出較不合理的信號產生。這也是前面的信號圖表在測試集的最後都只輸出賣出信號,因為這是模型沒學習過的狀況。這也是只使用機器學習模型進行信號判斷會出現的誤區,因此會希望搭配技術指標或是其餘的分析,進行綜合性的策略下單判斷。
本文章目前只使用了單支個股進行策略有效性的討論研究,但對於其他個股或產業是否會有相同的結果,還需要後續進行分析以及研究。同時對於股價在測試集中出現突破歷史最高價的情況,認為後續可以進行警界線的設計,表示說目前的股價水準已經不太適用該模型行預測。可能會需要在警戒線觸發時,進行模型以及策略邏輯的更換,以減少投資風險。
未來研究方向,讀者可以嘗試訓練更多其他屬性的資料,例如將不同屬性的資料特徵(波動度、50 日均線斜率、其他技術指標),期望這些新的資料特徵能夠讓模型捕捉股價更加高維的規律以及變化。
歡迎投資朋友參考,之後也會持續介紹使用 TEJ 資料庫來建構各式指標,並回測指標績效,所以歡迎對各種交易回測有興趣的讀者,選購 TQuant Lab 的相關方案,用高品質的資料庫,建構出適合自己的交易策略。
溫馨提醒,本次分析僅供參考,不代表任何商品或投資上的建議。
完整程式碼連結:程式碼連結
TQuant Lab 一目均衡表策略,一套自成體系的技術分析指標
